TL;DR
This post shows GPU-accelerated LLM running smoothly on an embedded device at a reasonable speed. More specifically, on a $100 Orange Pi 5 with Mali GPU, we achieve 2.3 tok/ser for Llama3-8b, 2.5 tok/sec for Llama2-7b and 5 tok/sec for RedPajama-3b through Machine Learning Compilation (MLC) techniques. Additionally, we are able to run a Llama-2 13b model at 1.5 tok/sec on a 16GB version of the Orange Pi 5+ under $150.
Background
Progress in open language models has been catalyzing innovation across question-answering, translation, and creative tasks. While current solutions demand high-end desktop GPUs to achieve satisfactory performance, to unleash LLMs for everyday use, we wanted to understand how usable we could deploy them on the affordable embedded devices.
Many embedded devices come with mobile GPUs that can serve as a source of acceleration. In this post, we pick Orange Pi 5, a RK3588-based board that is similar to Raspberry Pi but also features a more powerful Mali-G610 GPU. This post summarizes our first attempt at leveraging Machine Learning Compilation and provides out-of-box GPU acceleration for this device.
Machine Learning Compilation for Mali

Machine learning compilation (MLC) is an emerging technology that automatically compiles and optimizes machine learning workloads, and deploys the compiled workload to a broad set of backends. At the time of writing, based on Apache TVM Unity, MLC supports platforms including browsers (WebGPU, WASM), NVIDIA GPUs (CUDA), AMD GPUs (ROCm, Vulkan), Intel GPUs (Vulkan), iOS and MacBooks (Metal), Android (OpenCL), and Mali GPUs (this post).
Generalizable ML Compilation for Mali Codegen
MLC is built on top of Apache TVM Unity, a generalizable stack for compiling machine learning models across different hardwares and backends. To compile LLMs onto Mali GPUs, we reuse all the existing compilation pipeline without any code optimizations. More specifically, we successfully deployed Llama-2/3 and RedPajama models with the following steps:
- Reuse model optimization passes, including quantization, fusion, layout optimization, etc;
- Reuse a generic GPU kernel optimization space written in TVM TensorIR and re-target it to Mali GPUs;
- Reuse OpenCL codegen backend from TVM, and re-target it to Mali GPUs;
- Reuse the existing user interface, including Python APIs, CLI, and REST APIs.
Try it out
This section provides a step-by-step guide so that you can try it out on your own orange pi device. Here we use Llama-3-8B-Instruct-q4f16_1-MLC as the running example. You can replace that by Llama-2-7b-chat-hf-q4f16_1 or Llama-2-13b-chat-hf-q4f16_1 (requires a 16GB board).
Prepare
Please first follow the instruction here, to setup the RK3588 board with OpenCL driver. Then clone the MLC-LLM from the source, and download weights and prebuilt libs.
# clone mlc-llm from GitHub
git clone --recursive https://github.com/mlc-ai/mlc-llm.git && cd mlc-llm
# Download prebuilt weights and libs
git lfs install
mkdir -p dist/prebuilt && cd dist/prebuilt
git clone https://github.com/mlc-ai/binary-mlc-llm-libs.git lib
git clone https://huggingface.co/mlc-ai/Llama-3-8B-Instruct-q4f16_1-MLC
cd ../../..
Try out the CLI
Build mlc_llm_cli from the source code
cd mlc-llm/
# create build directory
mkdir -p build && cd build
# generate build configuration
python3 ../cmake/gen_cmake_config.py
# build `mlc_llm python package`
cmake .. && cmake --build . --parallel $(nproc) && cd ..
Verify installation
# expected to see , `libmlc_llm.so` and `libmlc_llm_module.so`
ls -l ./build/
Try out the Python API
Build TVM runtime
# clone from GitHub
git clone --recursive https://github.com/mlc-ai/relax.git tvm_unity && cd tvm_unity/
# create build directory
mkdir -p build && cd build
# generate build configuration
cp ../cmake/config.cmake . && echo "set(CMAKE_BUILD_TYPE RelWithDebInfo)\nset(USE_OPENCL ON)" >> config.cmake
# build `TVM runtime`
cmake .. && cmake --build . --target runtime --parallel $(nproc) && cd ../..
Setup python path (please set it to the bashrc or zshrc for persistent settings)
export TVM_HOME=$(pwd)/tvm_unity
export MLC_LLM_HOME=$(pwd)/mlc-llm
export PYTHONPATH=$TVM_HOME/python:$MLC_LLM_HOME/python:${PYTHONPATH}
Run the following python script.
from mlc_llm import ChatModule
from mlc_llm.callback import StreamToStdout
cm = ChatModule(
model="dist/prebuilt/Llama-3-8B-Instruct-q4f16_1-MLC",
model_lib_path="dist/prebuilt/lib/Llama-3-8b-Instruct/Llama-3-8B-Instruct-q4f16_1-mali.so",
device="opencl"
)
# Generate a response for a given prompt
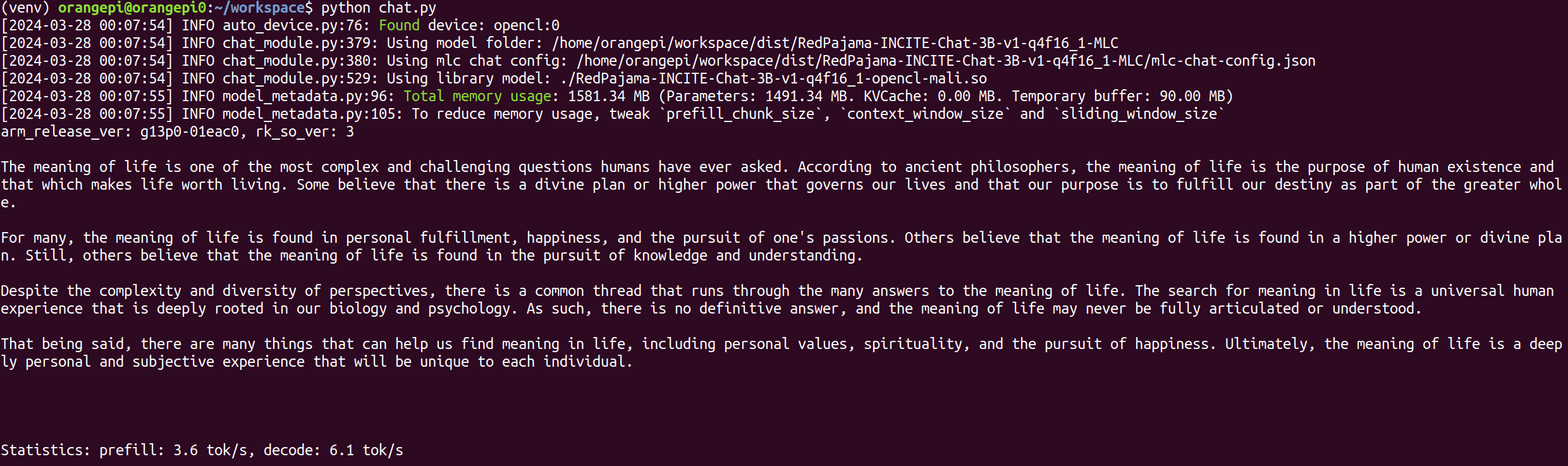
cm.generate(prompt="What is the meaning of life?", progress_callback=StreamToStdout(callback_interval=2))
# Print prefill and decode performance statistics
print(f"Statistics: {cm.stats()}\n")
Discussion and Future Work
Our current experiments show that 8B models might be a sweet spot. The Llama-3-8b-Instruct model can provide up to 2 tok/sec and a decent chat experience. There is also room for improvements, specifically around the integer-to-float conversions. Moving forward, we will address the related issues and improve Mali GPUs’ performance.
This post contributes to our quest to integrate LLMs into affordable devices and bring AI to everyone. Our future endeavors will focus on harnessing advancements in single-board computers, refining software frameworks like OpenCL and MLC-LLM, and exploring broader applications such as smart home devices. Collaborative efforts in the open-source community and a commitment to continuous learning and adaptation will be pivotal in navigating the evolving landscape of LLM deployment on emerging hardware.
Contributions
LLM on Orange Pi is primarily completed by Haolin Zhang, update by Mengshiun Yu. The support of mali optimizations comes from Siyuan Feng, with foundation support from Junru Shao and Bohan Hou and other community members.