Introduction
We are in the age of large language models and generative AI, with use cases that can potentially change everyone’s life. Open large language models bring significant opportunities to offer customization and domain-specific deployment.
We are in an exciting year for open model development. On one hand, we saw exciting progress on (cloud) server deployments, with solutions enabling serving concurrent user requests for bigger models with multiple GPUs. Meanwhile, we are also starting to see progress in on-device local deployment, with capable quantized models deployed onto laptops, browsers, and phones. Where will the future go? We believe the future is hybrid, so it is important to enable anyone to run LLM in both cloud and local environments.
Many of the LLM inference projects, including a past version of our MLC LLM effort, provide different solutions for server and local use cases, with distinct implementations and optimizations. For example, server solutions usually enable continuous batching and better multi-GPU support, while local solutions bring better portability across platforms. However, we believe there is a strong need to bring all the techniques together. Many techniques appearing in one side of use cases are directly applicable to the other side. While techniques like continuous batching may not be practical for some local use cases at this moment, they will become valuable as LLMs become a key component of operating systems and support multiple requests to enable agent tasks. We would like to ask a question: is it possible to build a single unified LLM engine that works across server and local use cases?
In this post, we introduce the MLC LLM Engine (MLCEngine for short), a universal deployment engine for LLMs. MLCEngine introduces a single engine for high-throughput, low-latency serving on servers, while seamlessly integrating small and capable models to diverse local environments.

The path to enabling universal deployment has unique challenges. First, it needs to support a broad spectrum of GPU programming models and runtimes to enable acceleration on each of the supported platforms. Such a process typically requires a lot of repeated engineering effort. We need to leverage effective vendor libraries when possible, but also be able to support emerging platforms such as Vulkan or WebGPU which lack standard library support. Additionally, each app platform has a different programming language environment, which increases the complexity of bringing the engine to environments such as Swift, Kotlin, Javascript, and more.
To overcome the platform support challenge, we leverage the technique of machine learning compilation through Apache TVM to automatically generate portable GPU libraries to a wide range of hardware and platforms. Additionally, we build a portable runtime architecture that combines the state of art industry grade LLM serving optimizations (such as continuous batching, speculative decoding, prefix caching etc) with maximum portability to both cloud and local platforms.

The compiled model libraries work together with a universal runtime that brings direct language bindings in different host app languages, which share the same OpenAI style chat completion API. All the local app environments share the same core engine as the cloud server setting, with specialized configurations for each individual setup.
Getting Started with Chat
The easiest way to get started with MLCEngine is through the chat CLI interface. We provide a command line chat interface for this purpose. Below is an example command that starts chat CLI in the terminal that runs a 4-bit quantized Llama3 8B model.
mlc_llm chat HF://mlc-ai/Llama-3-8B-Instruct-q4f16_1-MLC
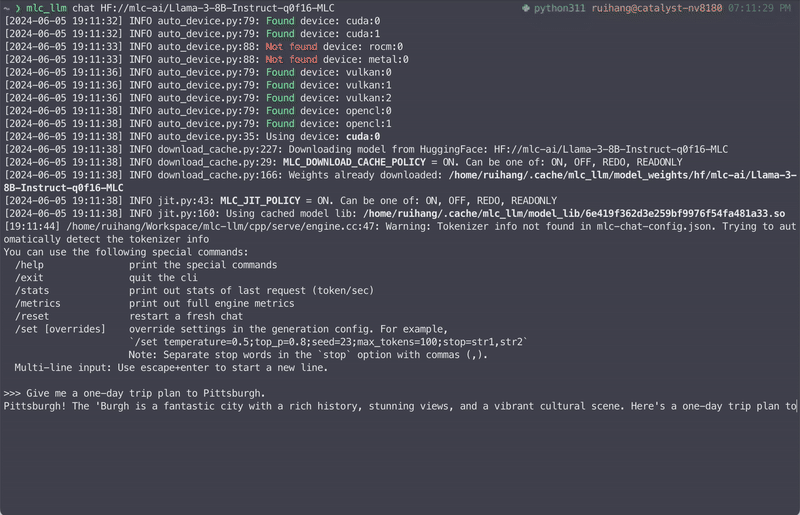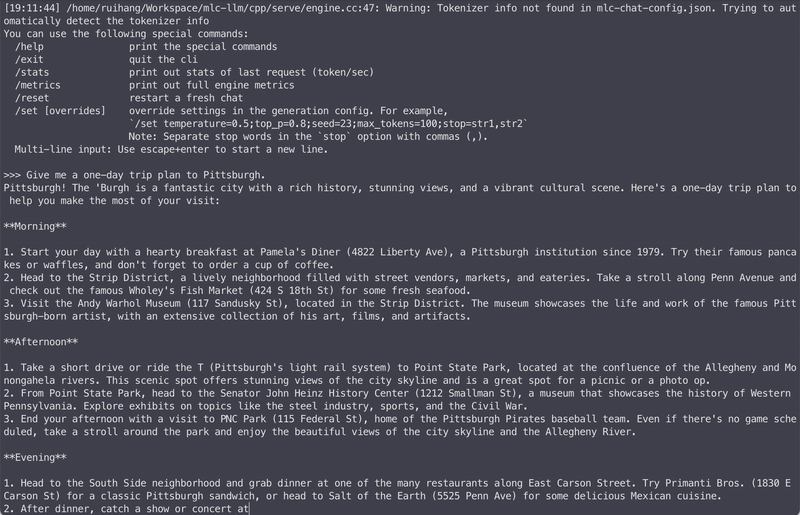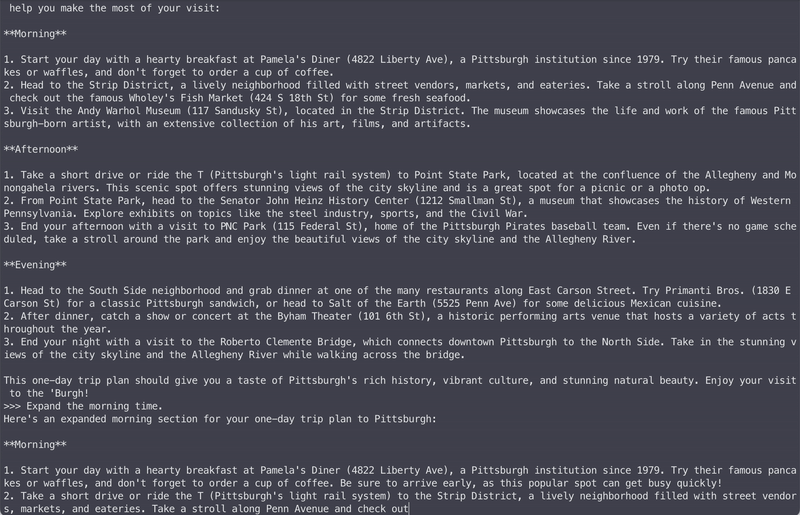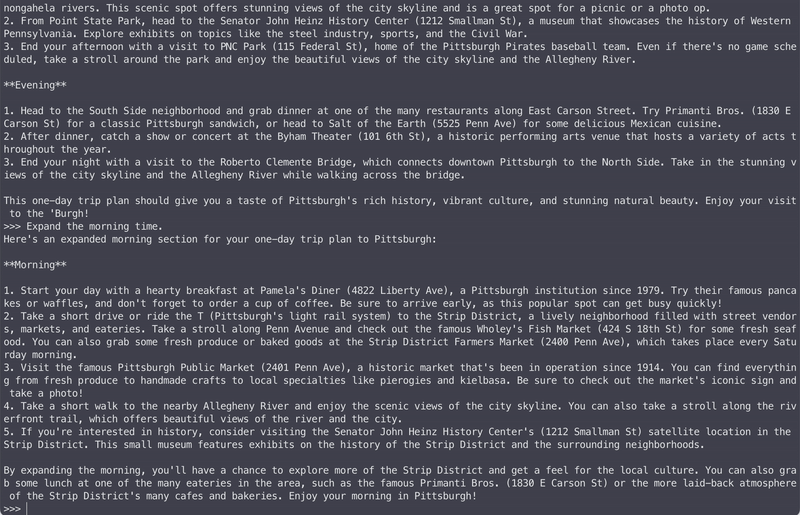
Under the hood, we run just-in-time model compilations to generate GPU code for each platform. So it can work across GPU types and operating systems.
We support a wide range of model families including Llama3, Mistral/Mixtral, Phi3, Qwen2, Gemma and many others.
Use MLCEngine via OpenAI-style API
As we introduce a universal LLM engine, it is important to design a set of APIs that developers are familiar with and find easy to use. We choose to adopt OpenAI style API across all environments. This section walks us through each of these APIs.
REST API Server on the Cloud
LLM serving is one of the most typical LLM applications. LLM servers work by running an internal LLM engine to process all requests received from the network. We provide a REST server with full OpenAI API completeness to process LLM generation requests. Below is an example command that launches the REST server at localhost to serve the 4-bit quantized Llama3 8B model.
mlc_llm serve HF://mlc-ai/Llama-3-8B-Instruct-q4f16_1-MLC
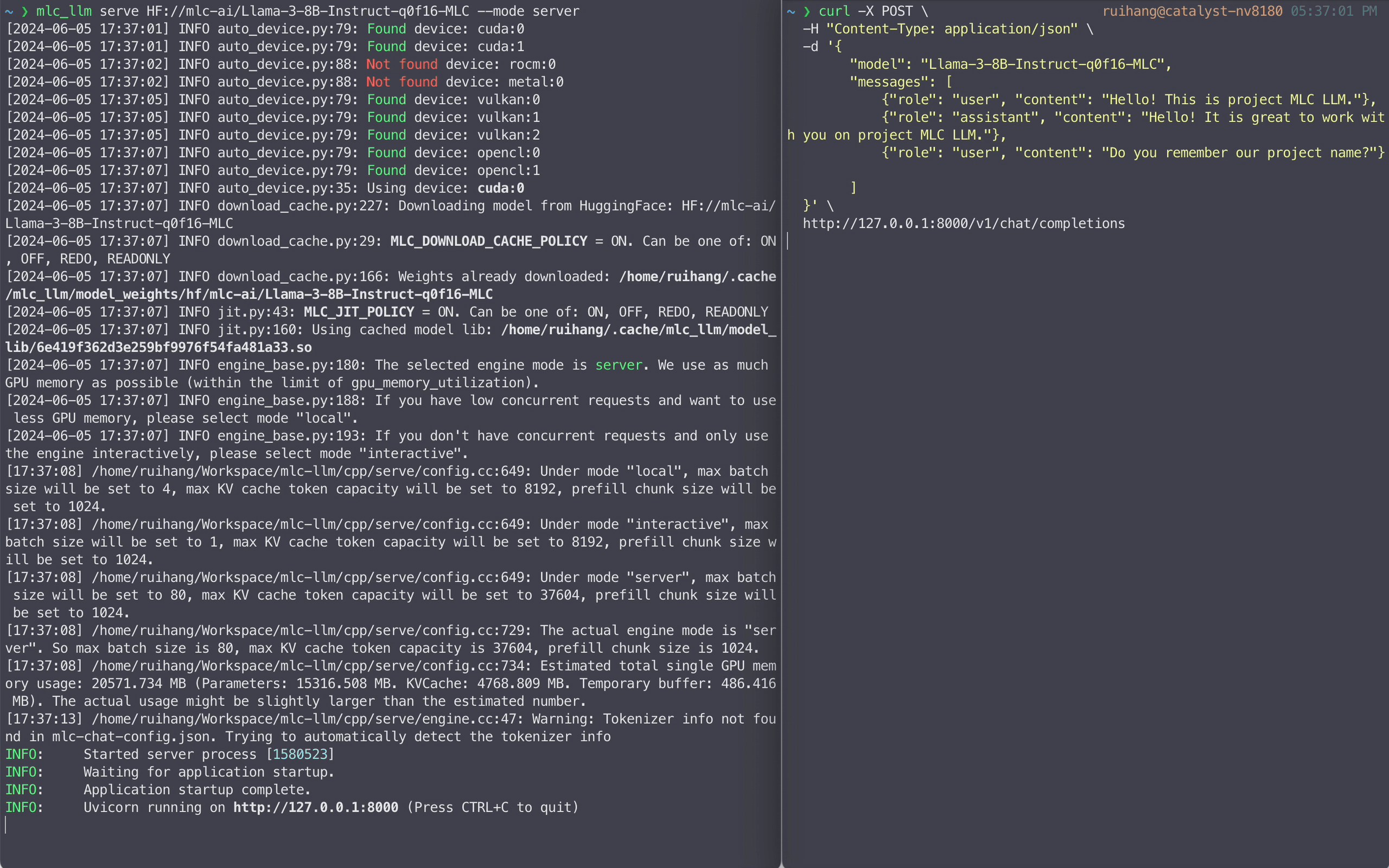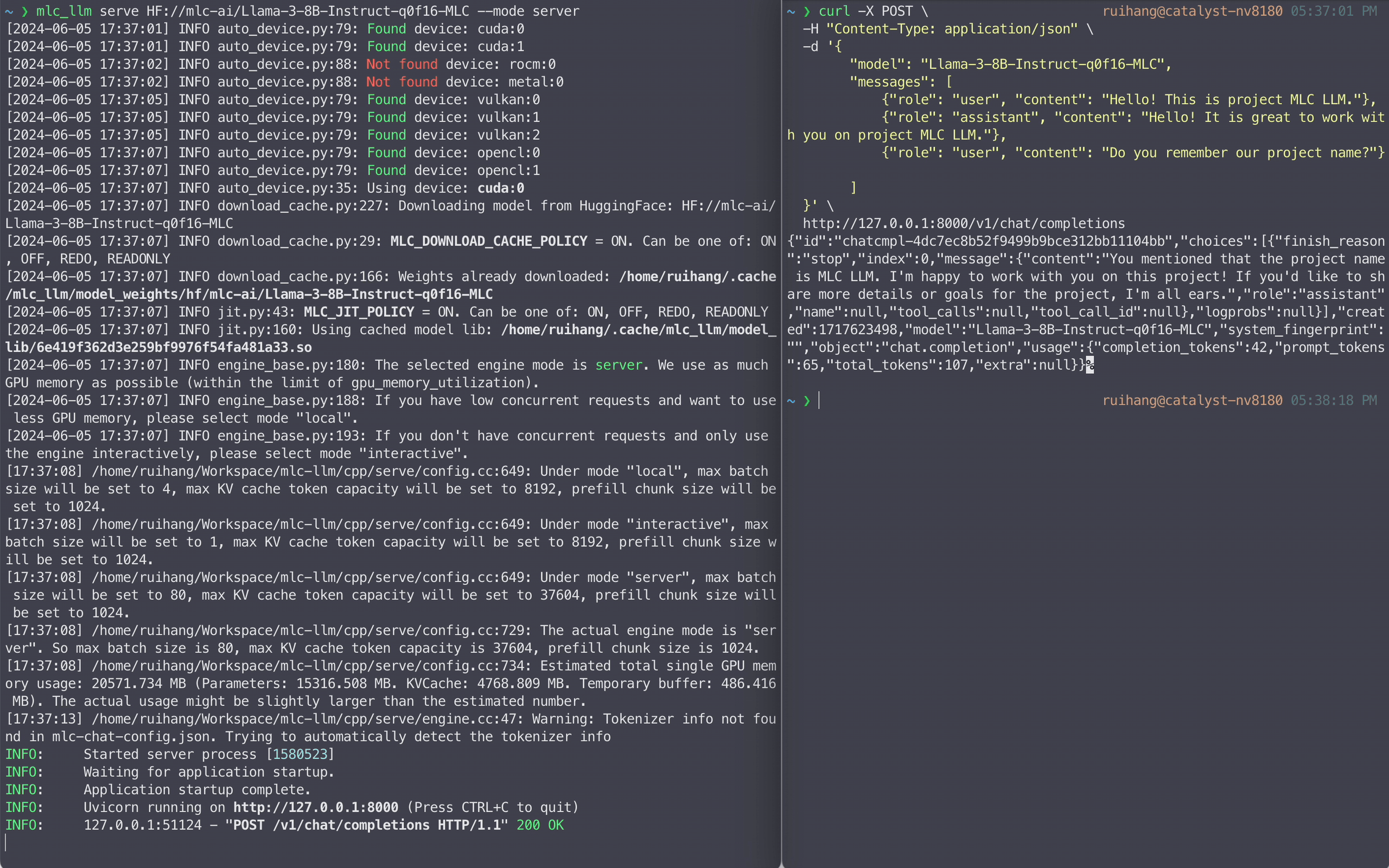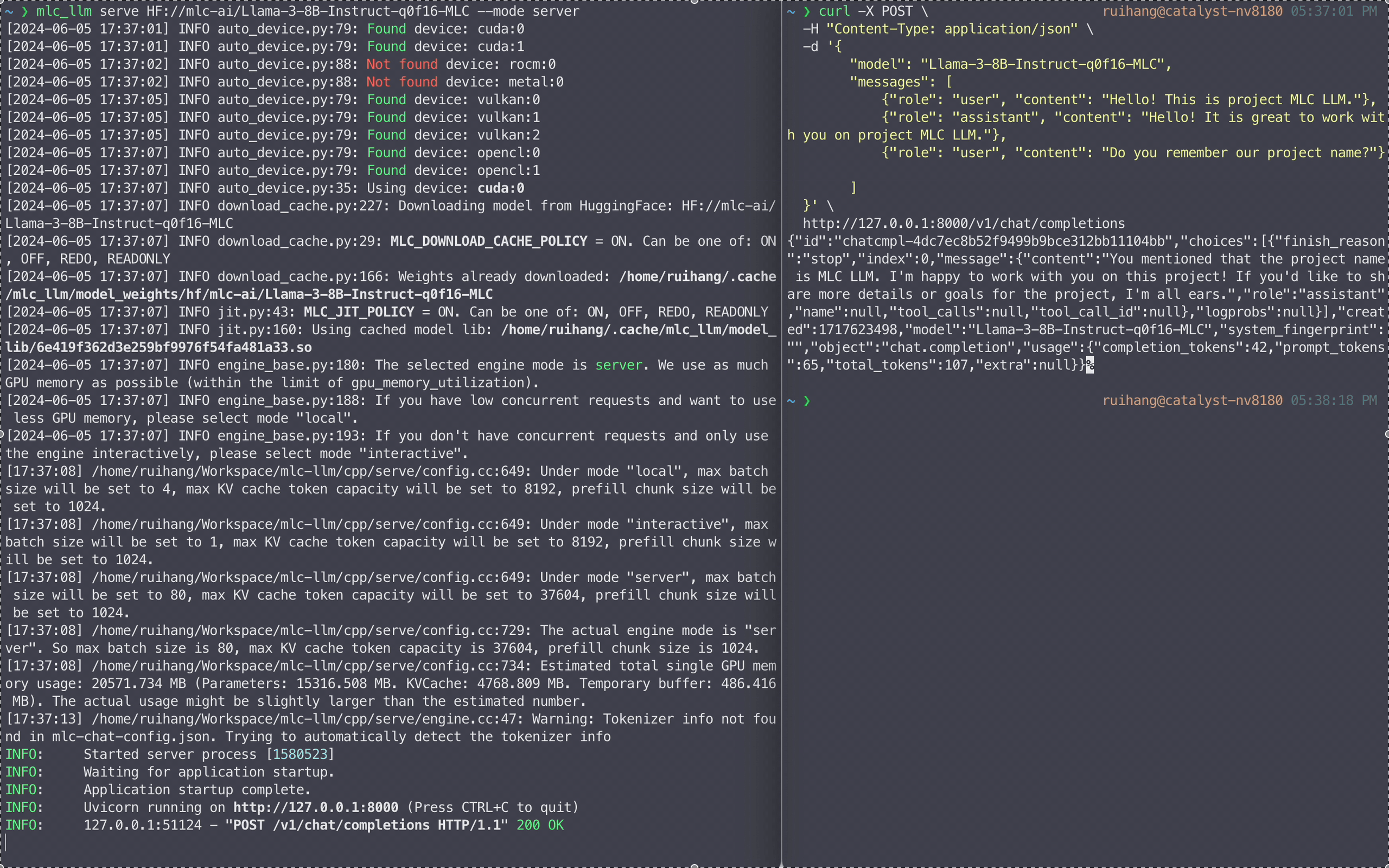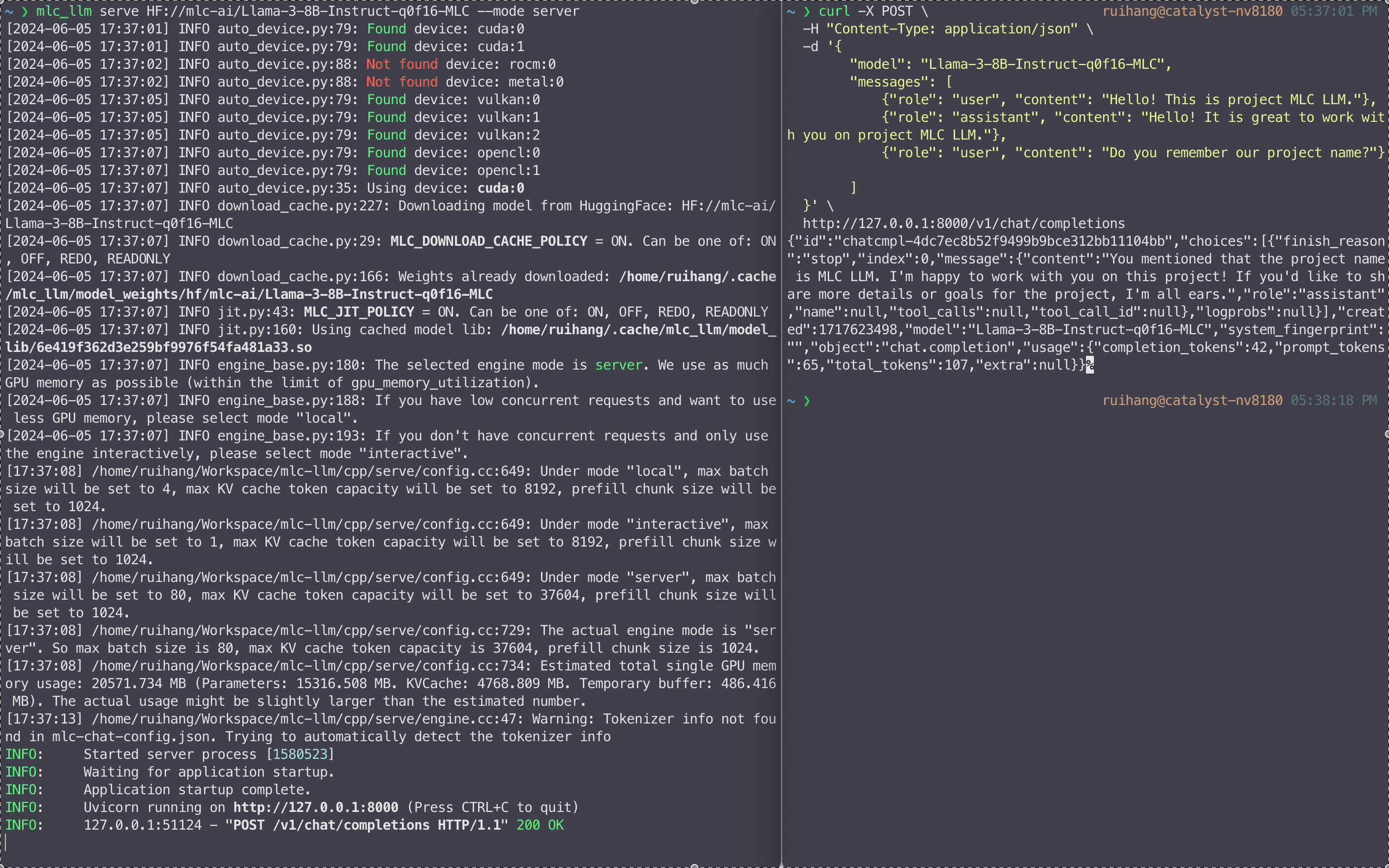
To accommodate different serving scenarios, we offer three modes for the server: “server,” “local,” and “interactive.” The “server” mode maximizes GPU memory usage and supports higher concurrency, while “local” and “interactive” modes limit the number of concurrent requests and use less GPU memory. We recommend using “server” mode with dedicated server GPUs such as A100/H100, leveraging full FP16 models and FP8 variants. For local environments, “local” mode and 4-bit quantized model settings are advisable.
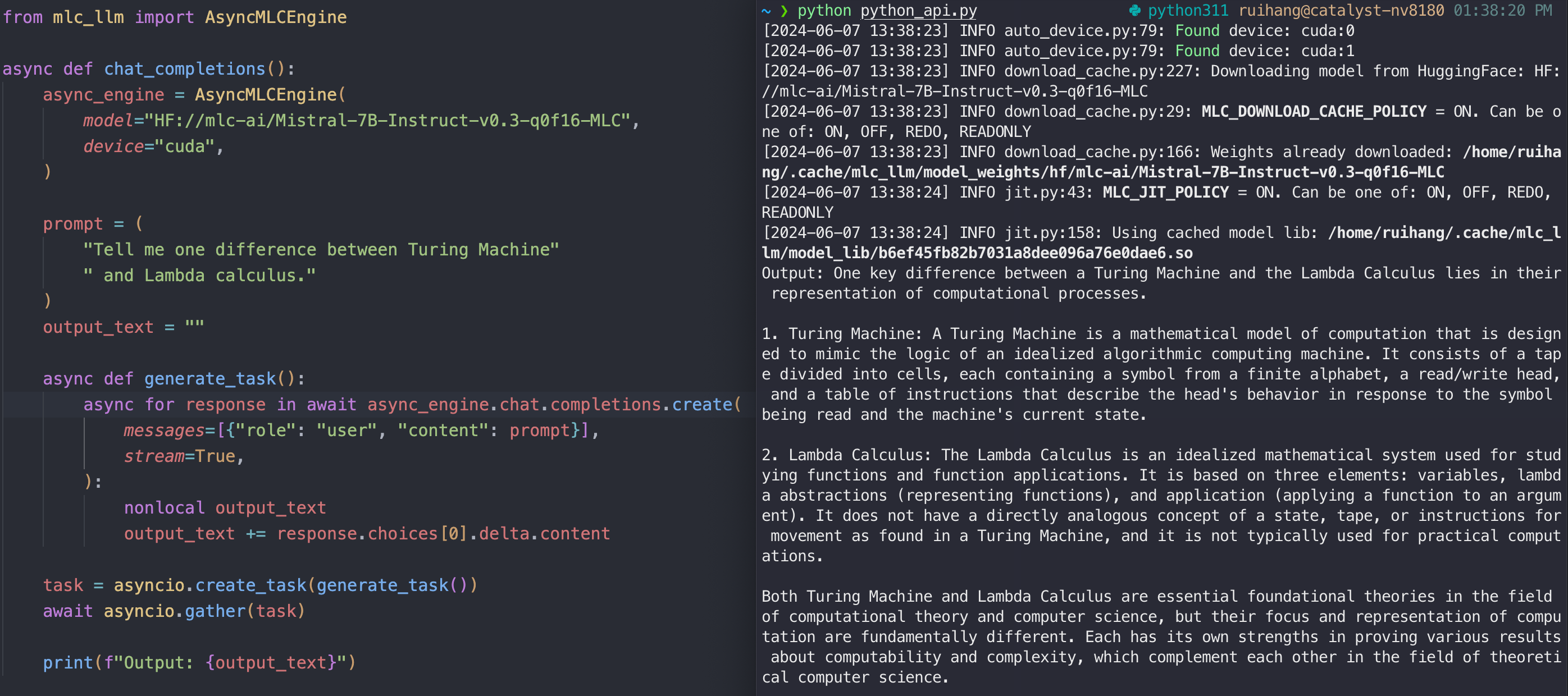
Python API
MLC LLM provides the MLCEngine and AsyncMLCEngine in Python for synchronous and asynchronous LLM generation respectively. Both engines support the same API as the OpenAI Python package.
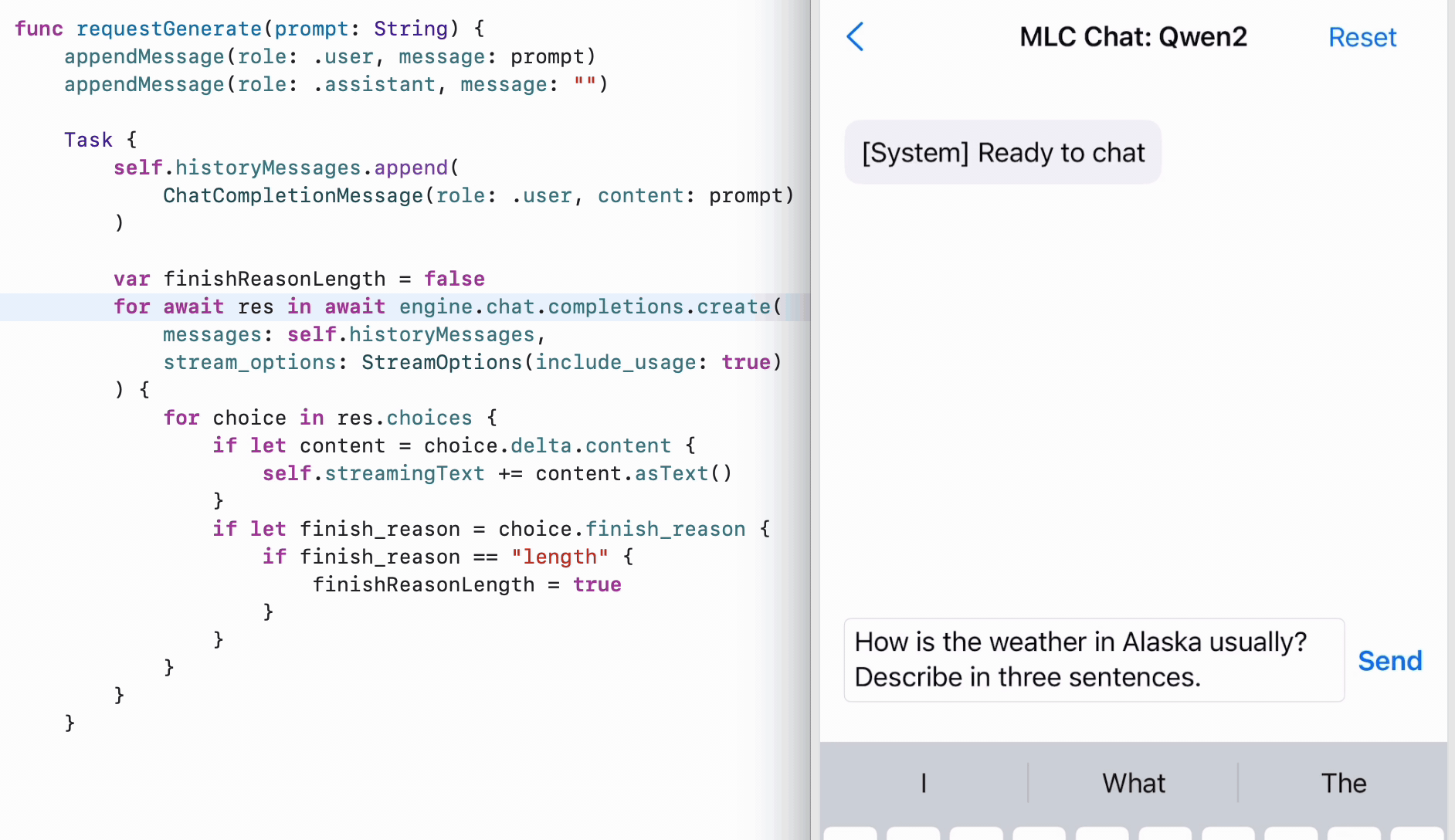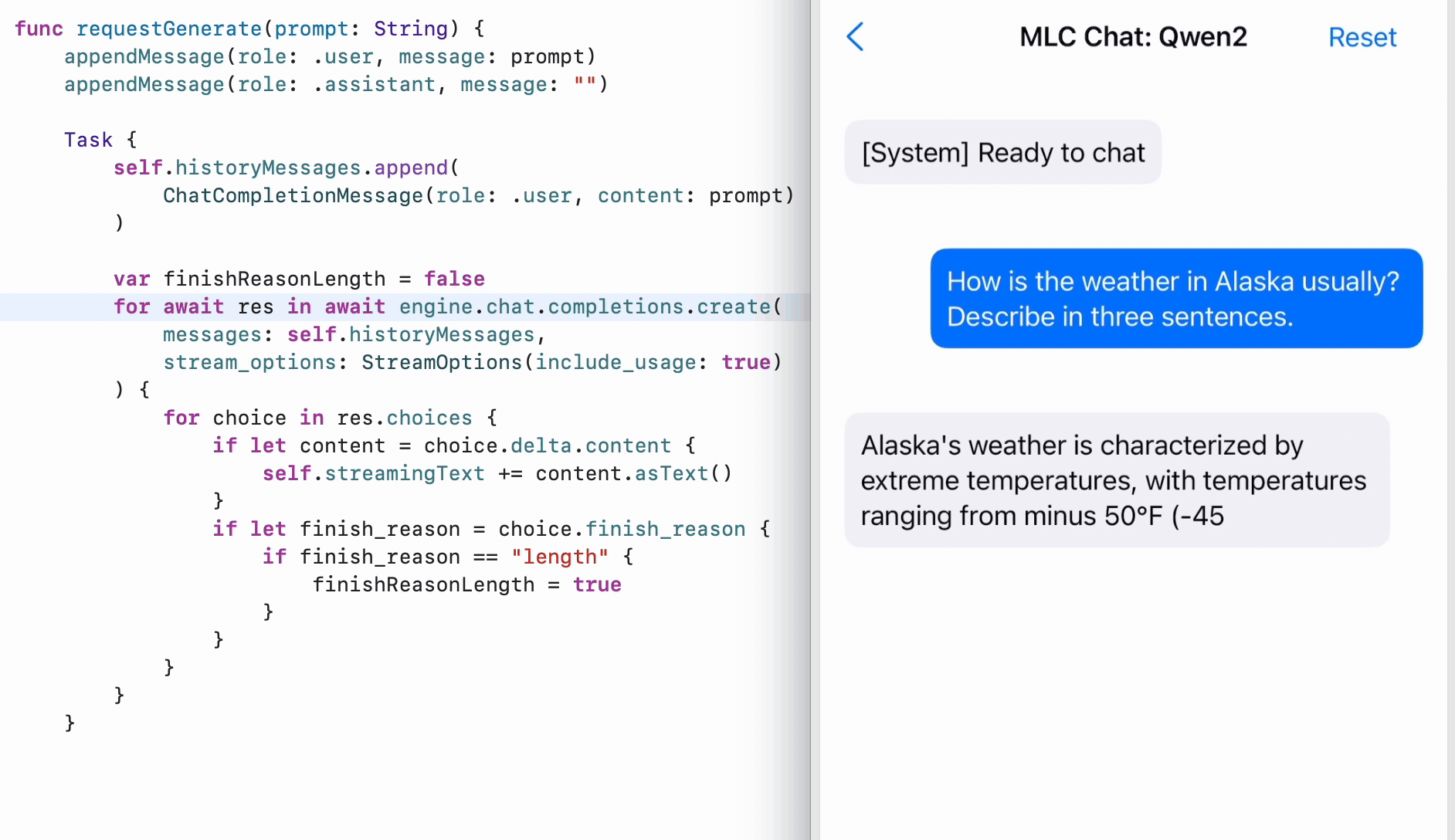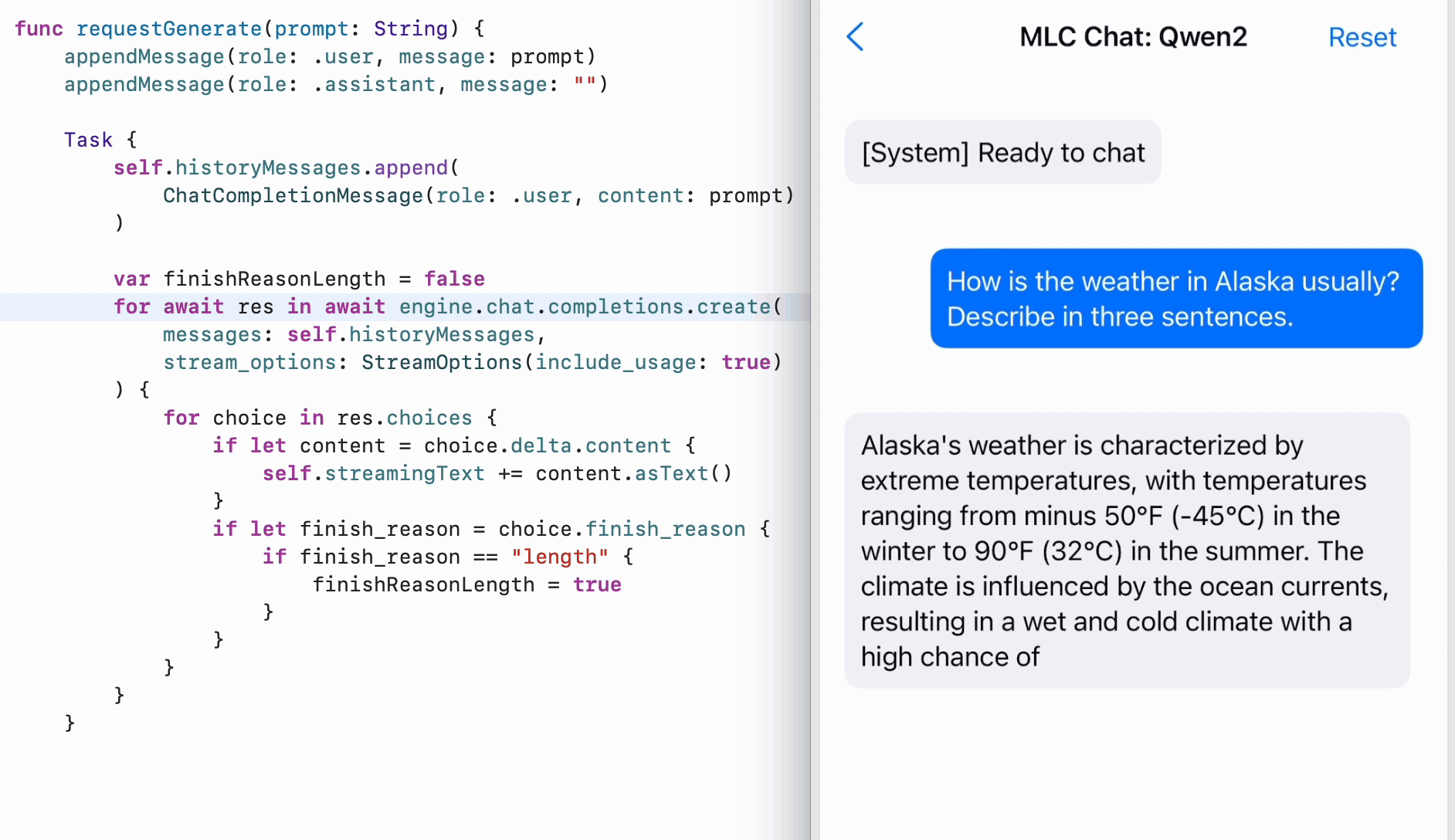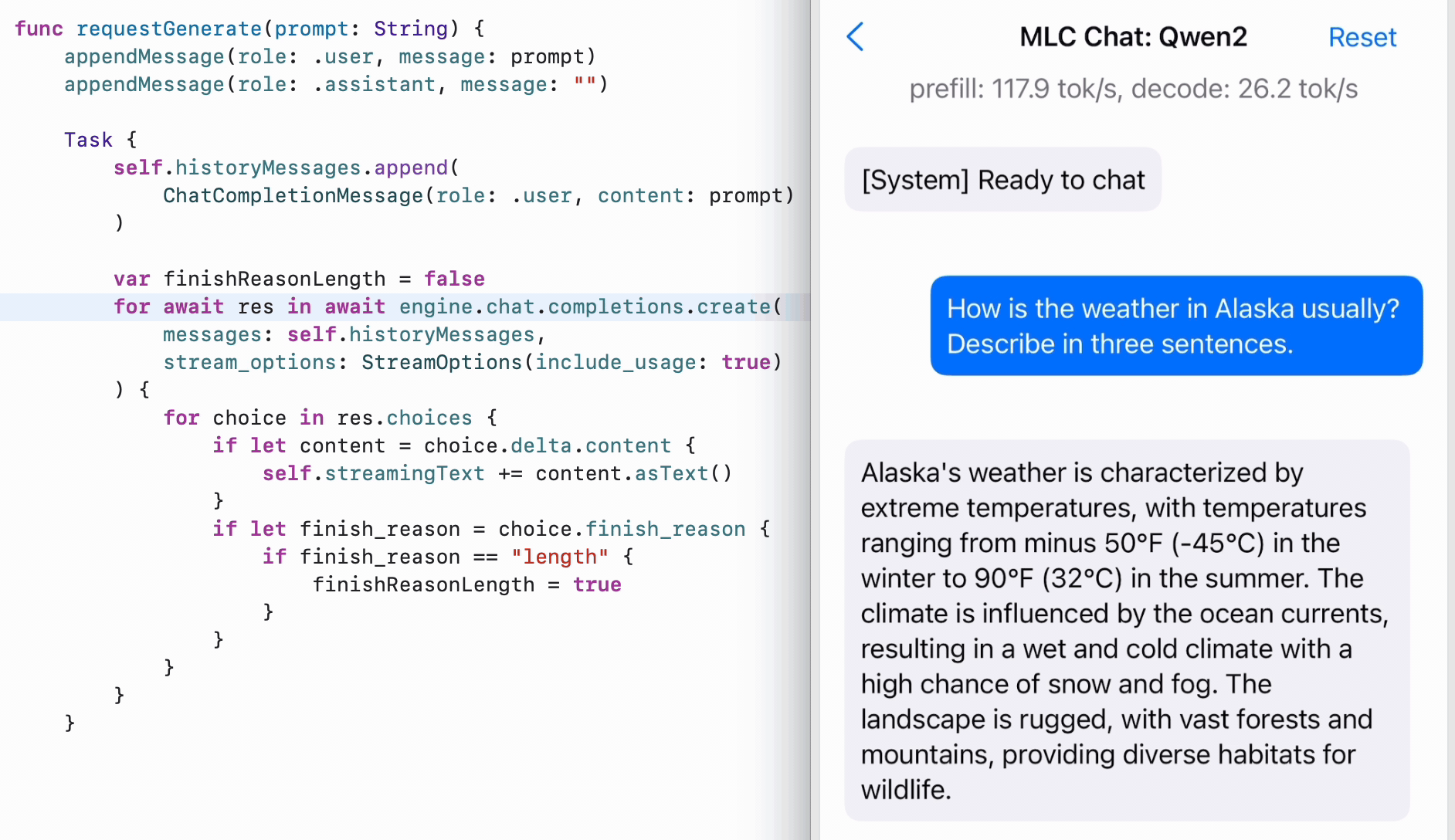
iOS SDK
To enable LLMs running on iPhone and iPad, we expose MLCEngine in our Swift SDK. While there is no official Swift API from OpenAI, we closely model it after the Python API, so we can find the code mirroring Python’s, with structured input and output. The Swift API also makes effective use of AsyncStream to enable asynchronous streaming of generated contents.
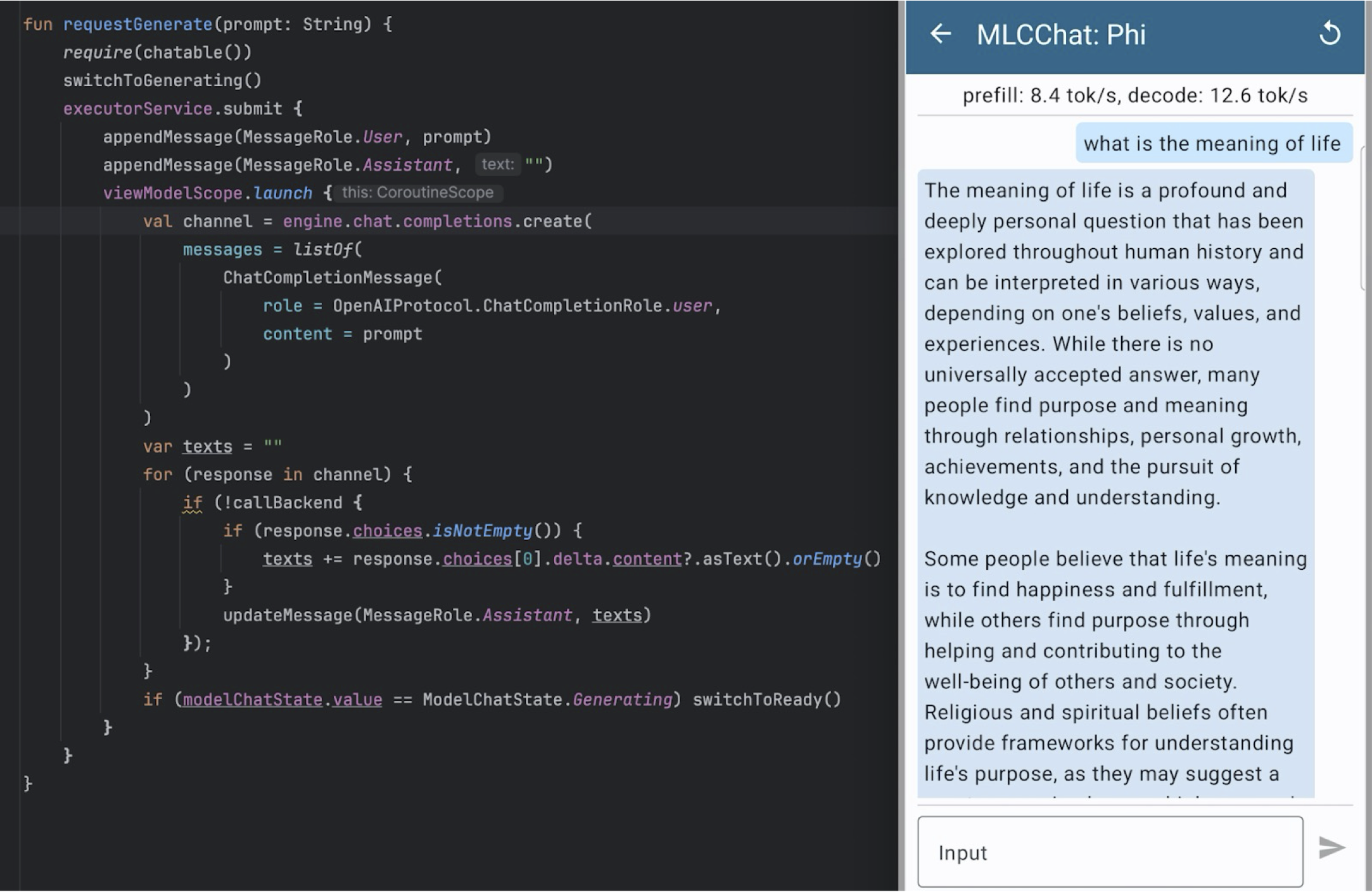
Android SDK
Besides iOS, we would also like to provide the same experience for Android. We chose to bring a Kotlin API modeled after the OpenAI API. Below is an example of running the 4-bit quantized Phi-3 model on Samsung S23 using the chat completion Kotlin API and the MLC Chat app screenshot.
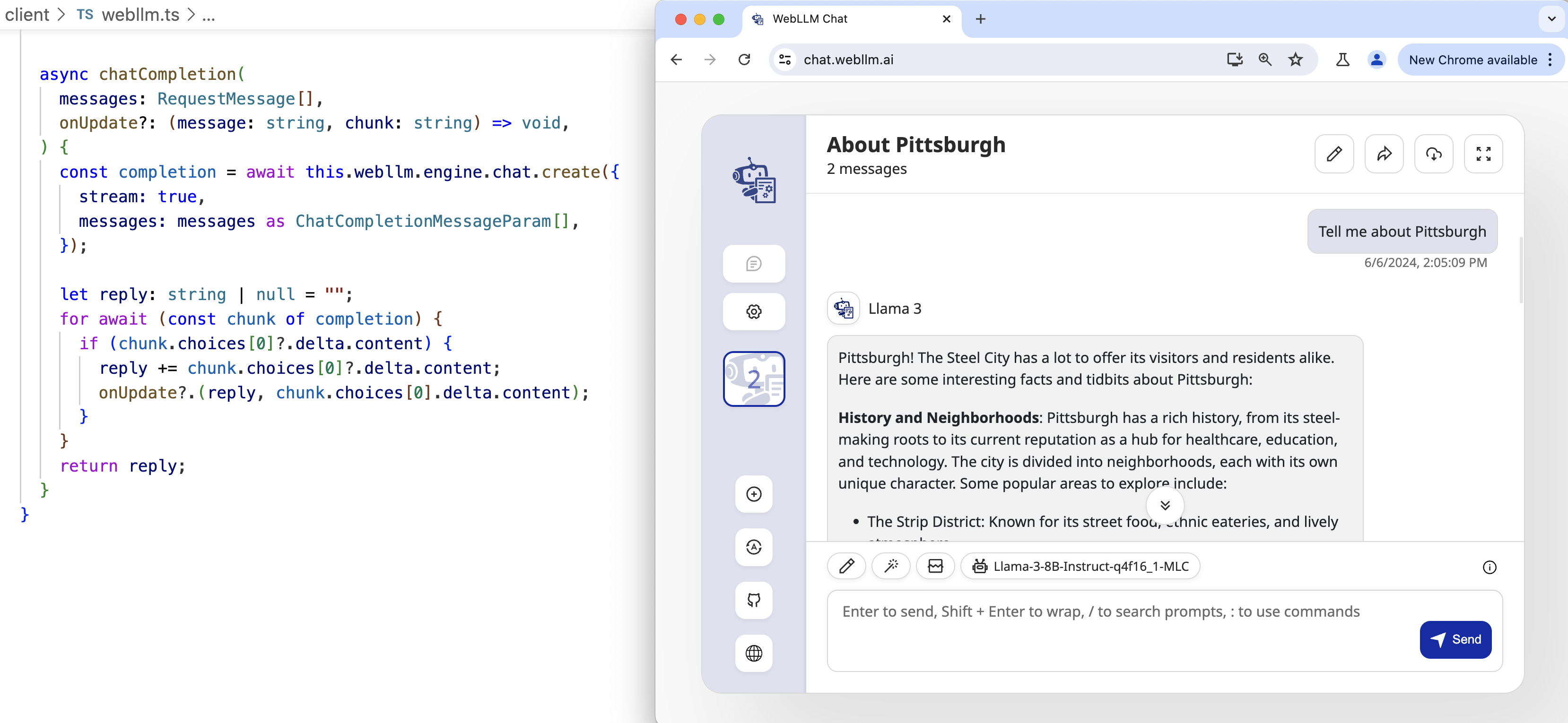
WebLLM SDK
We have been seeing the growing maturity of the WebGPU ecosystem in recent years. WebGPU works by translating WGSL (WebGPU Shading Language) shaders to native GPU shaders. This enables the possibility of executing in-browser GPU computation, which is fast (native GPU acceleration), convenient (no need for any environment setup), and private (100% client-side computation). MLCEngine is also accessible in JavaScript through the WebLLM project.
Discussions
One thing we might realize is that these APIs follow the exact same style engine.chat.completions.create so we can have the same development experience across these platforms. We also make use of language local features as much as possible to create structured inputs and outputs and enable async streaming so engine activities do not block the UI.
Efficient Structured Generation
Besides building chat applications, we would also enable applications beyond chat. Structured generation of LLMs greatly improves the abilities of LLMs, going beyond the basic chat or plain text generation. With controllable structured generation, LLMs become able to serve as standard tools and can be better integrated into other applications in production. JSON, among all structured formats, is the most widely used standard format in various scenarios, and it has great significance for LLM engines to support structured generation of JSON strings.
MLCEngine offers state-of-the-art JSON mode structured generation. For each request, MLCEngine runs and maintains a high-performance GrammarBNF state machine which constrains the response format during the auto-regressive generation.
MLCEngine supports two levels of JSON mode: general JSON response and JSON schema customization. The general JSON mode constrains the response to conform to JSON grammar. To use the general JSON mode, pass argument response_format={"type": "json_object"} to chat completion. Below is a request example with JSON mode:
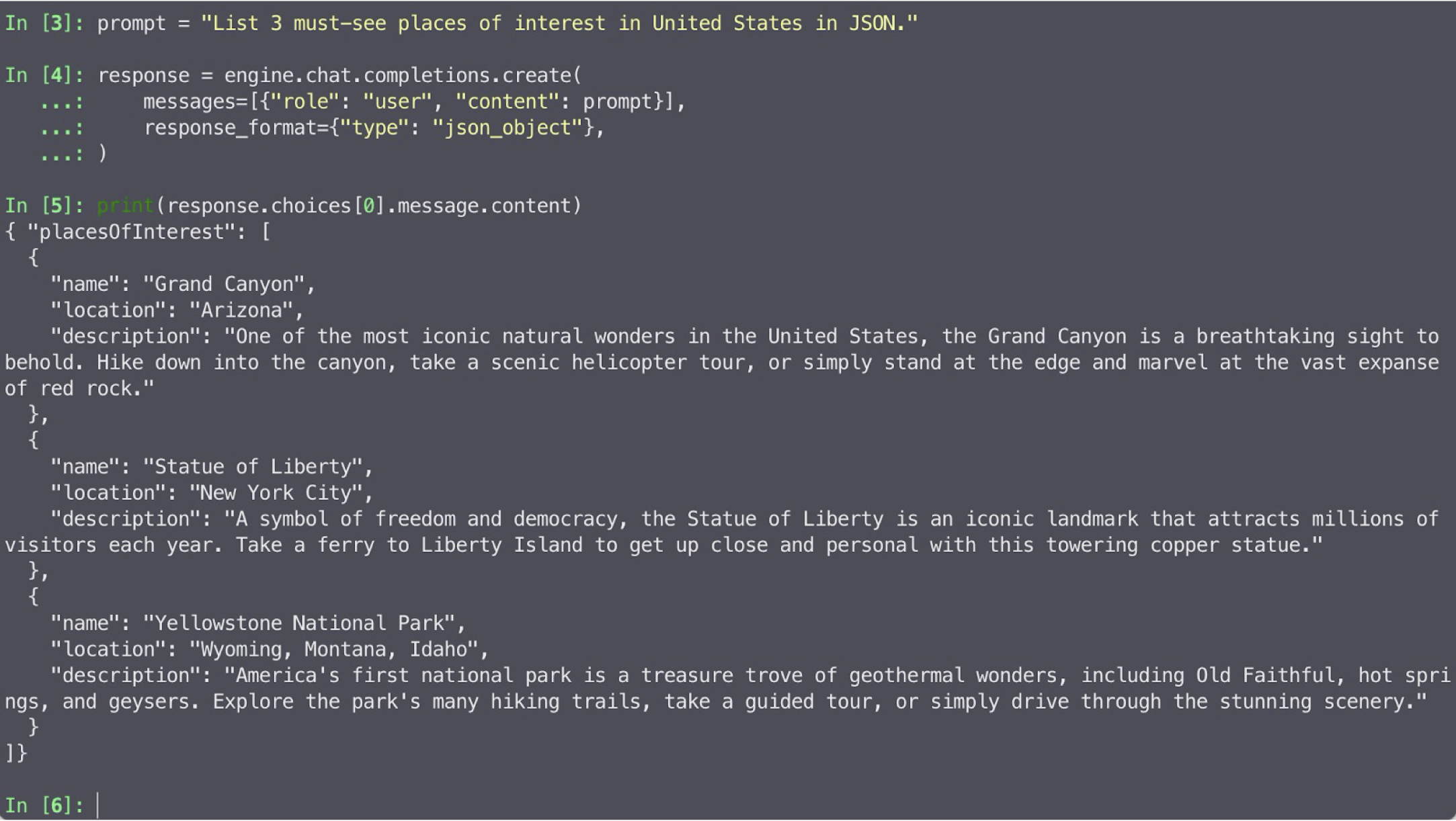
Additionally, MLCEngine allows for the customization of the response JSON schema for each individual request. When a JSON schema is provided, MLCEngine will generate responses that adhere strictly to that schema. Below is a request example with customized JSON schema:

Importantly, the structured generation support is built into the engine, which means it can be used across all the API platforms that MLCEngine supports.
Make LLMs Accessible on Diverse Platforms
One of our missions is to make LLM accessible on a diverse set of platforms. We have already discussed the use cases on server GPUs, Android, and iOS. We validated that MLCEngine is runnable under a diverse range of platforms. Including, but not limited to:
- NVIDIA RTX 4090,
- NVIDIA Jetson Orin,
- NVIDIA T4 (in Google Colab),
- AMD 7900 XTX,
- Steam Deck,
- Orange Pi.
Among these, the steam deck is a fun one because it only comes with limited GPU driver support. We generated code for Vulkan, which runs a Llama3-8B model on it.
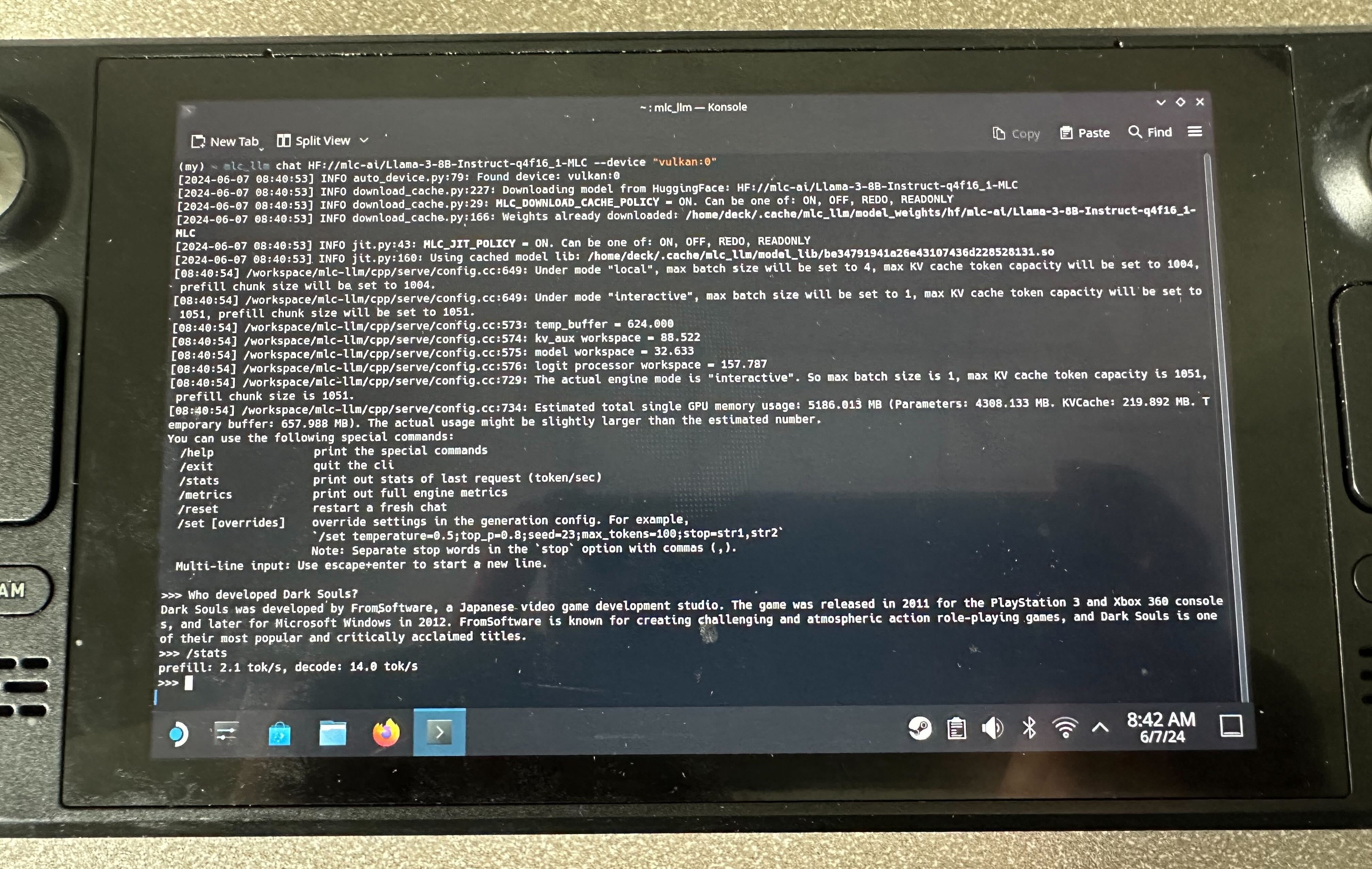
We find machine learning compilation helping us reduce the amount of engineering effort in building up MLCEngine and helping us bring high-performance solutions on a broader range of hardware, making these models accessible to more people.
Optimizing Engine Performance
While this is the first release milestone of MLCEngine, we have put a lot of effort into optimizing its performance. The engine combines several key system improvements such as continuous batching, speculative decoding, paged KV management, common prefix caching, and cascade inference. We leverage the FlashInfer library to compute fast attention on CUDA platforms and broaden its support to a wider range of platforms via compiler code generation.
MLCEngine supports multi-GPU out of the box. The following command launches a REST server on two GPUs:
mlc_llm serve HF://mlc-ai/Qwen2-72B-Instruct-q0f16-MLC --overrides "tensor_parallel_shards=2"
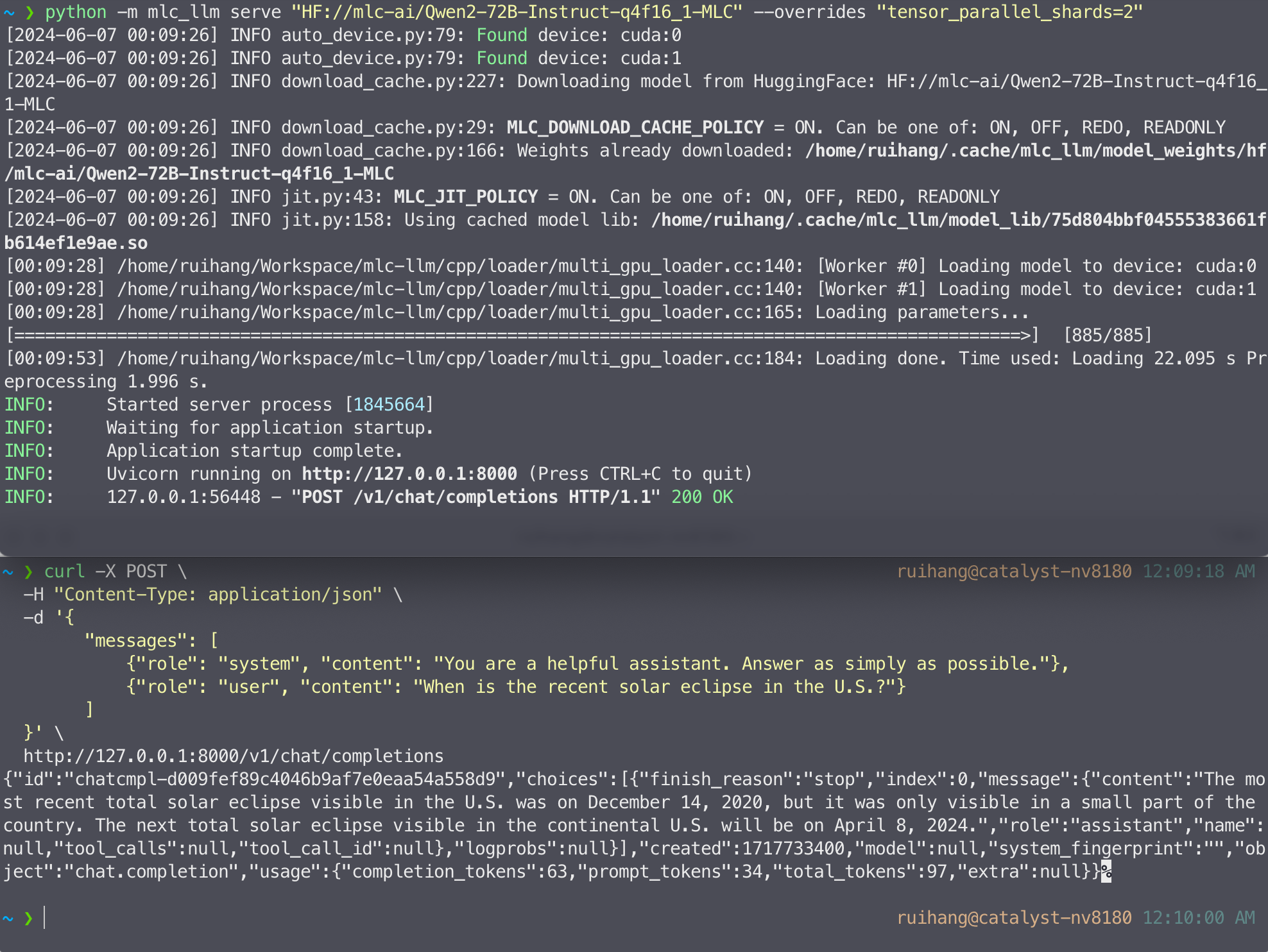
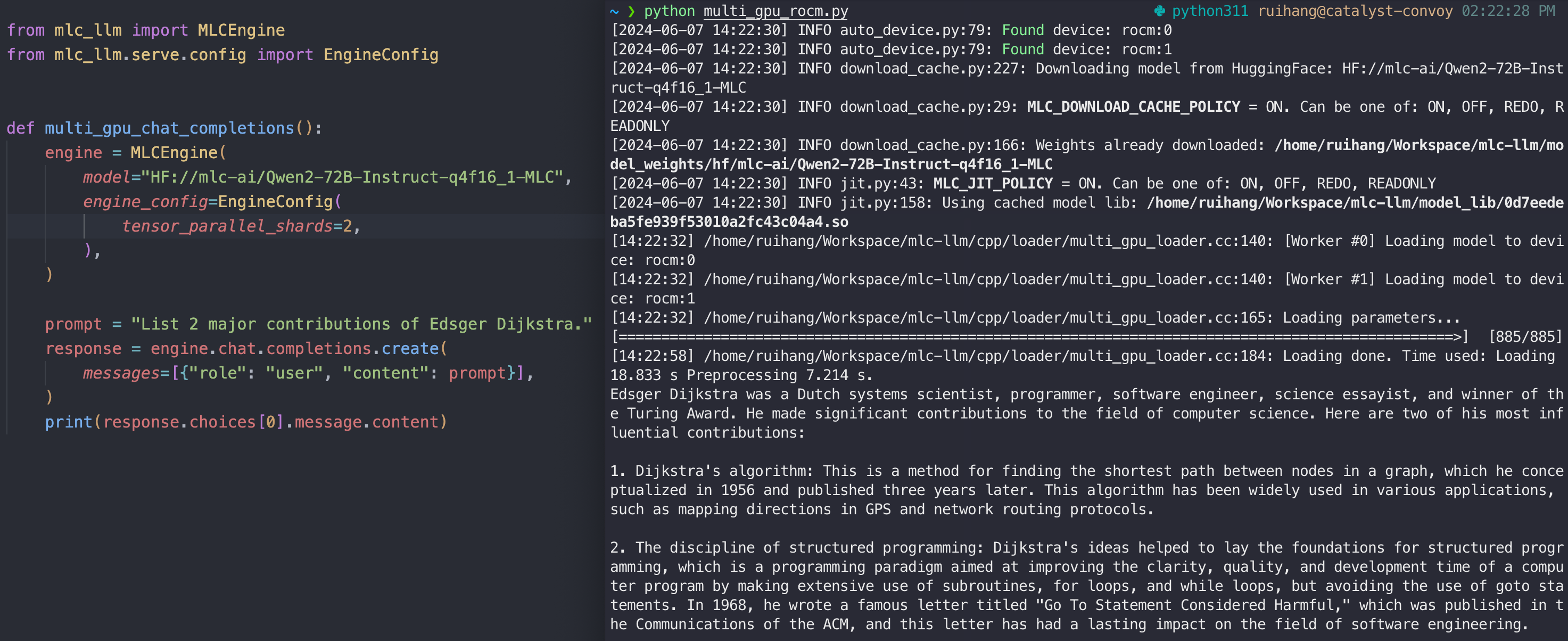
MLCEngine can achieve highly competitive performance on server use cases, especially on high-throughput low-latency settings, with strong scaling to multiple GPUs. We also maintain state-of-the-art performance on platforms such as Apple GPUs while enabling emerging platforms such as WebGPU.
Importantly, we find a lot of synergy in building a unified solution across platforms. For example, having the same engine allows us to bring advanced optimizations such as attention management, prefix caching, speculative execution, and structured generation to go across these platforms, where our past solutions lacked support due to limited engineering bandwidth. We can also transfer knowledge of optimizations across platforms, by leveraging code generation. Our performance of WebGPU highly benefits from optimizations on local GPU runtime, which then gets directly compiled to target WebGPU environments.
Summary
We introduced MLCEngine, a unified efficient LLM engine that can run LLMs everywhere on different hardware and platforms, from cloud servers to edge devices. This marks a new chapter of the MLC LLM project. We love to work with the community to bring more improvements, including bringing better model coverage, more system optimizations, and advanced machine learning compilation to enable even more productive universal deployment.
This project is made possible by many contributions from the open-source community, including contributions from CMU Catalyst, OctoAI, UW SAMPL, SJTU, and the broader MLC community. We plan to continue working with the open-source community to bring open foundational models for everyone.
To try out MLC LLM or learn more about it, please check out our documentation: