The rapid proliferation of open-source Large Language Models (LLMs) has sparked a strong desire among diverse user groups to independently utilize their own models within local environments. This desire stems from the constant introduction of new LLM innovations, offering improved performance and a range of customizable options. Researchers, developers, companies and enthusiasts all seek the flexibility to deploy and fine-tune LLMs according to their specific needs. By running models locally, they can tap into the diverse capabilities of LLM architectures and effectively address various language processing tasks.
As the landscape of LLMs gets increasingly diverse, there have been different models under different license constraints. Driven by a desire to expand the range of available options and promote greater use cases of LLMs, latest movement has been focusing on introducing more permissive truly Open LLMs to cater both research and commercial interests, and several noteworthy examples include RedPajama, FastChat-T5, and Dolly.
Having closely observed the recent advancements, we are thrilled by not only the remarkable capabilities exhibited of these parameter-efficient models ranging from 3 billion to 7 billion in size, but also the exciting opportunity for end users to explore and leverage the power of personalized Open LLMs with fine-tuning at reasonable cost, making generative AI *accessible to everyone for a wide range of applications.
MLC LLM aims to help making Open LLMs accessible by making them possible and convenient to deploy on browsers, mobile devices, consumer-class GPUs and other platforms. It brings universal deployment of LLMs on AMD, NVIDIA, and Intel GPUs, Apple Silicon, iPhones, and Android phones.
This post describes our effort on streamlining the deployment of Open LLMs through a versatile machine learning compilation infrastructure. We bring RedPajama, a permissive open language model to WebGPU, iOS, GPUs, and various other platforms. Furthermore, the workflow we have established can be easily adapted to support a wide range of models with fine-tuned (personalized) weights, promoting flexibility and customization in LLM deployment.
Universal Deployment of RedPajama
RedPajama models exemplify how the open-source community can rapidly construct high-performing LLMs. RedPajama-3B is a small yet powerful model that brings the abilities for downstream users to fine-tune these models according to their specific needs, both aiming to empower individuals of diversified background to run Open LLMs with easy personalization. We love to support this same vision of bringing accessibility and personalization to fully realize potential of LLM technology within the broader community. As a result, we bring RedPajama support to a wide range of consumer devices with hardware acceleration.
RedPajama on Apple Silicon is achieved by compiling the LLM using Metal for M1/M2 GPUs (try out). Furthermore, MLC LLM provides a C API wrapper libmlc_llm.dylib that enables interaction with the generated Metal library. As an illustrative example, the command line tool mlc_chat_cli showcases the usage of libmlc_llm.dylib, which meanwhile also provides users with an interface to engage with RedPajama.
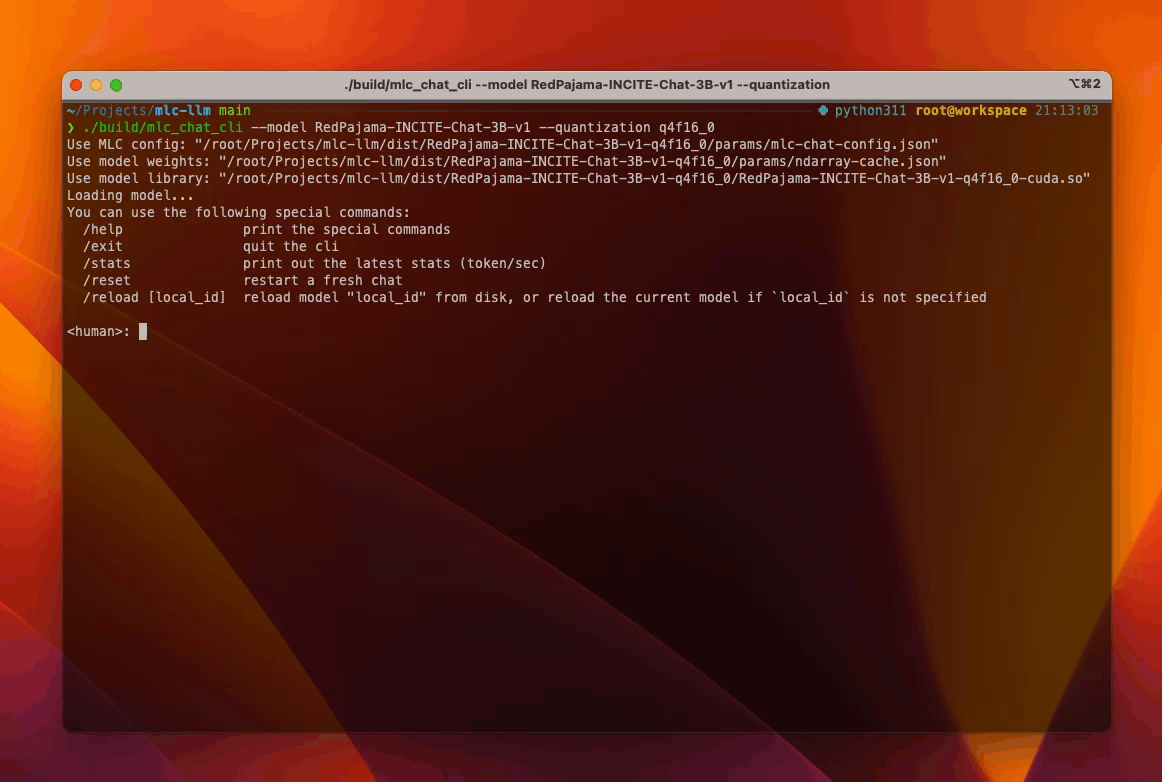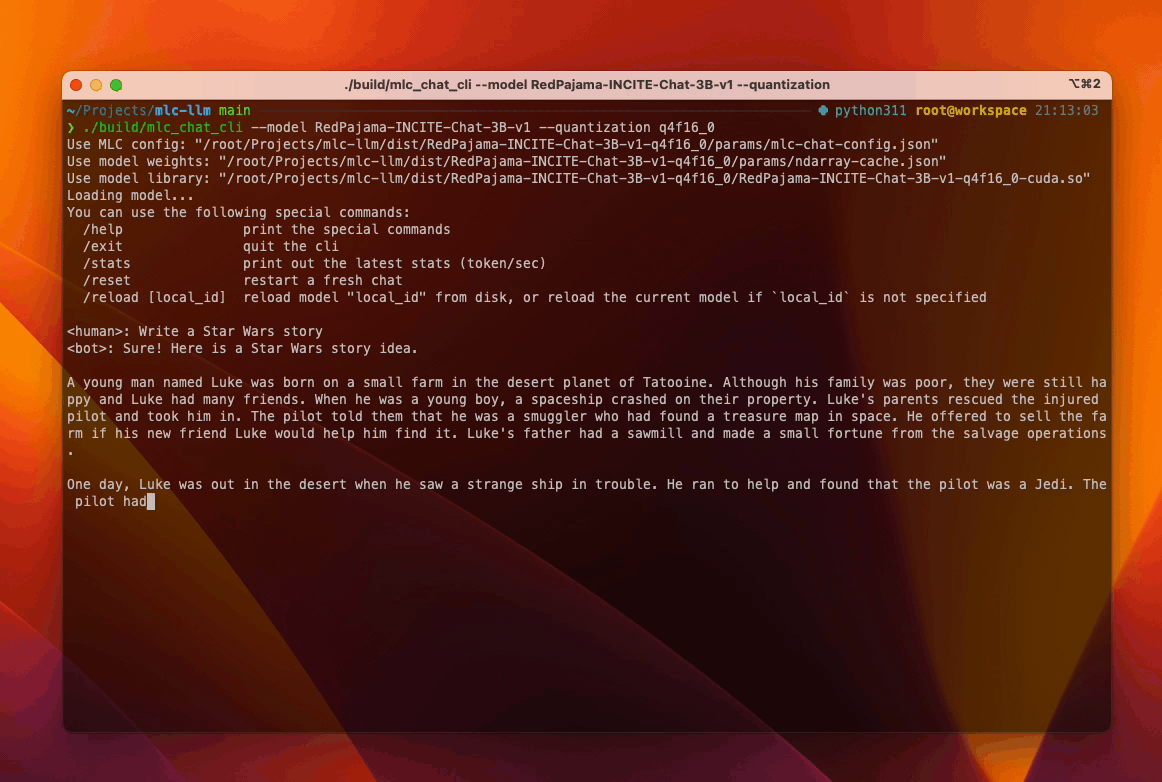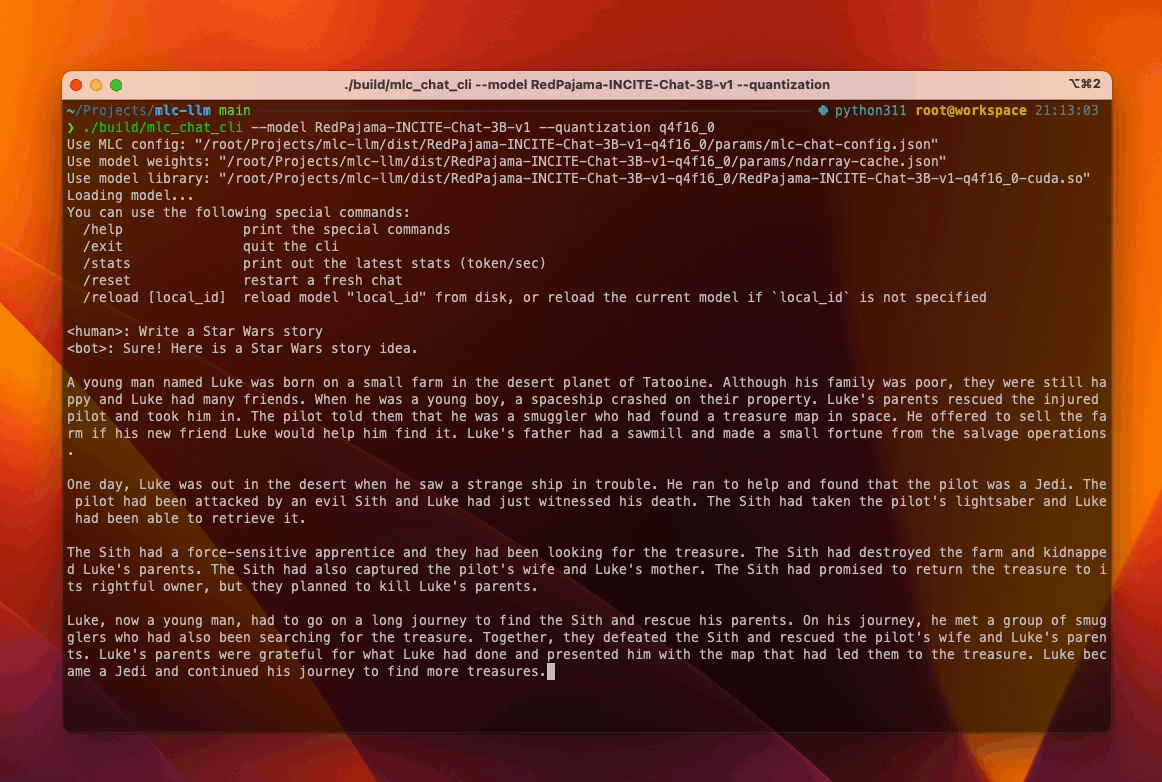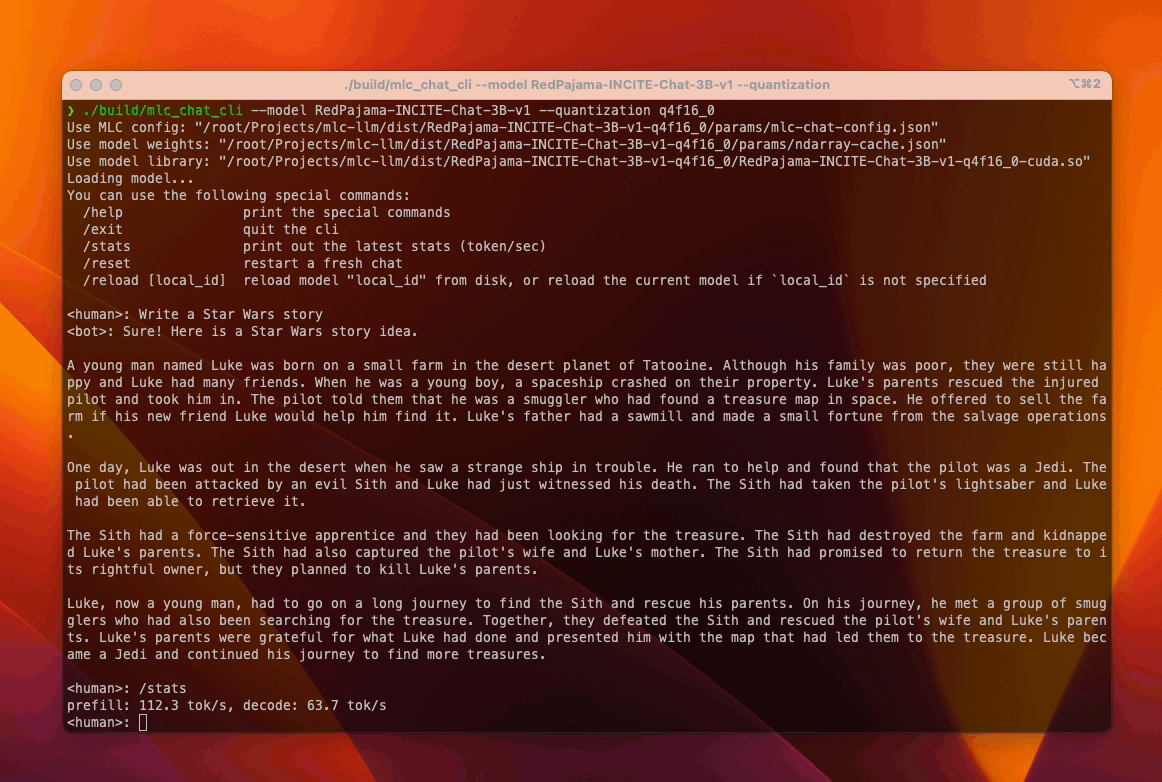
Similarly, RedPajama on consumer-class AMD/NVIDIA GPUs (try out) leverages TVM Unity’s Vulkan backend. The compilation process produces a corresponding wrapper library, libmlc_llm.so that encapsulates the generated SPIR-V/Vulkan code, and users may use mlc_chat_cli to chat with RedPajama. TVM Unity has CUDA, ROCm backends as well, and users have the choice to build alternative CUDA solutions themselves following the same workflow.
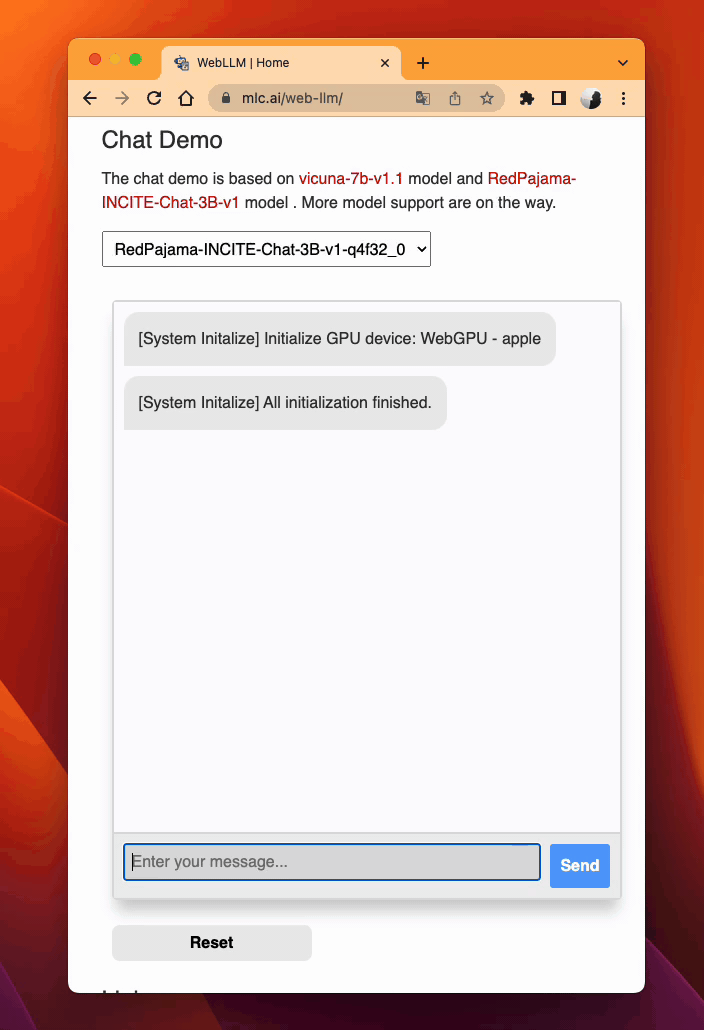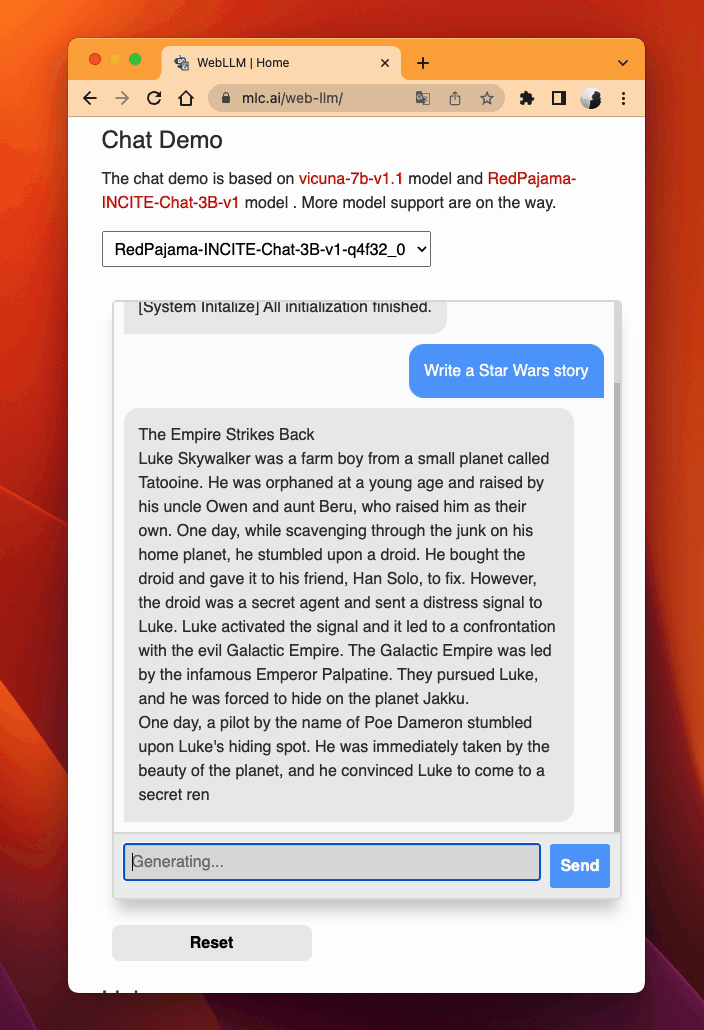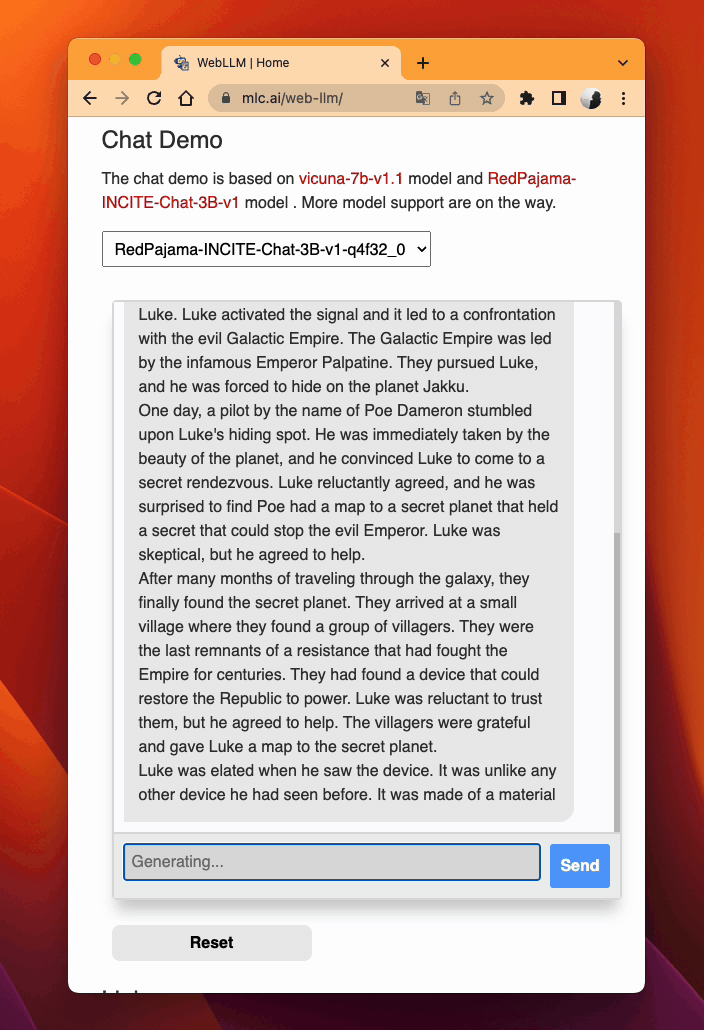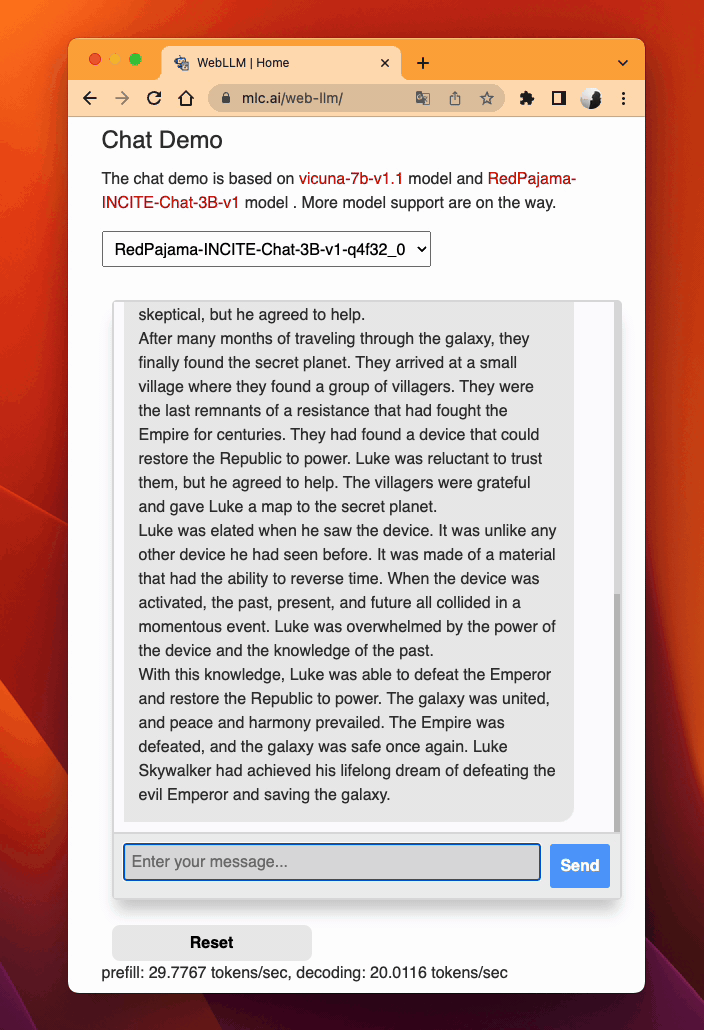
Leveraging WebAssembly and WebGPU, MLC LLM allows RedPajama to be extended smoothly to web browsers (try out). TVM Unity compiles the LLM operators to WebGPU, and along with a lightweight WebAssembly runtime, a thin JavaScript driver llm_chat.js, RedPajama can be deployed as a static web page, harnessing clients’ own GPUs for local inference without a sever support.
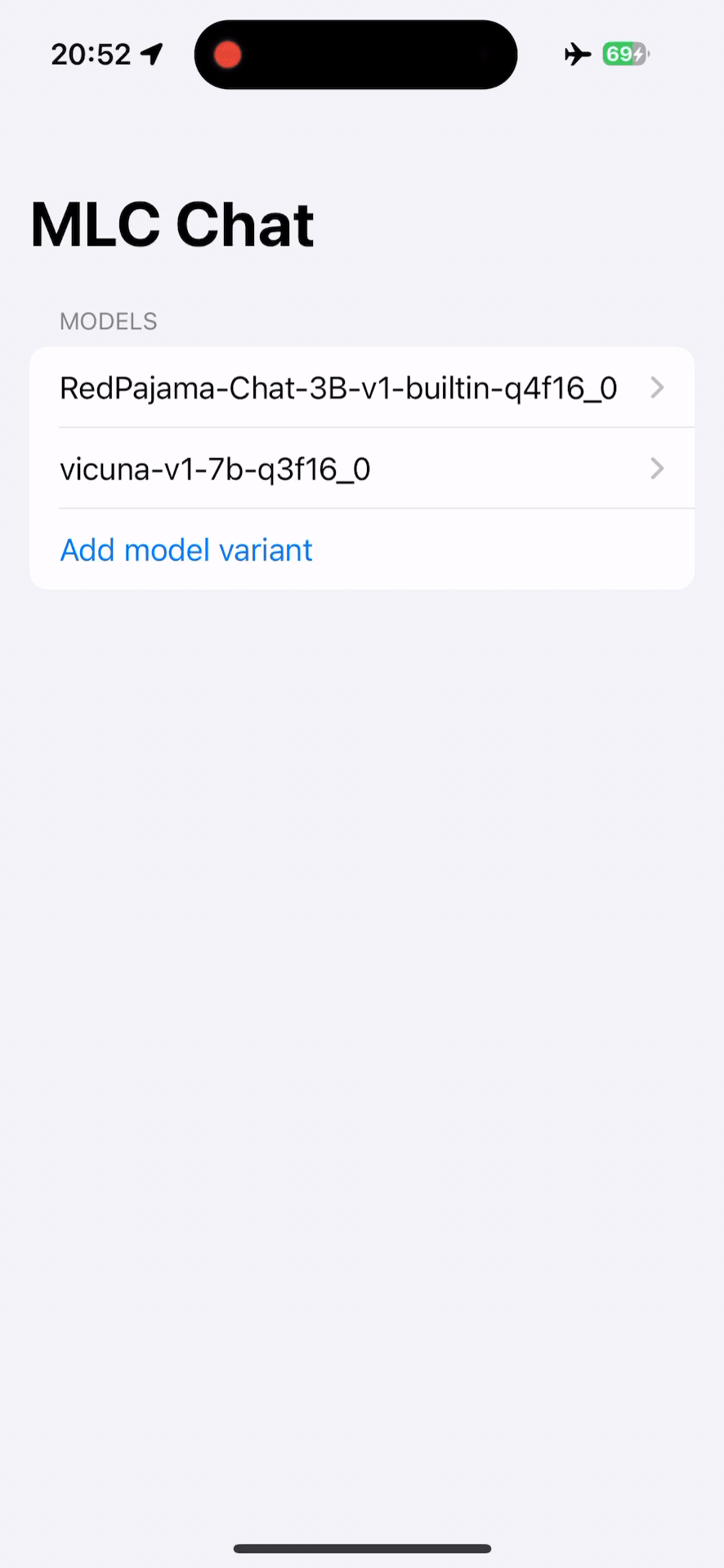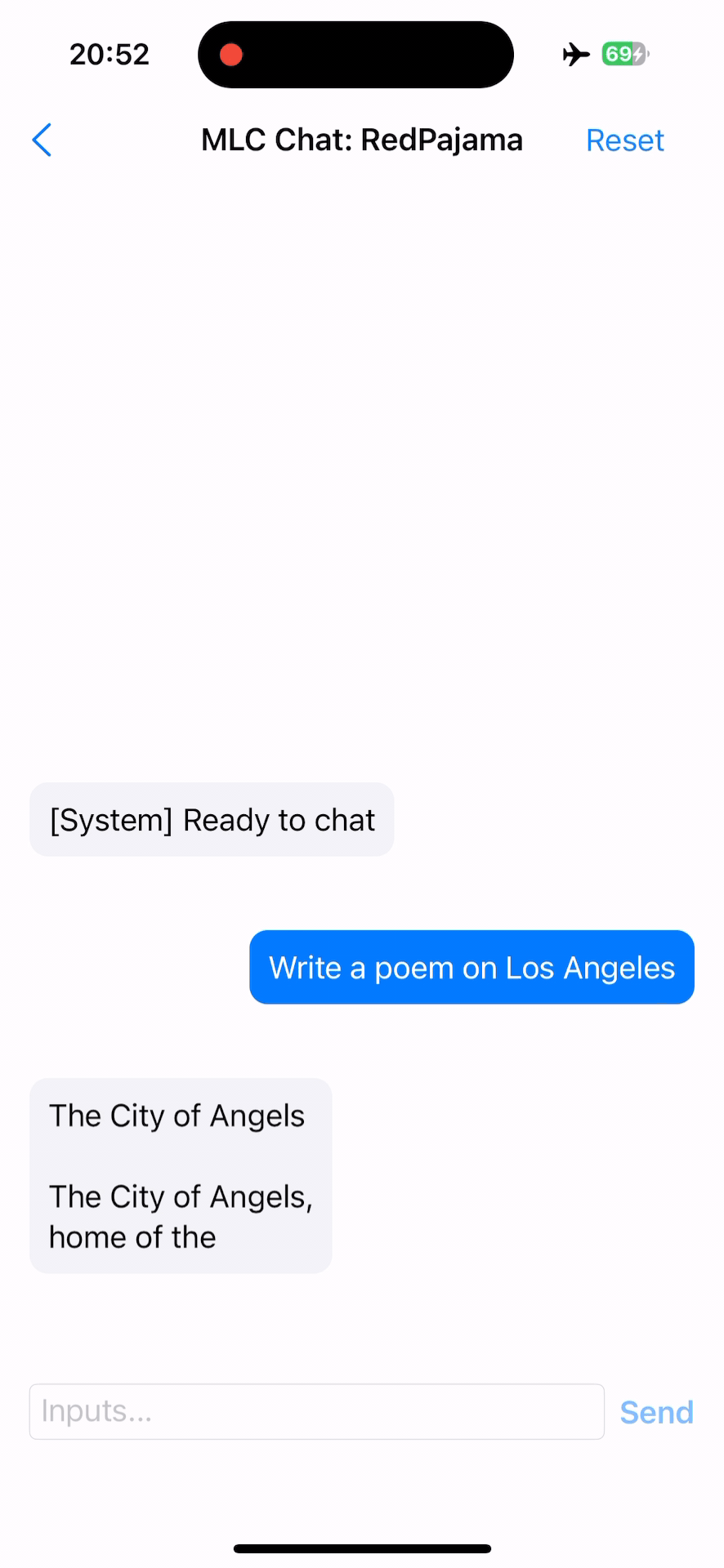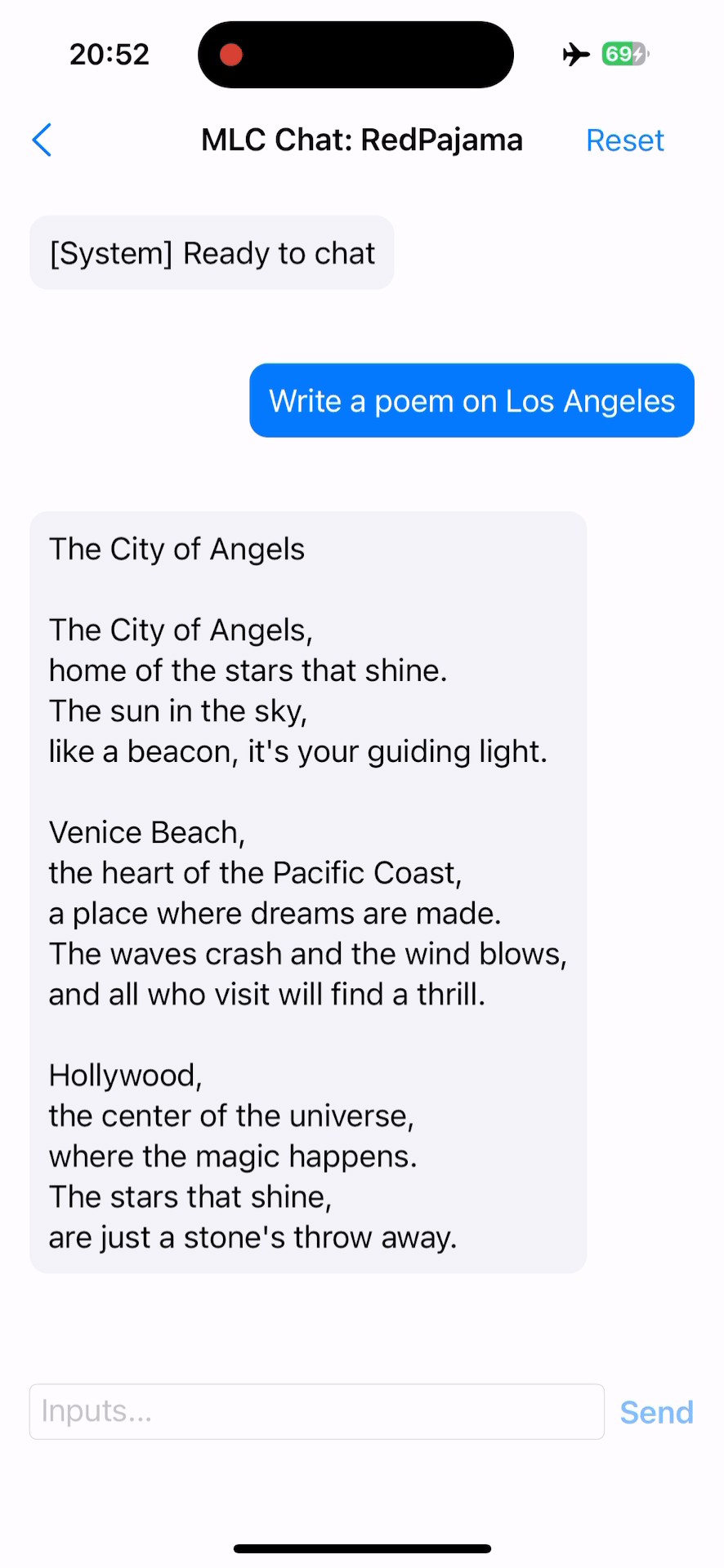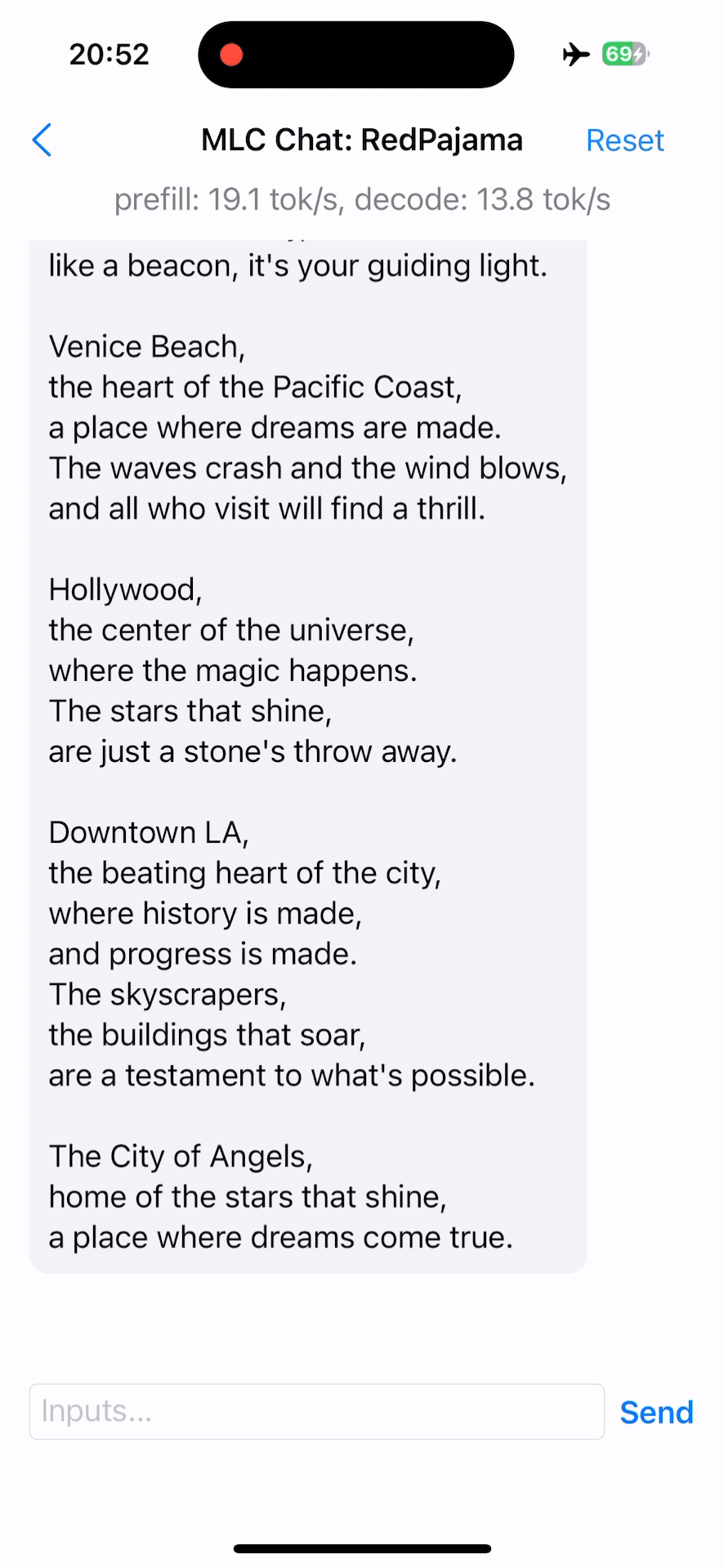
RedPajama on iOS follows a similar approach to Apple Silicon, utilizing Metal as the code generation backend (try out). However, due to iOS restrictions, static libraries (e.g. libmlc_llm.a) are produced instead. To demonstrate the interaction with libmlc_llm.a, we provide an Objective-C++ file, LLMChat.mm, as a practical example, as well as a simple SwiftUI that runs the LLM end-to-end.
How
Machine Learning Compilation (MLC) from TVM Unity plays a critical role in enabling efficient deployment and democratization of Open LLMs. With TVM Unity, several key features contribute to its effectiveness and accessibility:
- Comprehensive code generation: TVM Unity supports code generation for a wide range of common CPU and GPU backends, including CUDA, ROCm, Vulkan, Metal, OpenCL, WebGPU, x86, ARM, etc. This expansive coverage allows for LLM deployment across diverse consumer environments, ensuring compatibility and performance.
- Python-first development: MLC LLM compilation is developed in pure Python, thanks to the Python interface provided by TVM Unity, empowering developers to swiftly develop optimization techniques, compilation passes, and compose LLM building blocks. This approach facilitates rapid development and experimentation that allows us to quickly bring new model and backend support.
- Built-in optimizations: TVM Unity incorporates a suite of built-in optimizations, such as operator fusion and loop tiling, which are keystones of high-quality code generation across multiple hardware platforms. These optimizations are used in MLC LLM, which can be used by ML engineers to amplify their daily workflow.
- First-class support for vendor libraries and handcrafted kernels: TVM Unity treats handcrafted kernels, such as NVIDIA’s CUTLASS and cuBLAS libraries, as first-class citizens. This ensures seamless integration of the best-performing code, allowing developers to leverage specialized and optimized implementations when necessary.
- Finally, a universal runtime that brings deployment to the programming language and platform of the developers’ choice.

MLC LLM follows a streamlined compilation process:
- LLM architecture definition: Users can choose from several built-in models, such as RedPajama, Vicuna, Llama, Dolly, or define their own models using a PyTorch-like syntax provided by TVM Unity.
- ML compilation: MLC LLM uses TVM Unity’s quantization and optimization passes to compile high-level operators into GPU-friendly kernels that are natively compiled to consumer hardware.
- Universal deployment: along with the compiled artifacts from the previous step, MLC LLM provides a convenient pack of the tokenizer and a lightweight runtime for easy deployment on all major platforms, including browsers, iOS, Android, Windows, macOS, and Linux.
Empowering Personalized Fine-Tuned Models
Demand is strong to personalize LLMs, particularly, RedPajama, Vicuna/Llama, and therefore, empowering personalized models is a key feature as fine-tuned LLMs have been dominating the open-source community. MLC LLM allows convenient weight customization that user only needs to provide a directory in Huggingface format, it will produce proper model artifacts through exactly the same process.

MLC LLM’s chat applications (CLI, iOS, Web, Android) are specifically designed to seamlessly integrate personalized models. Developers can easily share a link to the model artifacts they have generated, enabling the chat apps to incorporate the personalized model weights.
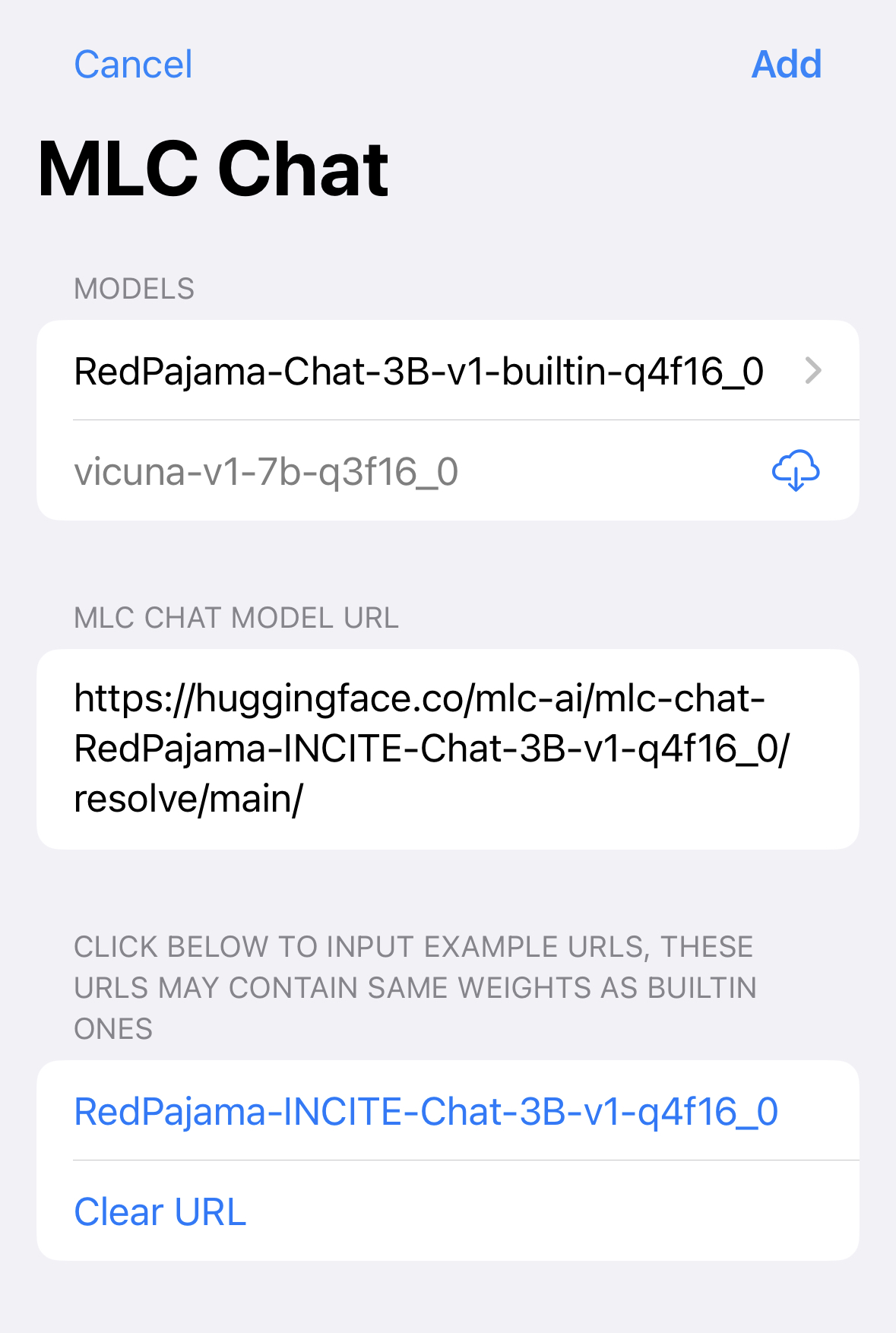
The iOS app allows users to download personalized weights of the same model on-demand via a link to model artifacts without re-compilation or redeployment. This streamlined approach makes it convenient for sharing model weight variants. The same model artifact can be consumed by other runtimes, such as WebApp, CLI and Android(incoming).
Please refer to our project page for a detailed guide on how to try out the MLC LLM deployment. The source code of MLC LLM is available on our official GitHub repository. You are also more than welcomed to join the Discord Channel for further discussion.
Ongoing Effort
MLC LLM is a fairly young project and there are a lot of things to be done. As we start to streamline the overall project architecture and modularize the overall flow, we would love to focus on empowering developer communities. Our first priority is to bring documentation for our developers so they can build on top of our effort. We are actively working on documenting compilation of models with customized weights. Additionally, we are modularizing the overall libraries so it can be reused in other applications, including web, windows, macOS, linux, iOS and Android platforms. We are also expanding the prebuilt MLC pip development package on windows, linux and macOS, to simplify the experience for developers. At the same time, we are continuously working with the community to bring more model architectures. We will also bring more optimizations to continuously improve the memory and performance of the overall system.
Acknowledgement
MLC LLM support for RedPajama-3b is done in collaboration with ETH Zürich, Together, OctoML, CMU Catalyst and the MLC community.
The overall MLC projects are only possible thanks to the shoulders open-source ecosystems that we stand on. We would love to continue developing and supporting the open-source ML community. We want to thank the Apache TVM community and developers of the TVM Unity compiler. The open-source ML community members made these models publicly available. PyTorch and Hugging Face communities that make these models accessible. We would like to thank the teams behind RedPajama, Dolly, Vicuna, SentencePiece, LLaMA, and Alpaca. We also would like to thank OpenCL, Vulkan, C++, Python, Rust communities that enable this project.