TL;DR
MLC-LLM makes it possible to compile LLMs and deploy them on AMD GPUs using ROCm with competitive performance. More specifically, AMD Radeon™ RX 7900 XTX gives 80% of the speed of NVIDIA® GeForce RTX™ 4090 and 94% of the speed of NVIDIA® GeForce RTX™ 3090Ti for Llama2-7B/13B. Besides ROCm, our Vulkan support allows us to generalize LLM deployment to other AMD devices, for example, a SteamDeck with an AMD APU.

Background
There have been many LLM inference solutions since the bloom of open-source LLMs. Most of the performant inference solutions are based on CUDA and optimized for NVIDIA GPUs. In the meantime, with the high demand for compute availability, it is useful to bring support to a broader class of hardware accelerators. AMD is one potential candidate.
Discussion on the Hardware and Software
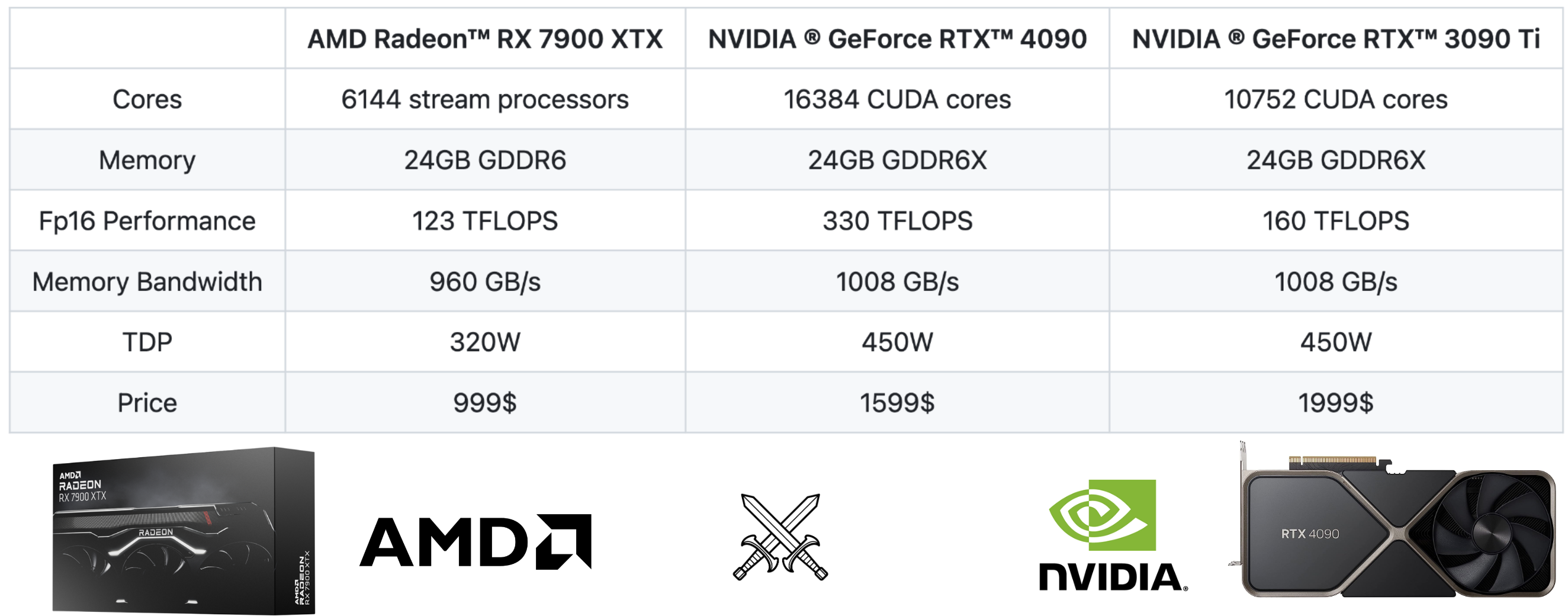
From the spec comparison, we can see that AMD’s RX 7900 XTX is a good match for NVIDIA’s RTX 4090 and RTX 3090 Ti.
- All have 24GB memory, which means they can fit models of the same size.
- All have similar memory bandwidth.
- 4090 has 2x more FP16 performance than 7900 XTX, while 3090 Ti has 1.3x more FP16 performance than 7900 XTX. Lantency sensitive LLM inference is mostly memory bound, so the FP16 performance is not a bottleneck here.
- RX 7900 XTX is 40% cheaper than RTX 4090.
It is harder to compare the price of 3090Ti as that was a previous generation. We put it here as a reference point to provide more information. At a high-level, we can find that AMD 7900 XTX is comparable to RTX 3090 Ti from the hardware spec perspective.
Hardware is not necessarily the reason why AMD lagged in the past. The main gaps were due to a lack of software support and optimizations for the relevant models. There are two factors in the ecosystem that starts to bring changes to the picture:
- AMD is trying to catch up with investments in the ROCm stack.
- Emerging technologies like machine learning compilation helps to reduce overall cost of more universal software support across backends.
In this post, we are taking a deep look at how well AMD GPUs can do compared to a performant CUDA solution on NVIDIA GPUs as of now.
Machine Learning Compilation for ROCm
What is machine learning compilation (MLC). Machine learning compilation is an emerging technology that compiles and automates the optimization of machine learning workloads. Instead of crafting specific kernels for each individual backend like ROCm or CUDA, an MLC solution automatically generate code for different backends. Here we leverage MLC-LLM, an ML compilation-based solution that offers high-performance universal deployment for LLMs. MLC-LLM builds on top of Apache TVM Unity, a machine-learning compilation stack that offers productive Python-first development and universal deployment. MLC-LLM brings state-of-the-art performance for a wide variety of backends, including CUDA, Metal, ROCm, Vulkan, and OpenCL, spanning both server-class GPUs to mobile (iPhone and Android). At a high level, the framework lets the user take open language models and compiles it with Python-based workflow, including APIs to transform computational graphs, optimize the layout and scheduling of GPU kernels, and deploys it natively on platforms of interest.

MLC for AMD GPUs and APUs. There are several possible ways to support AMD GPU: ROCm, OpenCL, Vulkan, and WebGPU. ROCm stack is what AMD recently push for and has a lot of the corresponding building blocks similar to the CUDA stack. Vulkan is the latest graphics standard and offers the widest range of support across GPU devices. WebGPU is the latest web standard that allows the computation to run on web browsers. While there are so many possible ways, few ML software solutions that build for solutions other than CUDA, largely due to the engineering cost to replicate a stack for a new hardware or GPU programming model. We support automatic code generation without having to recraft GPU kernels for each and bring support to all these ways. This being said, the performance still depends on how good the low-level GPU runtimes are and their availability in each platform. We pick ROCm for Radeon 7900 XTX and Vulkan for Steamdeck’s APU. We find that ROCm stack works out of the box. Thanks to the productive Python-based development pipeline in TVM unity, we spent a few more hours to further bring an optimized version. We made the following things to bring ROCm support:
- Reuse the whole MLC pipeline for existing targets (such as CUDA and Metal), including memory planning, operator fusion, etc.
- Reuse a generic GPU kernel optimization space written in TVM TensorIR and re-target it to AMD GPUs.
- Reuse TVM’s ROCm code generation flow that generates low-level ROCm kernels through LLVM.
- Finally, export generated code as a shared or static library that can be invoked by CLI, Python and REST APIs.
Benchmark with MLC Python Package
We benchmarked the Llama 2 7B and 13B with 4-bit quantization. And we measure the decoding performance by setting a single prompt token and generating 512 tokens. All the results are measured for single batch inference.

For single batch inference performance, it can reach 80% of the speed of NVIDIA 4090 with the release of ROCm 5.6.
Note on the comparison: How strong is our CUDA baseline? It is the state-of-the-art for this task to the best of our knowledge. We believe there is still room for improvements, e.g. through better attention optimizations. As soon as those optimizations land in MLC, we anticipate both AMD and NVIDIA numbers improved. If such optimizations are only implemented on NVIDIA side, it brings the gap up from 20% to 30%. And therefore, we recommend putting 10% error bar when looking at the numbers here
Try it out yourself
We provide prebuilt wheels and instructions to reproduce our results on your own devices. To run those benchmarks, please ensure that you have an AMD GPU with ROCm 5.6 or above running in Linux. Follow the instructions here to install a prebuilt MLC package with ROCm enabled: Run the Python script below that uses our MLC package to reproduce performance numbers:
from mlc_chat import ChatModule
# Create a ChatModule instance that loads from `./dist/prebuilt/Llama-2-7b-chat-hf-q4f16_1`
cm = ChatModule(model="Llama-2-7b-chat-hf-q4f16_1")
# Run the benchmarks
output = cm.benchmark_generate("Hi", generate_length=512)
print(f"Generated text:\n{output}\n")
print(f"Statistics: {cm.stats()}")
# Reset the chat module by
# cm.reset_chat()
MLC-LLM also provides a CLI that allows you to chat with the model interactively. For ROCm it requires to build the CLI from source. Please follow the instructions here to build the CLI from source.
Running on SteamDeck using Vulkan with Unified Memory
Let us also look into a broader set of AMD devices, more specifically, SteamDeck equipped with an AMD APU. While the GPU VRAM available in ROCm is capped to 4GB in BIOS, the Mesa Vulkan driver has robust support that allows the buffer to go beyond the cap using unified memory up to 16GB, which is sufficient to run 4bit-quantized Llama-7B.
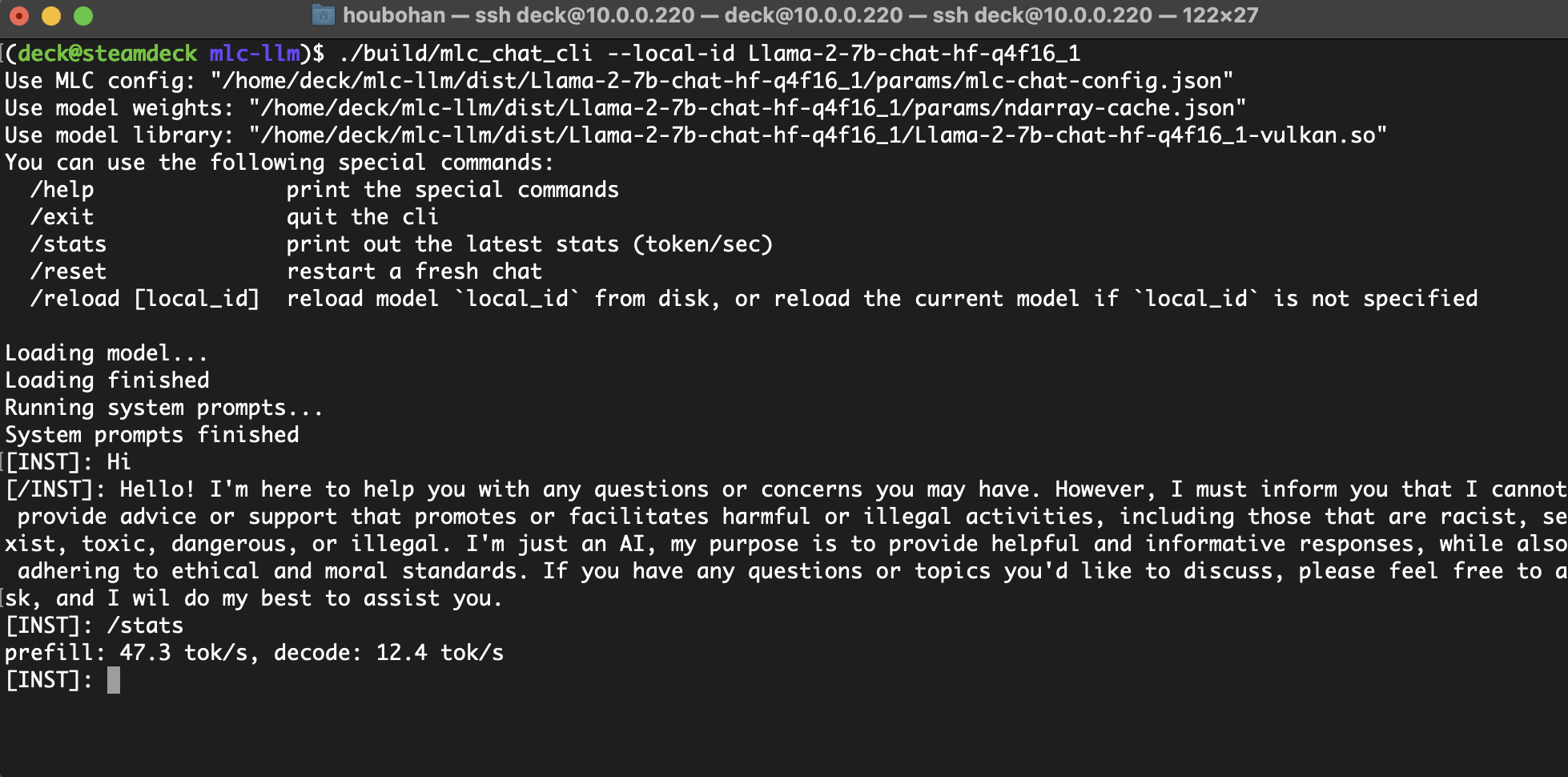
These results shed some light on how a broad spectrum of AMD devices can be supported for more diverse set of of consumers.
Discussion and Future Work
Hardware availability has become a pressing issue in the age of generative AI. ML compilation can help by bringing high-performance universal deployment across hardware backends. Given the presented evidences, with the right price and availability, we think AMD GPUs can start to be useful for LLM inference.
Our study focuses on consumer-grade GPUs as of now. Based on our past experiences, MLC optimizations for consumer GPU models usually are generalizable to cloud GPUs (e.g. from RTX 4090 to A100 and A10g). We are confident that the solution generalizes across cloud and consumer-class AMD and NVIDIA GPUs, and will also update our study once we have access to more GPUs. We also encourage the community to build solutions on top of the MLC universal deployment flow.
This post is part of the ongoing effort that brings high-performance universal deployment via MLC. We are also actively working on several areas that can generalize our study.
- Enable batching and multi-GPU support;
- Integration with PyTorch ecosystem;
- Empowering more quantization and model architectures;
- Bringing in more automatic optimizations on more hardware backends.
Our final takeaway is that machine learning system engineering is a continuous problem. NVIDIA is still leading the field with continuous innovations, and we anticipate the landscape to change with new hardware such as H100 and, more importantly, software evolutions. So the key question is not only about building the right solution now but also how to catch up and bring ML engineering to new platforms continuously. Productivity in machine learning engineering is the key here. Thanks to the Python-first ML compilation development flow, we get ROCm-optimized support in a few hours. We anticipate related approaches to become even more useful as we explore more ideas to bring universal deployments and solve the hardware availability problem.
Links
Please refer to our project page for a detailed guide on how to try out the MLC LLM deployment. The source code of MLC LLM is available on our official GitHub repository. You are also more than welcome to join the Discord Channel for further discussion.
Acknowledgement
The overall MLC projects are only possible thanks to the shoulders of open-source ecosystems that we stand on. We would love to continue developing and supporting the open-source ML community. We want to thank the Apache TVM community and developers of the TVM Unity compiler. The open-source ML community members made these models publicly available. PyTorch and Hugging Face communities make these models accessible. We would like to thank the teams behind RedPajama, Dolly, Vicuna, SentencePiece, LLaMA, and Alpaca. We also would like to thank OpenCL, Vulkan, C++, Python, and Rust communities that enable this project.