In this post, we introduce MLC LLM for Android – a solution that allows large language models to be deployed natively on Android devices, plus a productive framework for everyone to further optimize model performance for their use cases. Everything runs locally and accelerated with native GPU on the phone.
We have witnessed significant progress in the field of generative AI and large language models. Thanks to the open source movement, we have seen the blooming moment of open source foundational models. While it is helpful to run those models on the server platforms, there are also great deal of potential to enable large-language models on consumer devices
Empowering LLMs on mobile devices is very important given this is what we interact with daily. Android is an operating system inside 2.5 billion active devices, we would love to bring LLM support to Android devices. This post shares our experience on bringing LLMs to Android devices.
How
If you follow our latest posts, you might know that we bought have support for LLMs on iPhones. We would like to do the same thing for Android. However, the iOS and Android ecosystems have different sets of programming models both for host app programming and GPU programming, bringing challenges to our goal, to name a few:
- We need to use different GPU programming models to provide hardware acceleration.
- We need to optimize for different kinds of hardware backends. Apple’s A16 chips power iOS devices, while many of the latest Android devices are powered by chips like Snapdragon Gen2. They need different optimization strategies to get the best performance.
- We need to connect our LLM runtime to different host languages. In iOS we need to interface with object-c and swift. We will need to support Java to enable the Android ecosystem.

Thanks to MLC-LLM’s universal deployment solution, we can overcome these challenges and productively deploy a vicuna 7b model onto a Samsung Galaxy S23, powered by the latest Snapdragon 8 Gen 2 Mobile Platform.
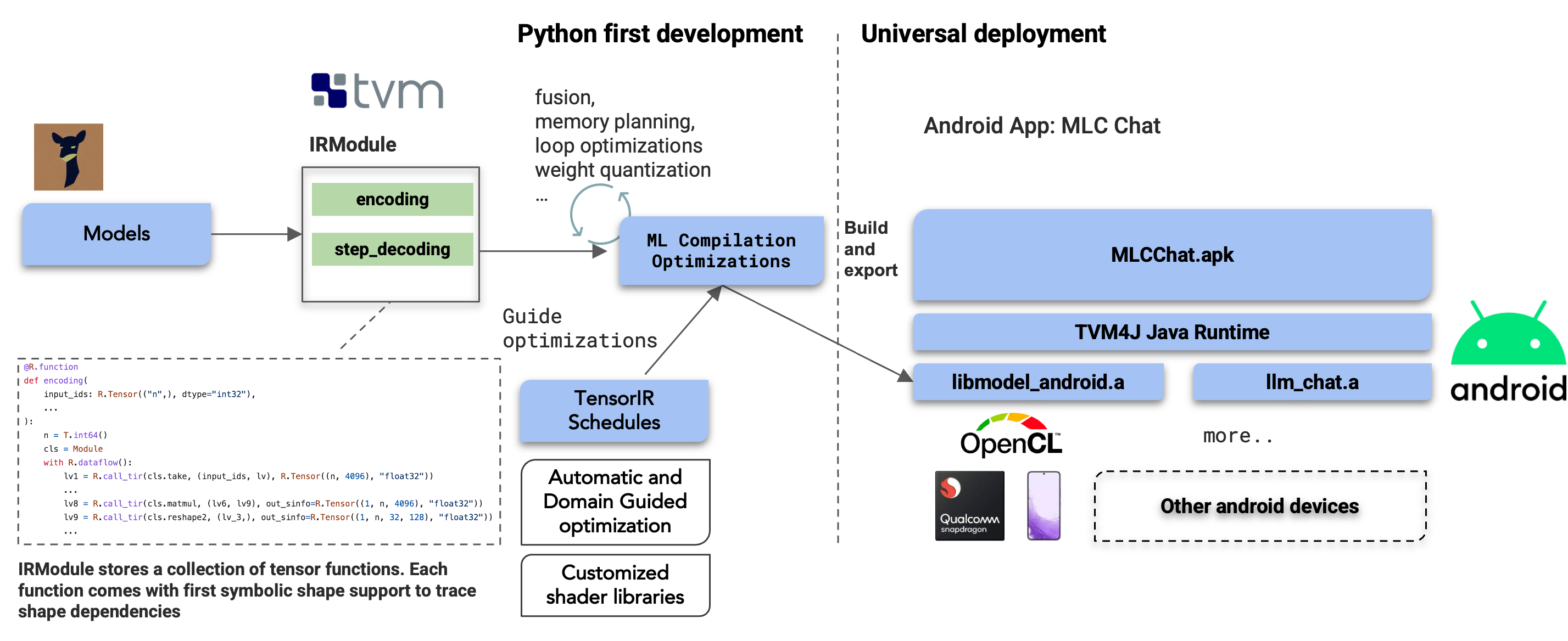
The cornerstone of our solution is machine learning compilation (MLC), which we leverage to deploy AI models efficiently.
- We effectively used the same ML compilation pipeline for overall model ingestion, fusion, and memory planning.
- We leveraged TensorIR, and our automatic optimization stack of TVM unity to generate and optimize specific GPU kernels for Adreno GPU on the snapdragon chip via generating OpenCL kernels.
- Thanks to the python first development flow, we can productively iterate on model weight quantization, dequantization, and kernel computation to get reasonably good performance out of the LLM.
- We leveraged the universal deployment runtime of TVM unity that enables developers to deploy using their chosen language. In the case of Android, we use TVM4J to invoke the LLM modules from Java directly.
Our solution provides a good harness to optimize more models on Android hardware backends further. We believe there are still a lot of opportunities, but it is amazing how far we can go in one week’s effort. We would love to work with the open-source community to bring further optimizations via ML compilation.
Because Android does not have the 4GB app RAM limit, which iOS enforce, we can leverage more RAM than our iOS deployment. So we choose to enable a 4-bit quantized vicuna model, which preserves more capabilities, especially in languages other than English. We are also looking forward to supporting other storage-efficient models in the future.
You can check out the demo instruction to try it out, our github repo for source code. MLC LLM enables deployment to various devices, including Windows, Linux, MacOS, iPhone, and now Android. You are also welcome to check out the demo instruction page for more information on running on other devices.
Acknowledgement
The MLC LLM project is initiated by members from CMU catalyst, UW SAMPL, SJTU, OctoML and the MLC community.
We would love to continue developing and supporting the open-source ML community. The overall MLC projects are only possible thanks to the shoulders open-source ecosystems that we stand on. We want to thank the Apache TVM community and developers of the TVM Unity effort. The open-source ML community members made these models publicly available. PyTorch and Hugging Face communities that make these models accessible. We would like to thank the teams behind Vicuna, SentencePiece, LLaMA, and Alpaca. We also would like to thank the OpenCL Vulkan, Android, C++, python Rust communities that enable this project.