Significant progress has been made in the field of generative artificial intelligence and large language models (LLMs), which possess remarkable capabilities and the potential to fundamentally transform many domains. Thanks to the open source movement, we are witnessing an increasing number of models being developed and infrastructures being built to create and serve them. Moreover, developers have the opportunity to contribute to datasets, models, and system infrastructures.
As it stands, the majority of these models necessitate the deployment of powerful servers to accommodate their extensive computational, memory, and hardware acceleration requirements. Nevertheless, the implications of the burgeoning AI era on consumer devices, such as laptops, phones, and game consoles, remain uncertain. Will these devices possess the capacity to independently run these models, or will they rely on uninterrupted connectivity to cloud servers? The resolution of this quandary is poised to significantly the attainability and pervasiveness of AI-powered devices.
While speculation at this point is undoubtedly challenging, it is nonetheless intriguing to contemplate the various possibilities. Drawing inspiration from the pre-PC era, recall the famous prediction that a mere six large computers hidden in research laboratories would suffice to meet the country’s computational requirements, which as we now know, was vastly incorrect. Thus, it is both prudent and exhilarating to contemplate the possibilities and unforeseen advancements that the future may hold. Nevertheless, generalize from this data point, we may postulate the likelihood of LLMs migrating to consumer devices, and potentially shape the future AI ecosystem.
Potential Opportunities of LLMs on Consumer Devices
There is a great amount of opportunities to bring LLMs to consumer devices. Here is a possibly incomplete list of some possible futures.
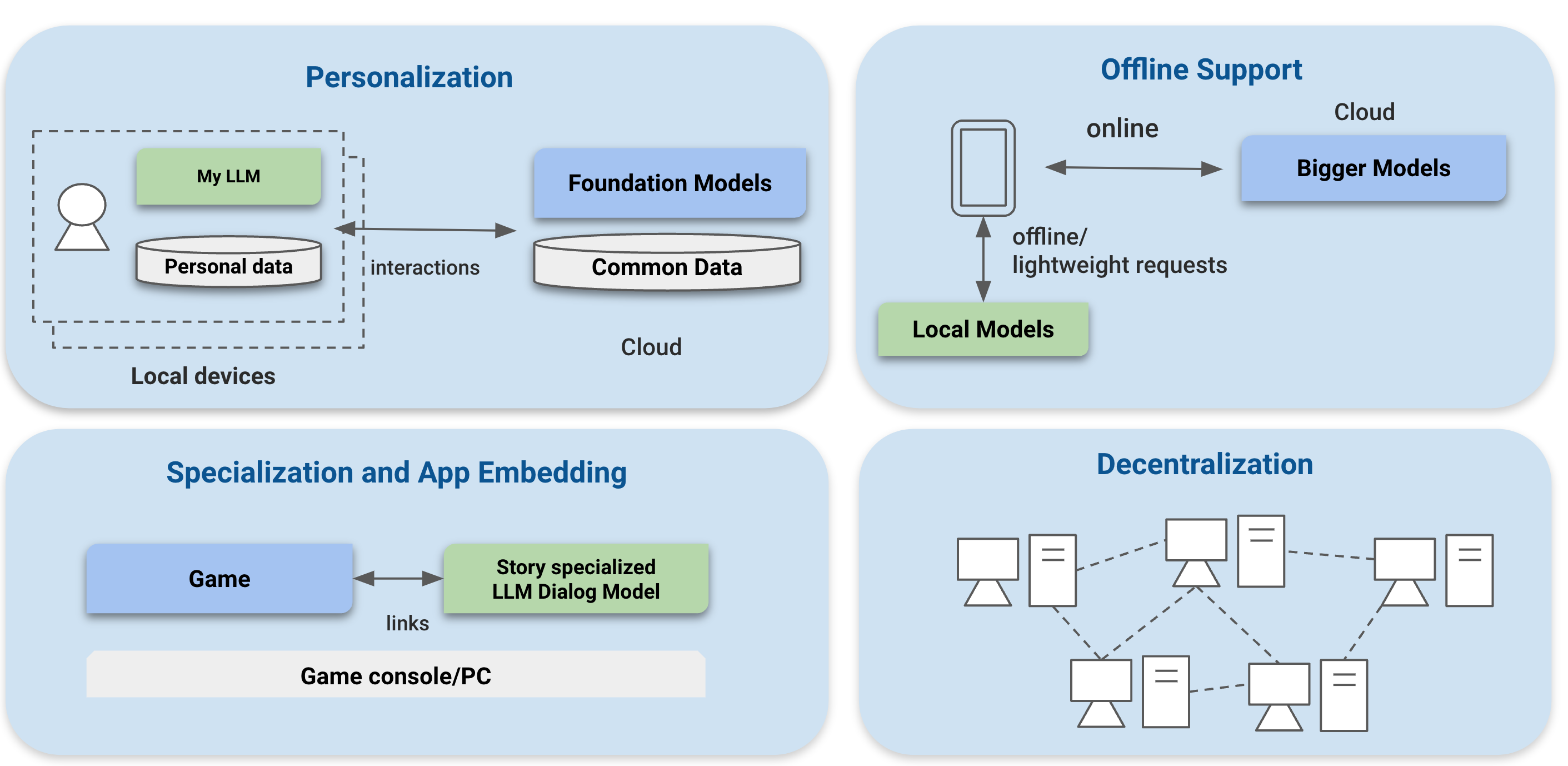
Personalization. Smart language models knows a lot of things, on the other way, they do not necessarily know our favorite songs or writing styles yet. In one possible future, some might like to have a personally AI companion. These models may not be the smartest, but they knows ourselves and can be used to amplify our daily workflow. They can also be made to work along with the more powerful models on the server to create even more amplified experience. They can also come in the form as adapters build on top of open-powerful models. To create such personalized AI however, we would need to feed personal data to the model, ideally run them on our own consumer devices.
Specialization and application integration. Language models can do a lot of things, there are domains however that maybe we only need a bit more trimmed down version of it. It won’t be surprising to see future games to leverage some variant of those models to generate unique experience for each play. Specializing to game dialogs is one example on how existing applications benefit from integrating LLMs. Having specialized models that run directly on the game console could create quite a bit of fun opportunities.
Offline support and client server hybrid use-cases. We are not all the time connected to the internet. It would still be great to have some of the less powerful but still smart AI assistant to help us when we have gone offline, during a flight or wondering into a place where internet is not easily accessible. In another case, it would also be good to have different AI components to work together, offloading part of the compute locally and collaborate with the models that runs on the cloud. Or working with a service that seamlessly moves the compute among the two, depending on the environment we are in.
Decentralization. Finally, there is an interesting future of decentralization. While the compute of each individual consumer devices might be less powerful than those on the datacenter, consumer devices can do a lot of powerful things when connected together. There are quite a few interesting movements in the decentralization AI space and would be interesting to see what they can enable when given the right tooling support.
Challenges to Deploy LLMs to Consumer Hardware
The ideas discussed are all (possible) incoming futures. Besides talking about them, it would be even more interesting to ask how can we enable some of the possible futures. Specifically, can we make our contribution to the open source community to push the following goal:
Enable everyone to develop, optimize and deploy AI models natively on everywhere — including server environments and consumer devices.
Let us start with one key elements here — hardware acceleration. Large models are compute hungry and have a good amount of memory demand. It is important to leverage hardware acceleration to really bring some of the big models onto consumer devices. The good news is that if we can play games on a consumer device, likely we already get the necessary hardware — a GPU, to accelerate the AI workload of interest. Additionally, there are also increasing amount of specialized hardware support for accelerating ML workloads. Of course, there is also a great deal of challenges here
Diversity of hardware and software stack Consumer devices comes with great deal with diversity. To name a few, many of the desktops may come with Nvidia, AMD, or Intel GPU, each have their own software stack. Game consoles like steam-deck comes with APU. Laptops also can come with integrated GPU of several kinds, from AMD, intel and apple. The mobile space have brings a great deal of diversity. Of course if we are talking about web apps, there is a need for GPU acceleration in the web. There are also different ways to programs a subset of these hardwares on different kinds of platforms The list includes CUDA, Rocm, Metal, OpenCL, SYCL, Direct3D, Vulkan/SPIRV, WebGPU.
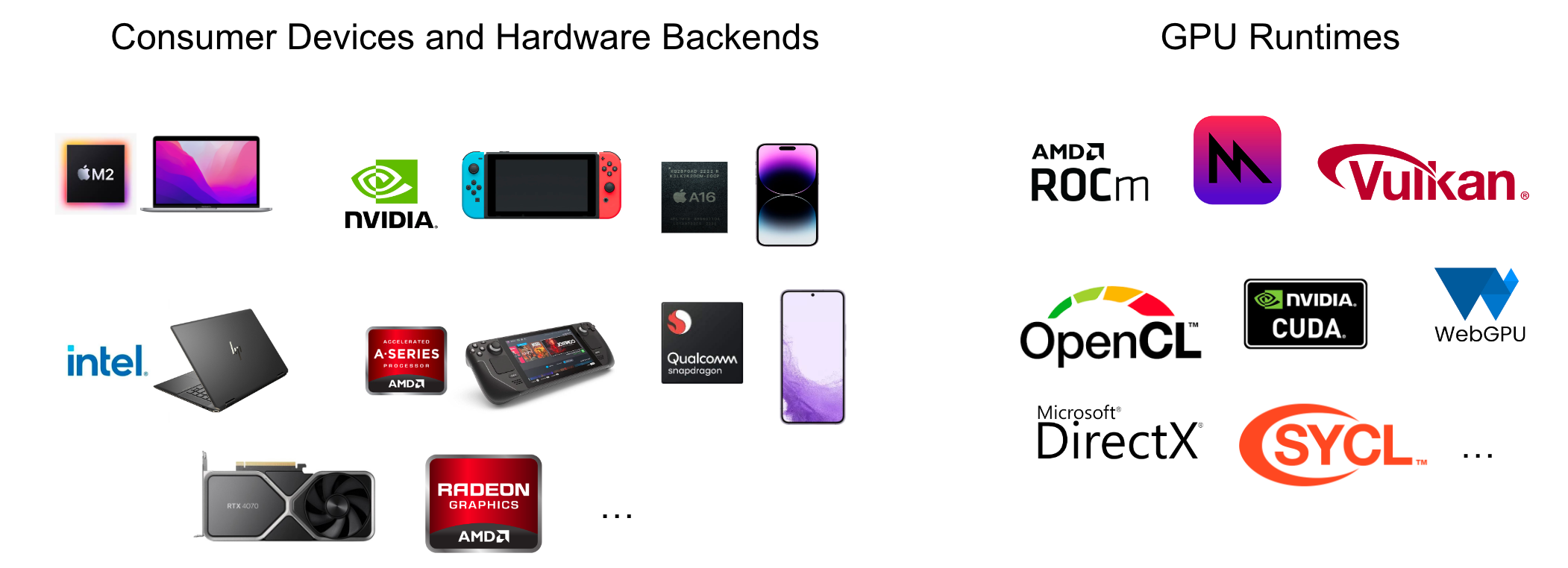
Continuous demand of machine learning system development The pace of open source machine learning community is amazing with new model variants being trained. We also see continuous innovation in the machine learning systems research field, which brings in novel approach that combines model optimizations with improving system support that needs to be incorporated into the solution. It is not only about build one perfect solution, but continuously improving the system to support the latest innovations from the machine learning and systems community.
Machine Learning Compilation Can Help
Machine learning compilation (MLC) is an emerging approach that aims to close the gaps here. Instead of directly relying on hand optimization for each platform and writing GPU shader to bring hardware accelerations from each kind, which would be engineering intensive. We can take our ML model as a program, and transform in multiple steps towards the desired form in the target platform.
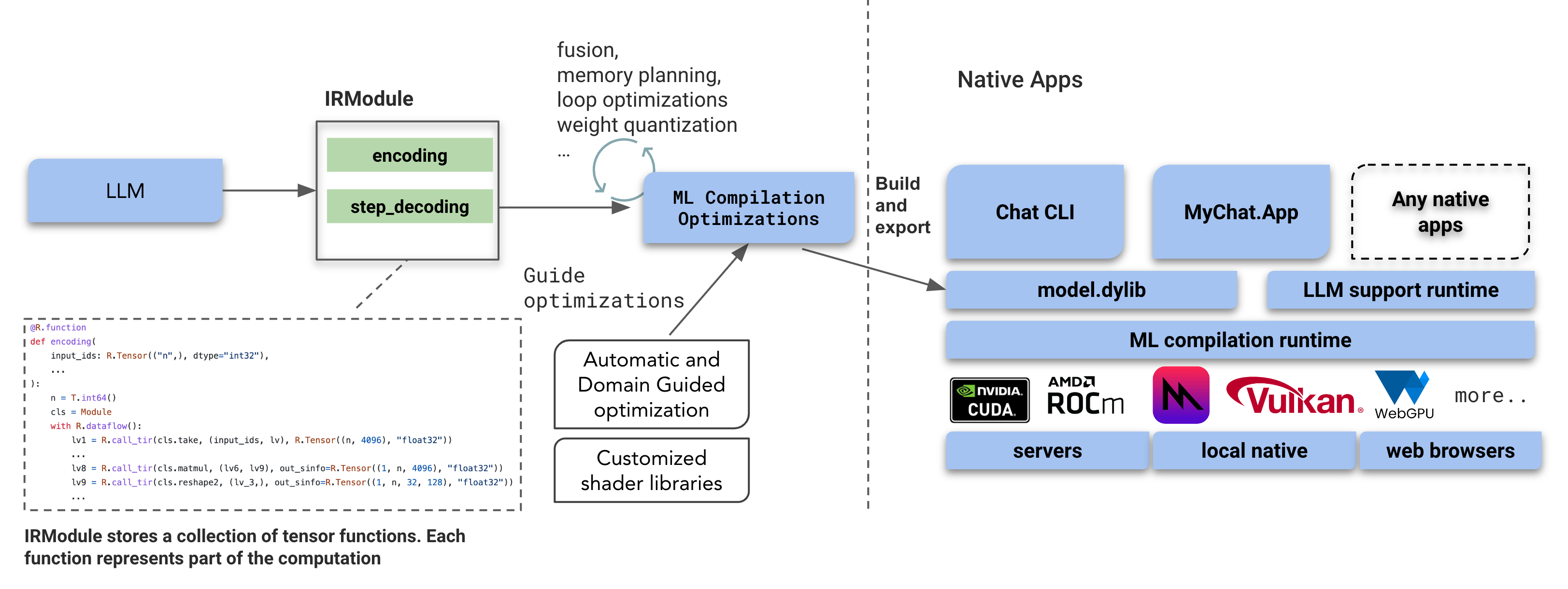
The above figure shows an example typical machine learning compilation flow. The model’s overall execution logic is being captured in a container call IRModule, which contains a collection of functions that represents different kinds of computations, such as encoding and single step decoding of the LLM inference.
Then we can take an IRModule and pragmatically transform part of the program in a few steps:
- In some cases, we can replace certain operators(such as attention) by faster implementations from library or a code generators.
- In some other cases, we need to carefully plan the memory sharing among layers whose computation do not overlap with each other to reduce the memory consumption.
- To get the maximum performance, it is also important to fuse operators together, so we don’t have to pay the round tripping cost to the global hardware memory.
- Finally there are techniques that allows us to automatically transform and generate the kernel code to the target platform of interest such as metal, cuda, rocm or vulkan.
The main advantage of the MLC approach is that we can build the IRModule usually once and get a targeted pipeline (e.g. the same solution generates WGSL for Web and SPIRV for native devices). It also offers opportunities to do some transformations globally, such as systematically planning the memory usage of the execution so that we can fit large models into the memory budget. Importantly, MLC is not an exclusive approach. Instead, it can be used as a methodology that amplifies and complements other engineering approaches such as kernel performance optimization. To that end, we can mix some of the approaches together, for example, leveraging the accelerated libraries when they are available, while using code generation to cover rest part of the model.
Developing machine learning system solution using the MLC approach, along with other complementary methods can greatly amplifies our productivity. As we can leverage the automated part of the pipeline when possible and focus energy on customizing some of the bottleneck parts. There are a lot of exciting open source developments in ML compilation lately, including PyTorch 2.0, OpenXLA/MLIR and Apache TVM unity among others. MLC as a methodology can help a lot of our daily use-cases.
As MLC gets into our daily pipeline, we also see a great demand to enable more people to develop and collaborate on ML compilation pipeline together and bring the latest innovations from model development together with optimization developments. The power of open source community and python-first development experiences helped the ML community to thrive with new model developments, we believe doing the same (enabling MLC flow development and hacking in python) would give more people ability to contribute and use this methodology and combine their innovations. We also built a course about ML compilation to introduce the general concepts.
ML Compilation for Language Models
As part of the machine learning compilation community, we would love to help more people to leverage the related technology and amplify their machine learning engineering. We believe one approach to do so is to use the methodology to build up ready to use solutions for the problem of LLM deployment. That is why we build MLC-LLM, a universal solution that takes the ML compilation approach and brings LLMs onto diverse set of consumer devices. The same solution also is applicable to mobile and server use cases as well.
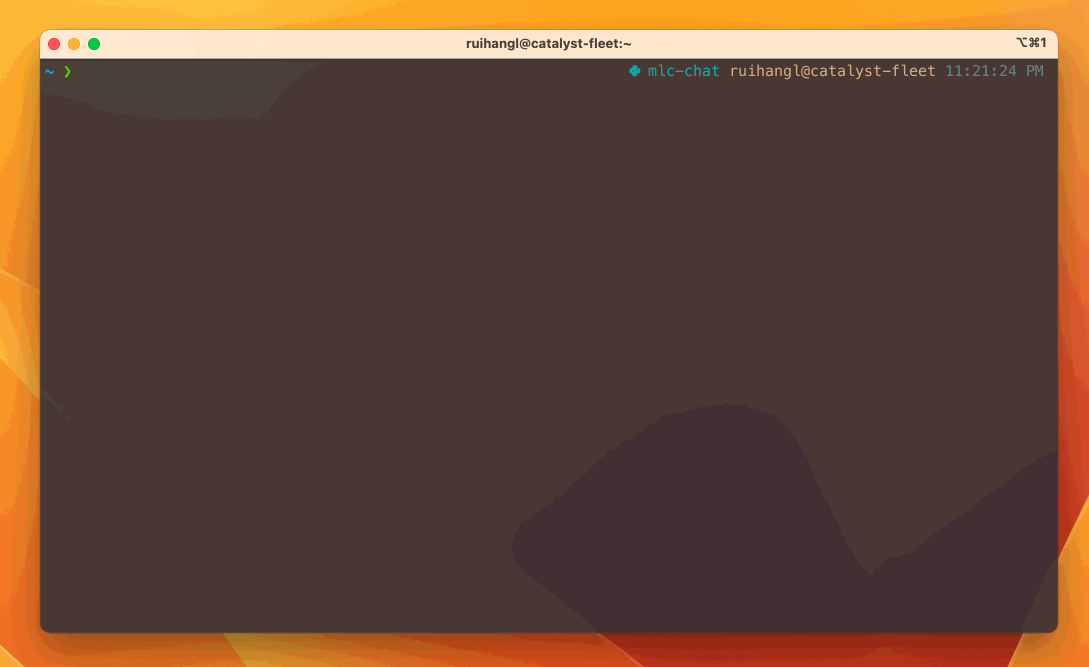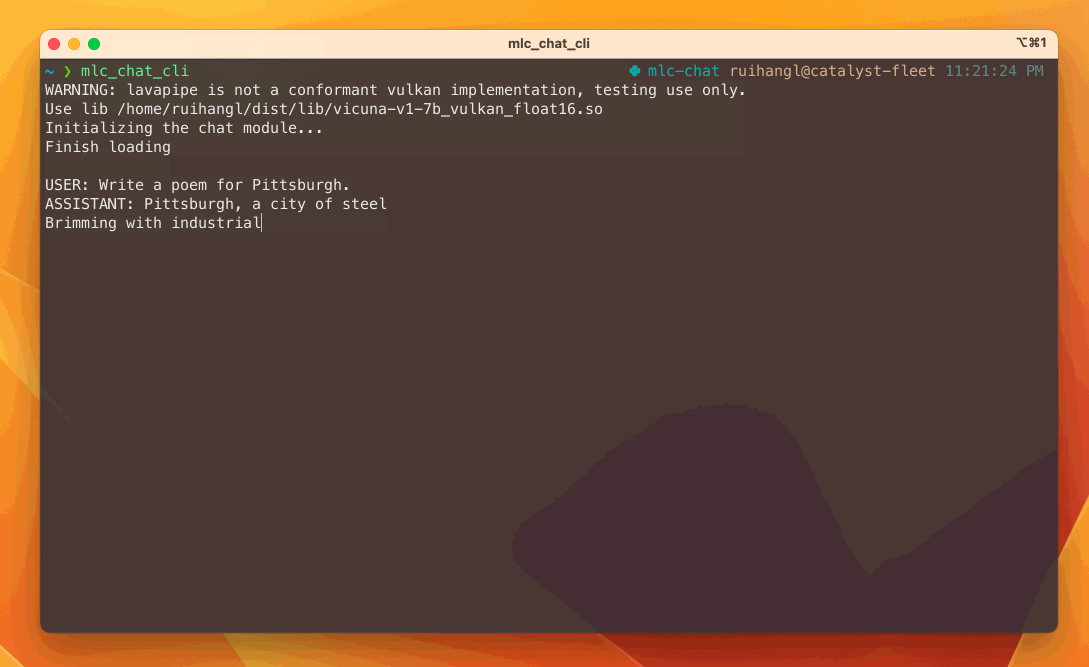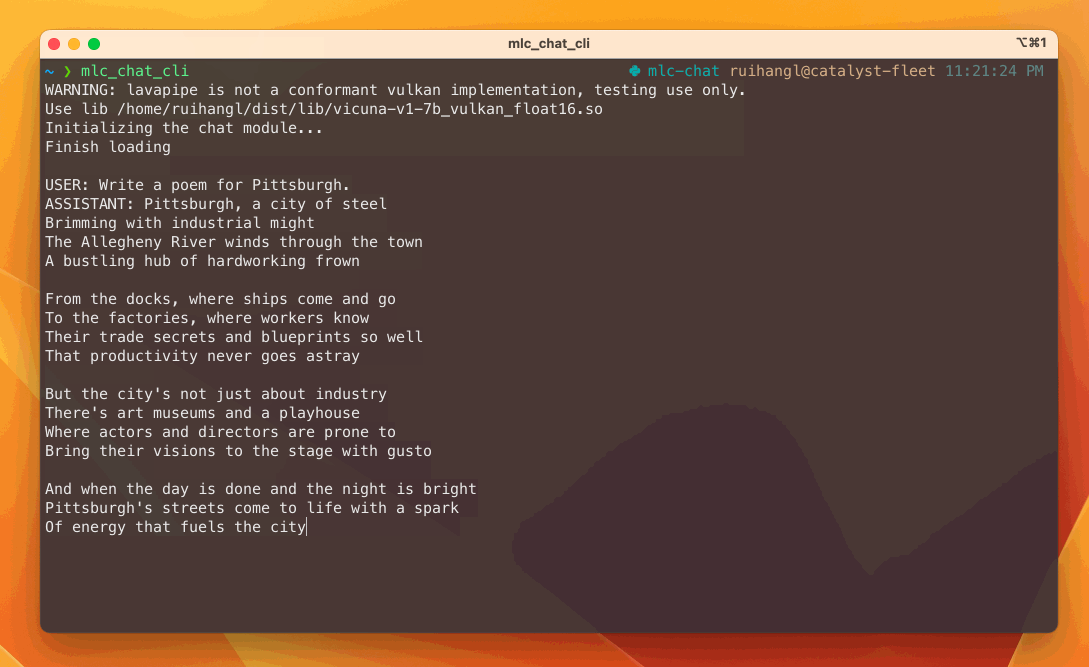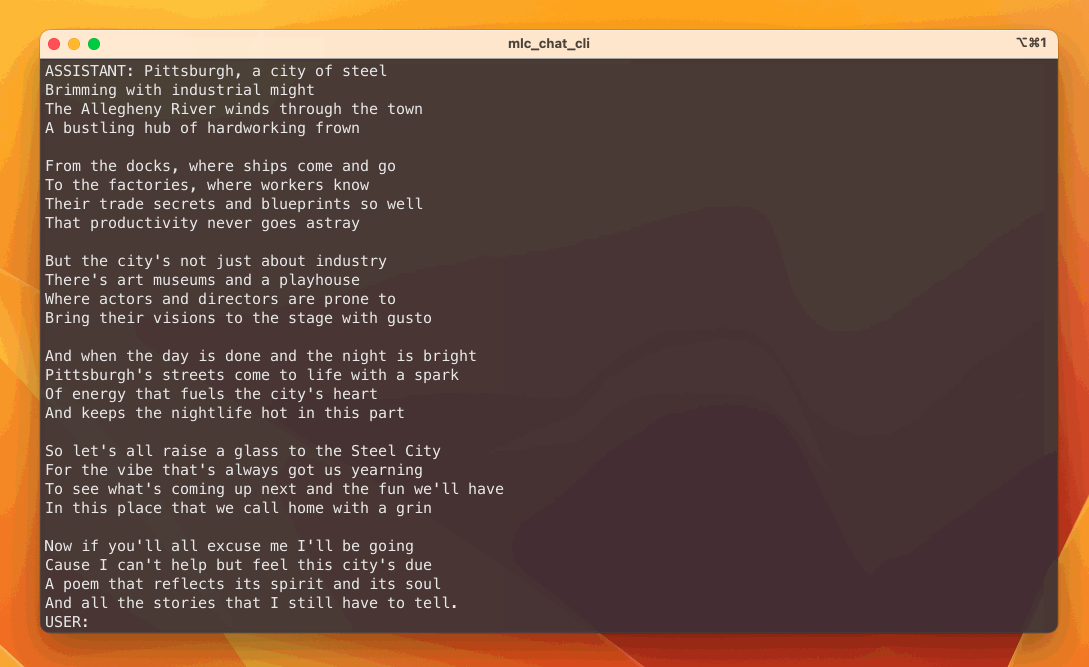
To make our final model accelerated and broadly accessible, the solution maps the LLM models to vulkan API and metal, which covers the majority of consumer platforms including windows, linux and macOS. You can checkout the instruction website to try out the CLI demo on these platforms. The amazing thing about this approach is that it helps us to run on AMD GPUs and devices like a steam deck.
The same solution can be applied to enable mobile devices support such as iOS. You can checkout the test flight page to try out out mobile apps. We can further expand the support to enable other mobile devices as well. You can checkout the instruction here to try out the iphone demo.
Finally, thanks to WebGPU, we can offload those language models directly onto web browsers. WebLLM is a companion project that leverages the ML compilation to bring these models onto browsers. You can also try it out with the given link. The advances of AI also contains other exciting models, and ML compilation can help as well. Web Stable Diffusion is an example of running diffusion models on the consumer environments through a browser.
As part of the open source community, one thing we realize is that the biggest strength lies in the community. MLC-LLM is also built as a hackable python flow that enables more people to productively develop and optimize performance of their own model and hardware use-cases. Checkout the Github repo to get a sense of the overall flow. We will also release more tutorials in the future to talk about the techniques like memory planning optimization and operator fusion and how do they related to our end use cases.
Summary and Looking Beyond
In this post, we have brainstormed the possible futures of hardware accelerated LLMs on consumer devices. With the amazing power of open source community, a lot of them are turning reality. Machine learning compilation will be one of the methodologies that enables these exciting futures and hopefully mlc-llm and other projects can bring part of the contributions along with the overall ML ecosystem.
Of course, all of these results are only possible thanks to the shoulders open-source ecosystems that we stand on. MLC-LLM is built on top of Apache TVM community’s TVM unity effort. We also benefited a lot from open source ML community members that makes these open LLM models available. It really takes so many elements to build a real end to end LLM applications that can go into our games and other native apps. In the particular cases mentioned this post, we leveraged c++(runtime), python(ml compilation), swift(UI), rust(tokenizer), vulkan, metal and WebGPU, among other technologies, all part of the open source ecosystems. It is amazing to see how everything comes together. We would also love to continue contribute to this broader community and work with everyone to bring some of the futures together.
Acknowledgement
The MLC LLM project is initiated by members from CMU catalyst, UW SAMPL, SJTU, OctoML and the MLC community. We would love to continue developing and supporting the open-source ML community.
The overall MLC projects are only possible thanks to the shoulders open-source ecosystems that we stand on. We want to thank the Apache TVM community and developers of the TVM Unity effort. The open-source ML community members made these models publicly available. PyTorch and Hugging Face communities that make these models accessible. We would like to thank the teams behind Vicuna, SentencePiece, LLaMA, and Alpaca. We also would like to thank the Vulkan, Swift, C++, python Rust communities that enables this project.