Introduction
We are in an exciting year of generative AI. Open large language models bring significant opportunities to offer customization and domain-specific deployments. While most LLMs run on servers/cloud, there are promising opportunities for running capable models locally.
Web browsers form a universally accessible platform, allowing users to effortlessly engage with any web applications without installation processes. Wouldn’t it be amazing to bring open language models directly into browsers, enabling anyone to run LLMs locally just by opening a webpage?
In this post, we introduce the WebLLM engine (WebLLM for short), a high-performance in-browser LLM inference engine. WebLLM engine is a new chapter of the MLC-LLM project, providing a specialized web backend of MLCEngine, and offering efficient LLM inference in the browser with local GPU acceleration. WebLLM is fast (native GPU acceleration), private (100% client-side computation), and convenient (zero environment setup). The figure below shows how we can use WebLLM API to build WebLLM Chat, a fully private chat application that runs locally in-browser. The same API can enable more cases, such as text summarization, Q&A over local documents, and building in-browser web agents.
To integrate efficient LLM execution into the browser, we must address several key challenges. We need to: (1) offer efficient GPU acceleration; (2) provide a standardized API that web app developers can easily incorporate into their flow; and (3) effectively separate the backend execution to prevent any disruption to the UI flow. We discuss each below.
To enable GPU acceleration, WebLLM leverages WebGPU and WebAssembly. WebGPU is the new W3C standard to run GPU code directly in the browser. It is integrated into major browsers such as Chrome, Edge, and Firefox, with all browsers set to support the standard. Browsers support WebGPU by translating WGSL (WebGPU Shading Language) shaders to native GPU shaders, allowing web applications to enjoy GPU acceleration while unifying different backends (e.g. Macbook, NVIDIA laptop, Android phone). Unlike popular platforms like NVIDIA, WebGPU is an emerging platform and does not have accelerated GPU libraries. Thus, we leverage MLC LLM to compile efficient WebGPU kernels and embed them into a WASM library, which then works with the WebLLM runtime to handle LLM executions in the browser.
The WebLLM engine features an OpenAI-API style interface for standardized integration, with support for chat applications as well as efficient structured JSON generation. Finally, we bring built-in support for Web Workers and Service Workers so the backend executions can run independently from the UI flow. WebLLM engine shares many optimization flows with MLCEngine, enabling state-of-the-art model support through machine learning compilation.
Overall Architecture
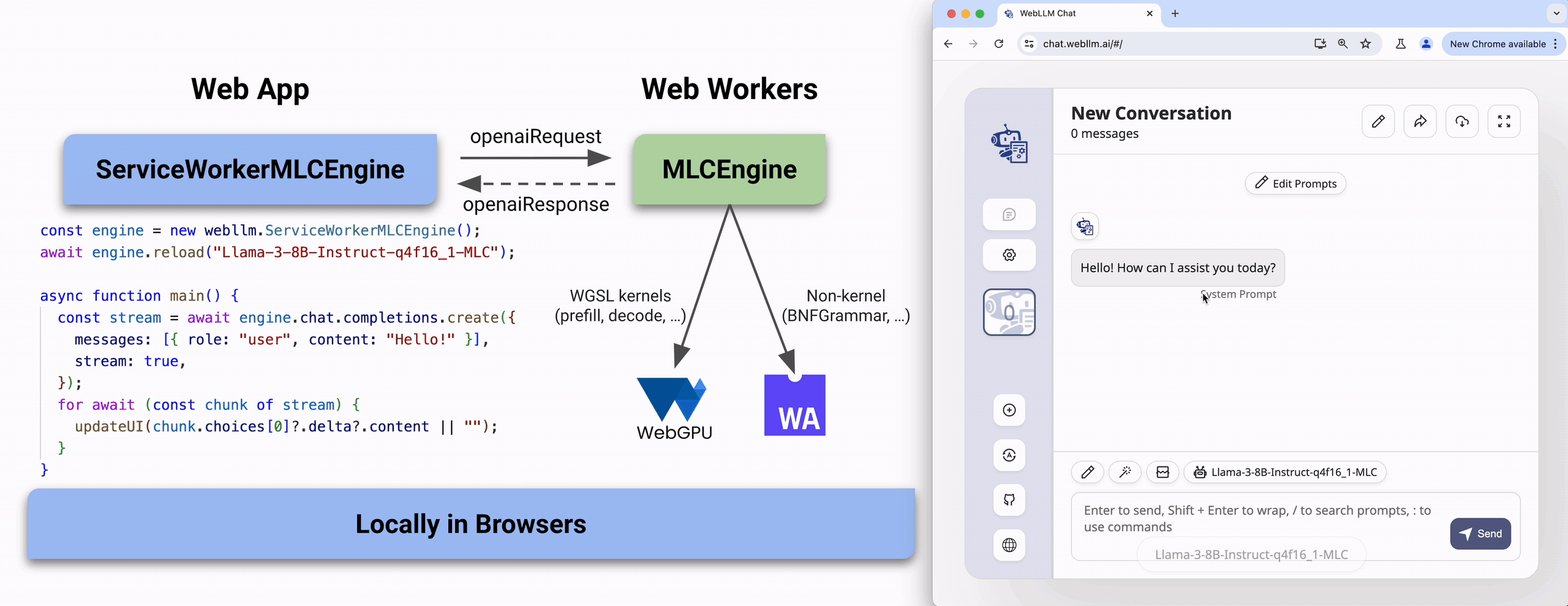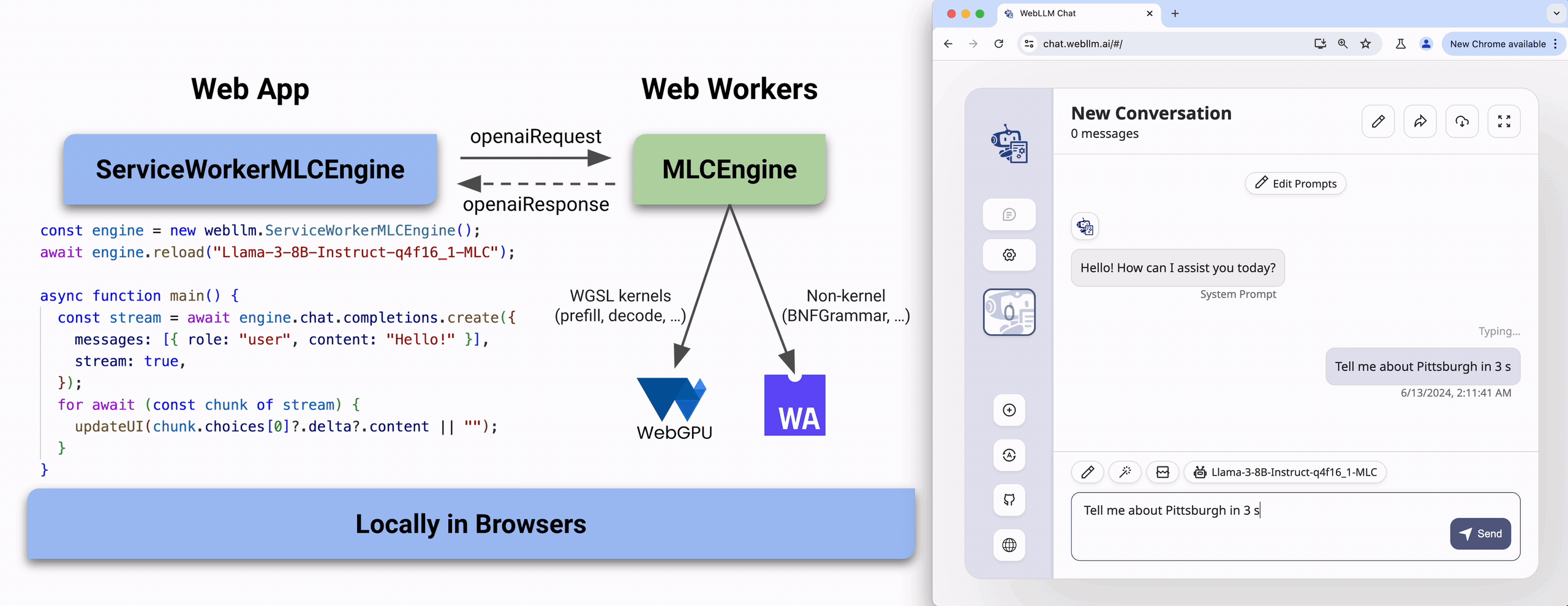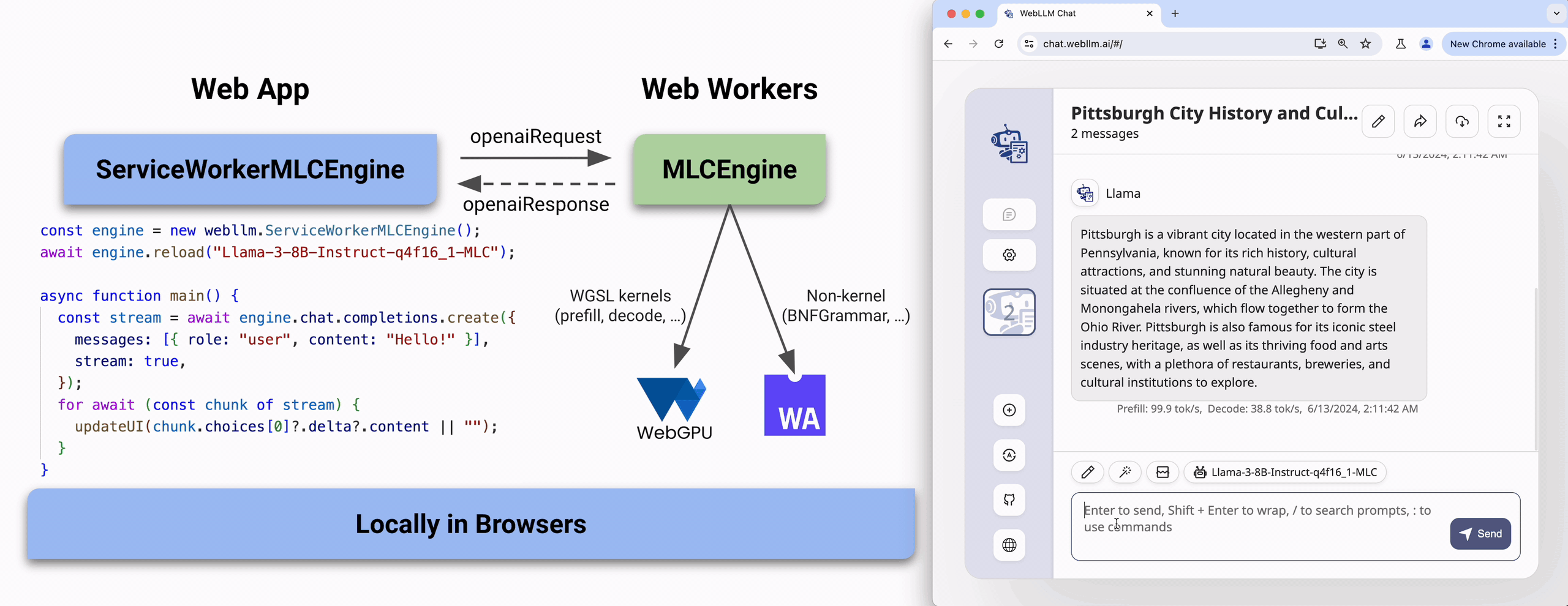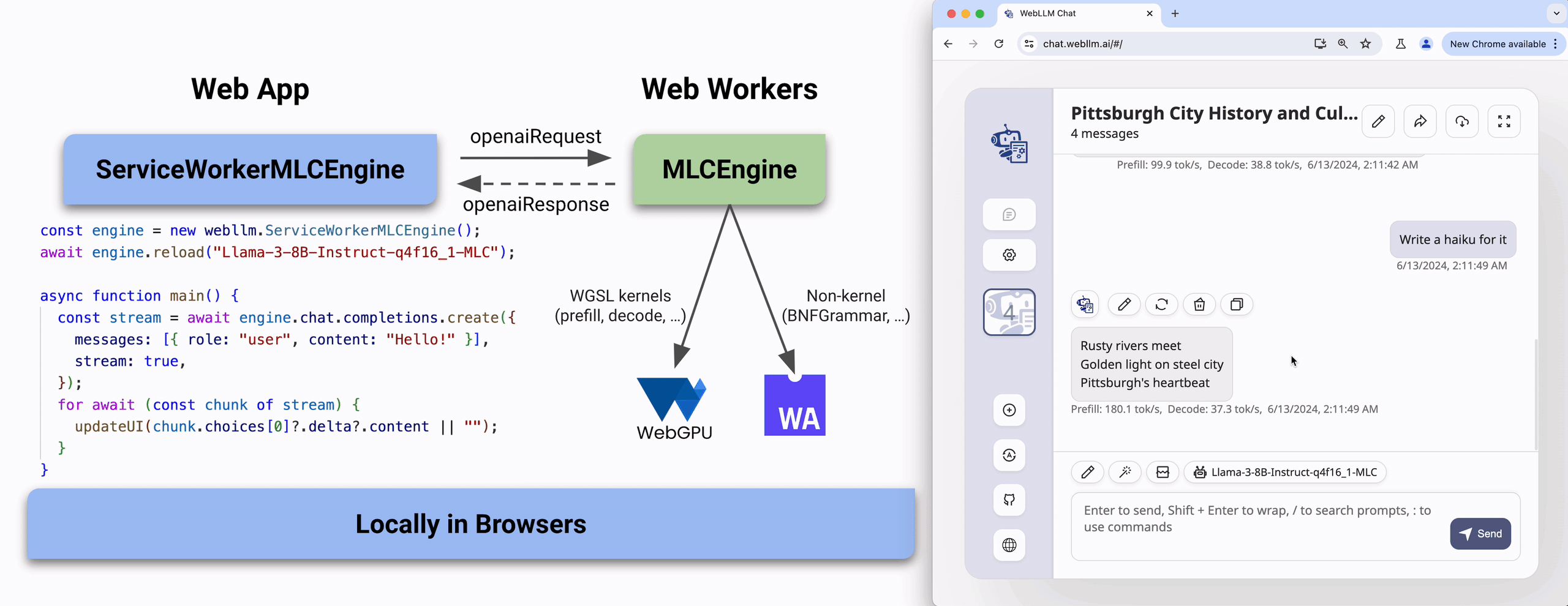
The architecture of WebLLM can be split into three parts, as shown in Figure 2. Web application developers only need to interact with the Web App part. (Note: We support both Service Worker and Web Worker, but will focus on the former in this post.)

Web App A web developer instantiates a ServiceWorkerMLCEngine in the web application frontend and treats it like an endpoint. The ServiceWorkerMLCEngine loads a model (e.g. Llama3, Phi3) when specified, takes in an OpenAI-style request at any time, and streams back the output. Simple!
Web Workers We hide all the heavy computation in the background thread through different kinds of Web Workers (e.g. Service Workers), simplifying web app development while ensuring a smooth user interface. Under the hood, the ServiceWorkerMLCEngine communicates with an internal MLCEngine in the worker thread via message-passing, forwarding the OpenAI-API request while getting responses streamed back. The MLCEngine loads the specified model, executes the WGSL kernels with WebGPU (which translates kernels to native GPU code), and runs non-kernel functions with WebAssembly. Everything happens inside the worker thread of the browser with near-native performance.
Compile time The model that the MLCEngine loads in is compiled ahead of time and hosted online. We leverage MLC-LLM and Apache TVM to compile any open-source model (e.g. Llama3, Phi3) into two components: converted/quantized model weights and a WASM library. The WASM library contains both compute kernels in WGSL (e.g. prefill, decode) and non-kernel functions in WebAsembly (e.g. BNFGrammar for JSON mode). WebLLM provides prebuilt models while allowing users to bring their own models. Note that the weights and wasm are downloaded once and cached locally.
Use WebLLM via OpenAI-style API
As we build an in-browser inference engine, it is important to design a set of APIs that developers are familiar with and find easy to use. Thus, we choose to adopt OpenAI-style API. Developers can treat WebLLM as an in-place substitute for OpenAI API – but with any open source models with local inference.
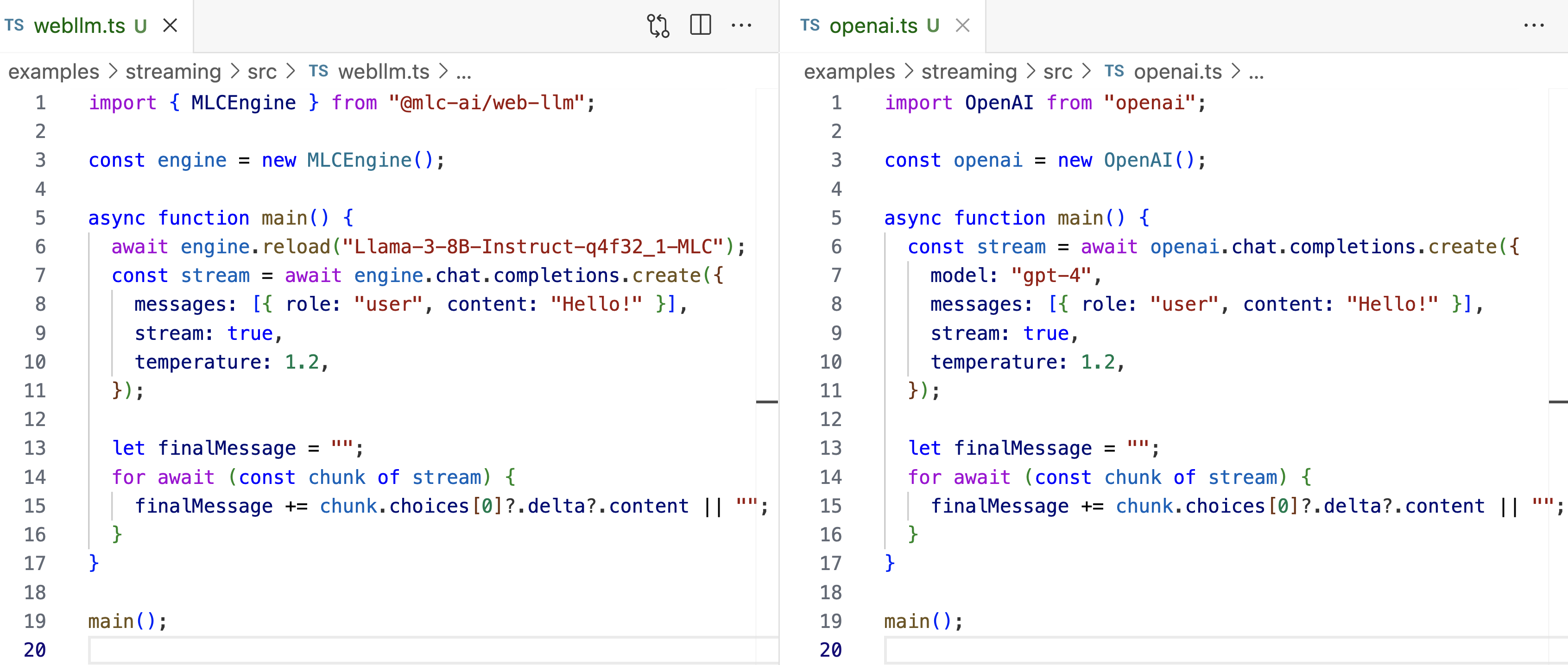
Just like OpenAI API, WebLLM supports streaming, logit-level control with logit_bias and logprobs, generation options such as temperature and frequency_penalty, and seeding for reproducible output.
That is, WebLLM not only matches OpenAI API by the look but also supports all OpenAI API’s capabilities for LLMs (as of June 2024).
Getting Started with MLCEngine in WebLLM
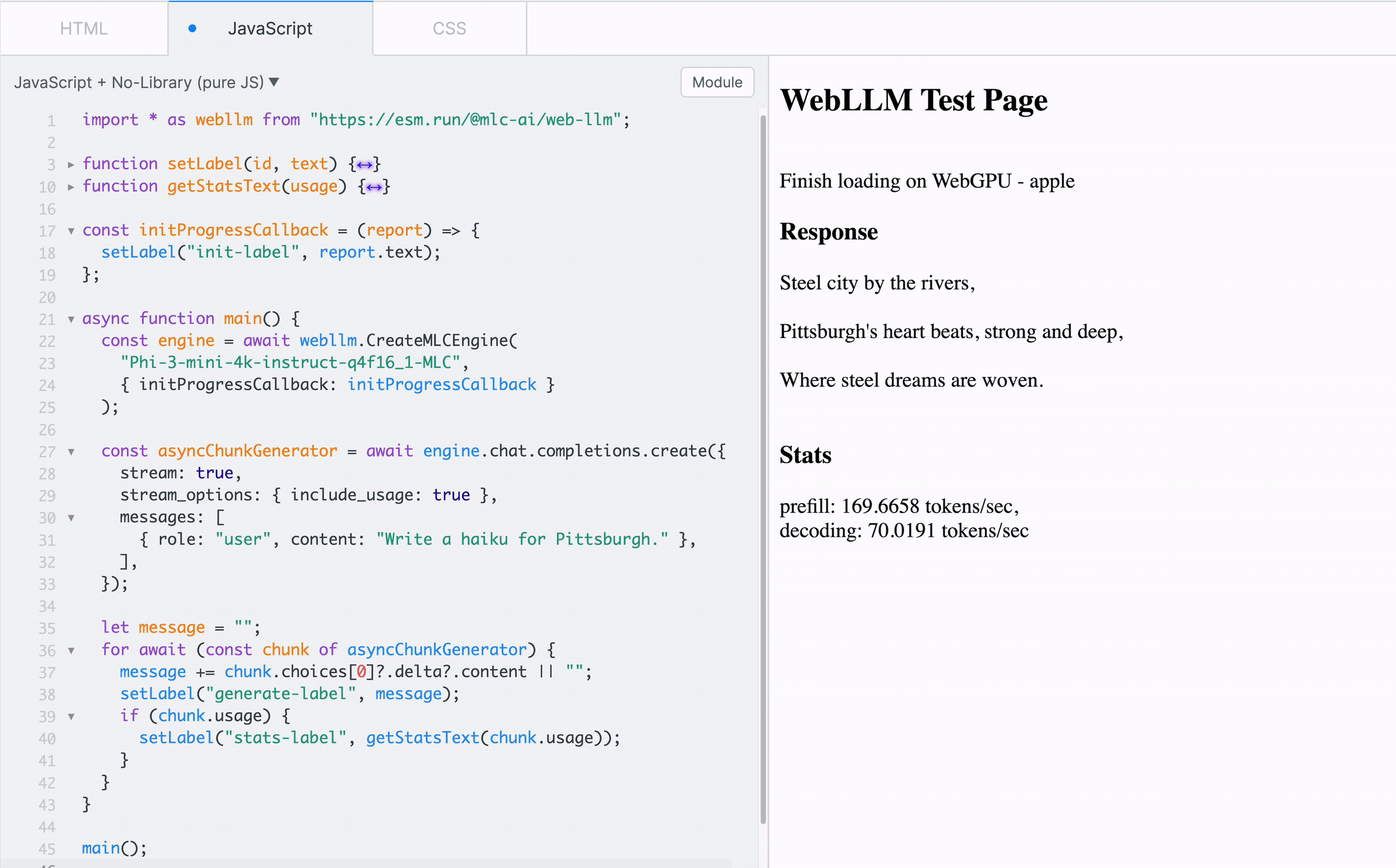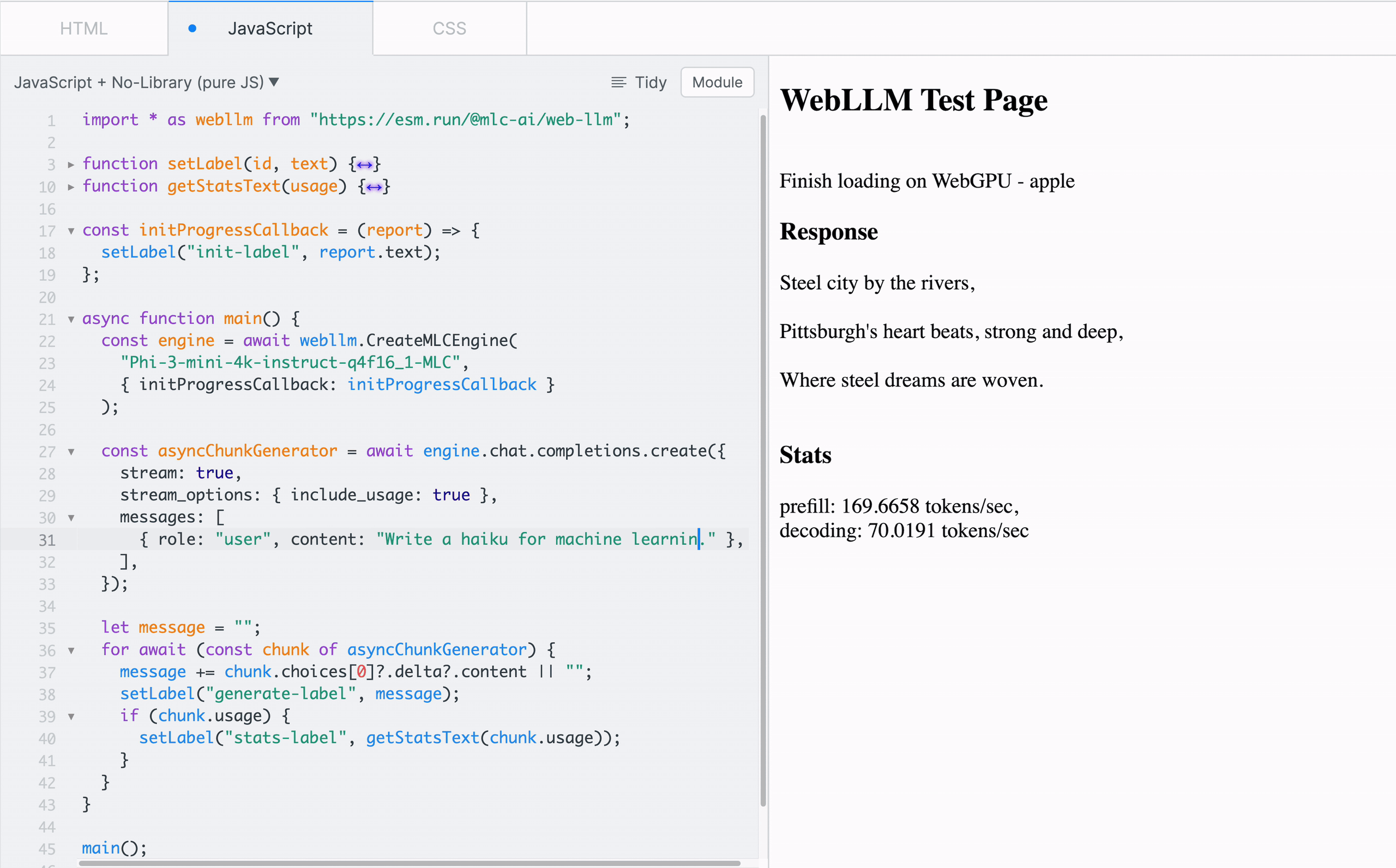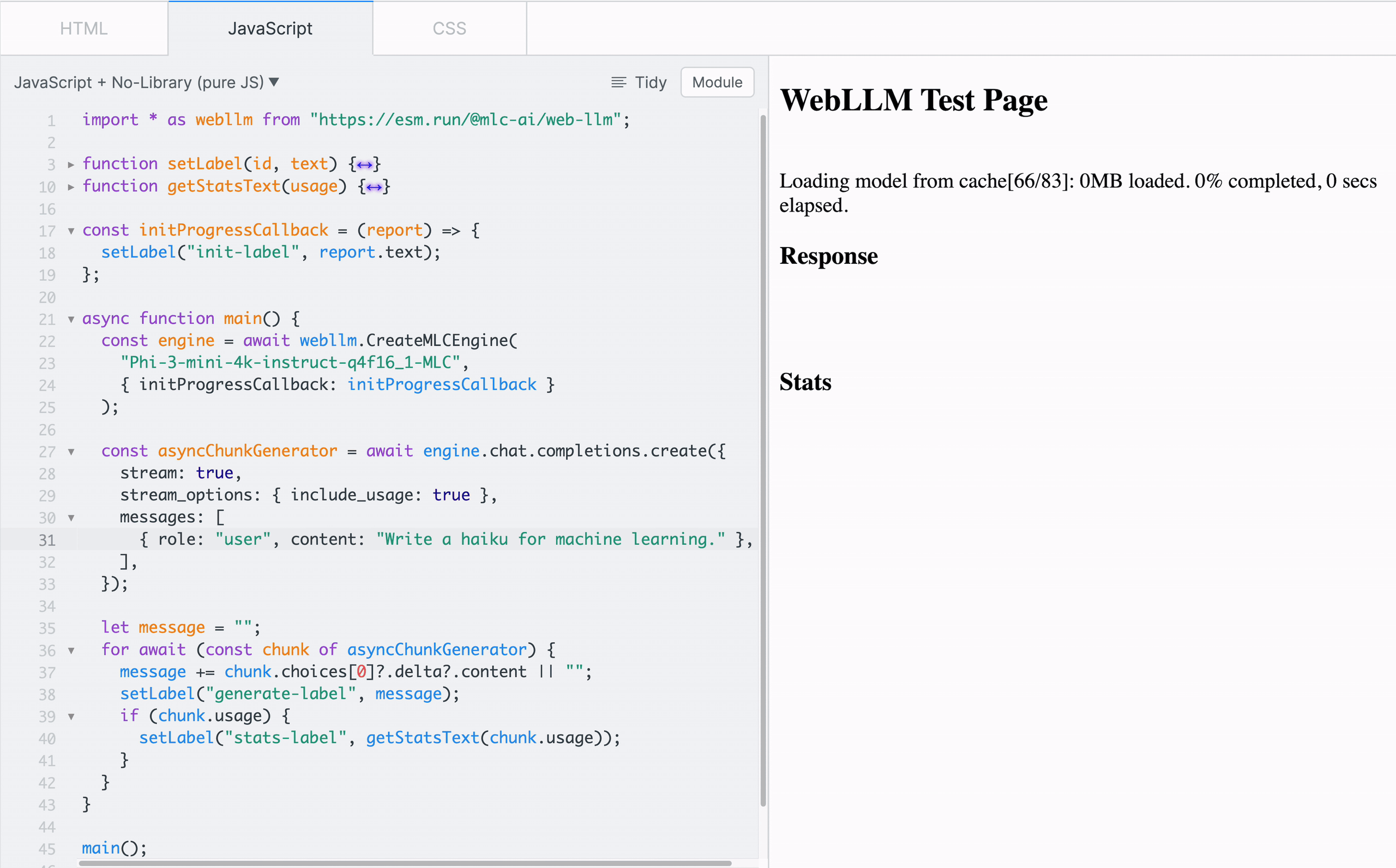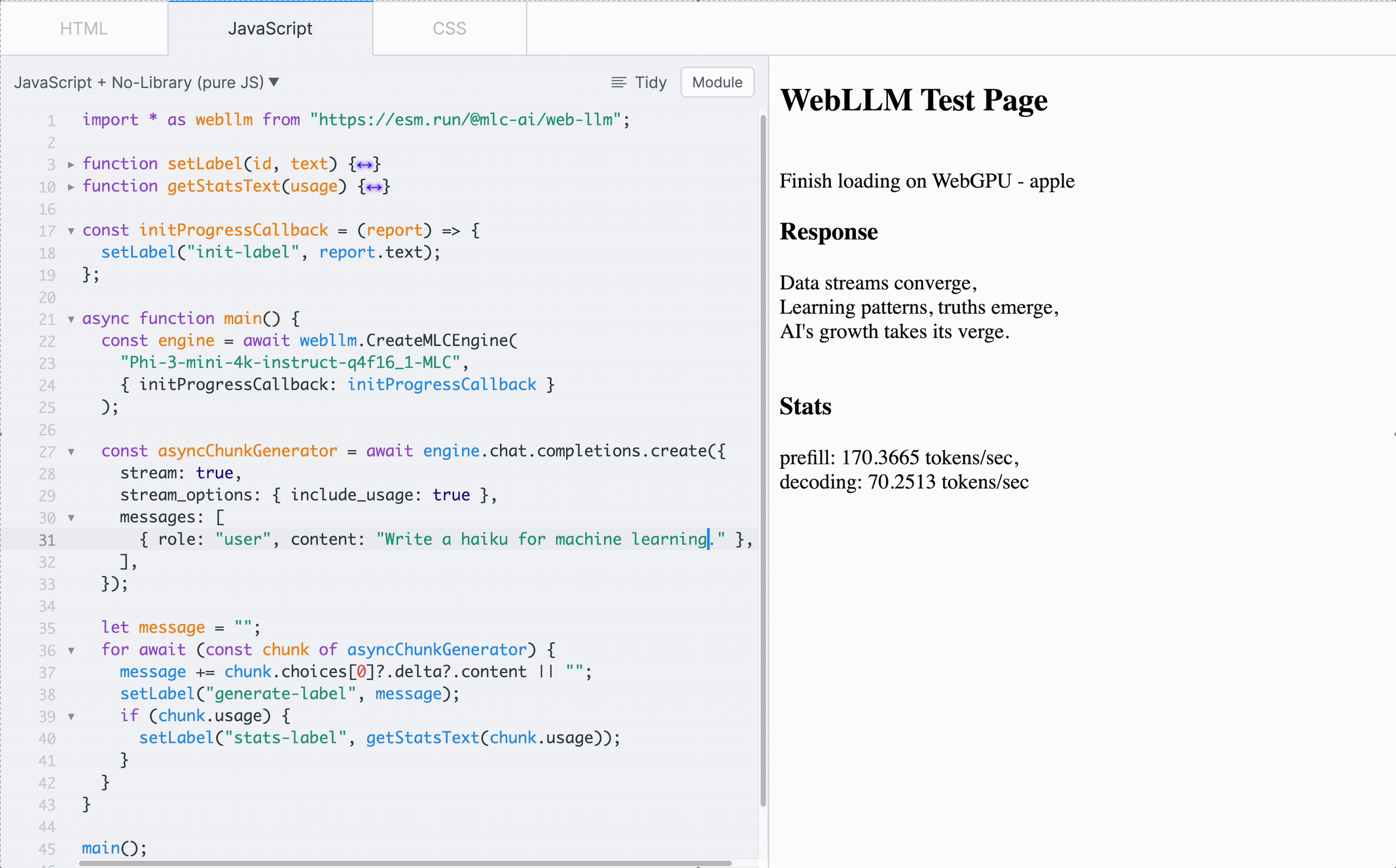
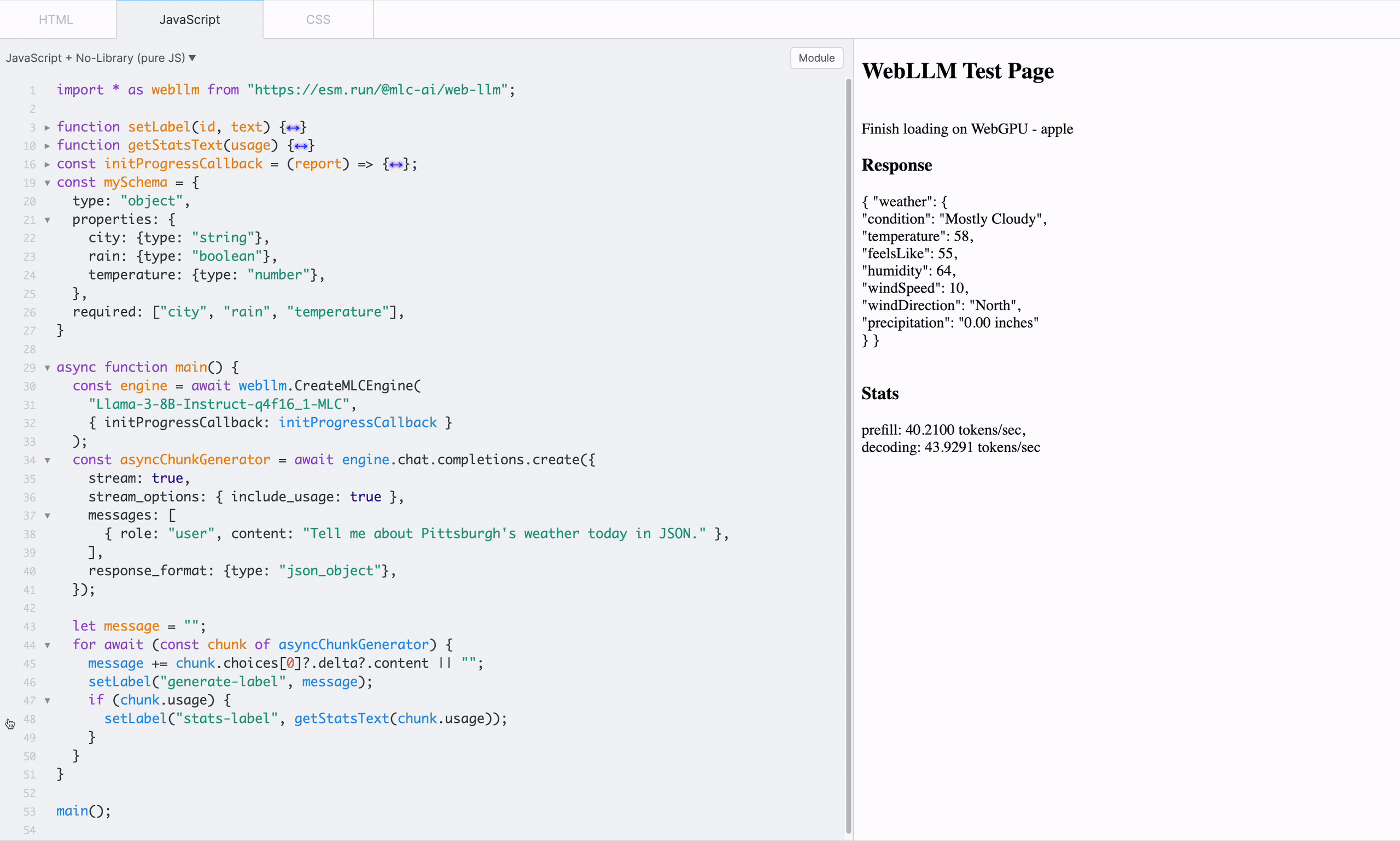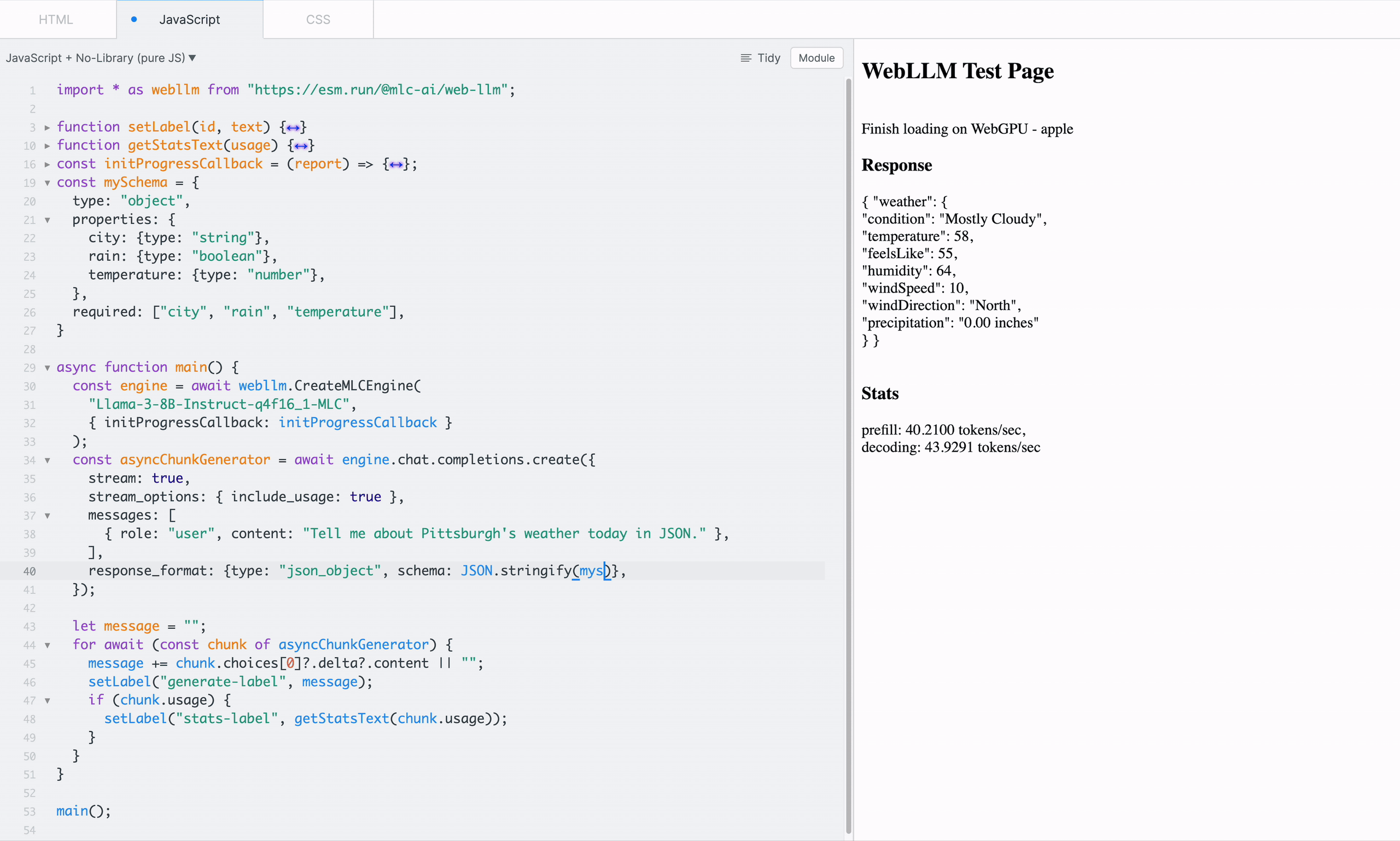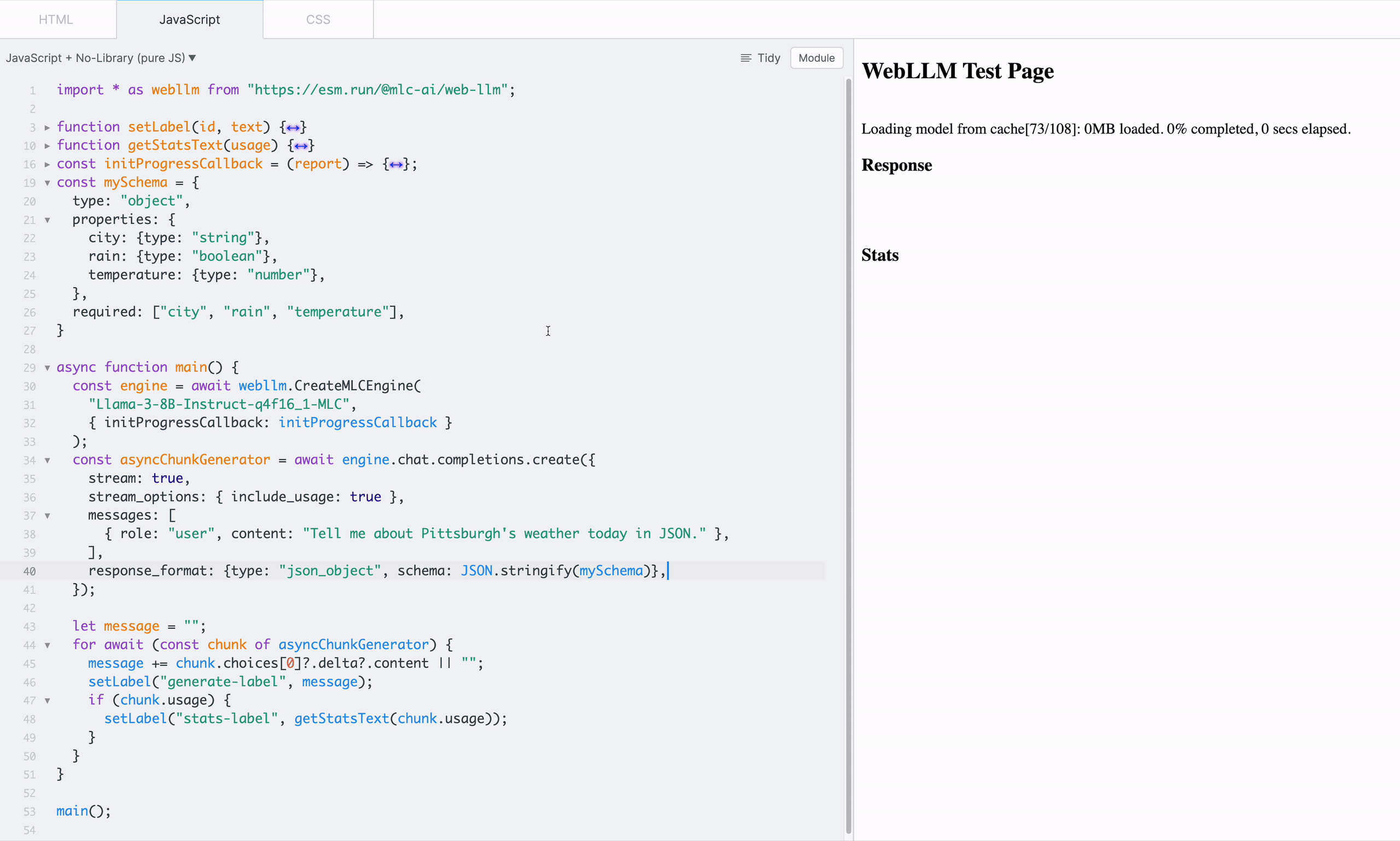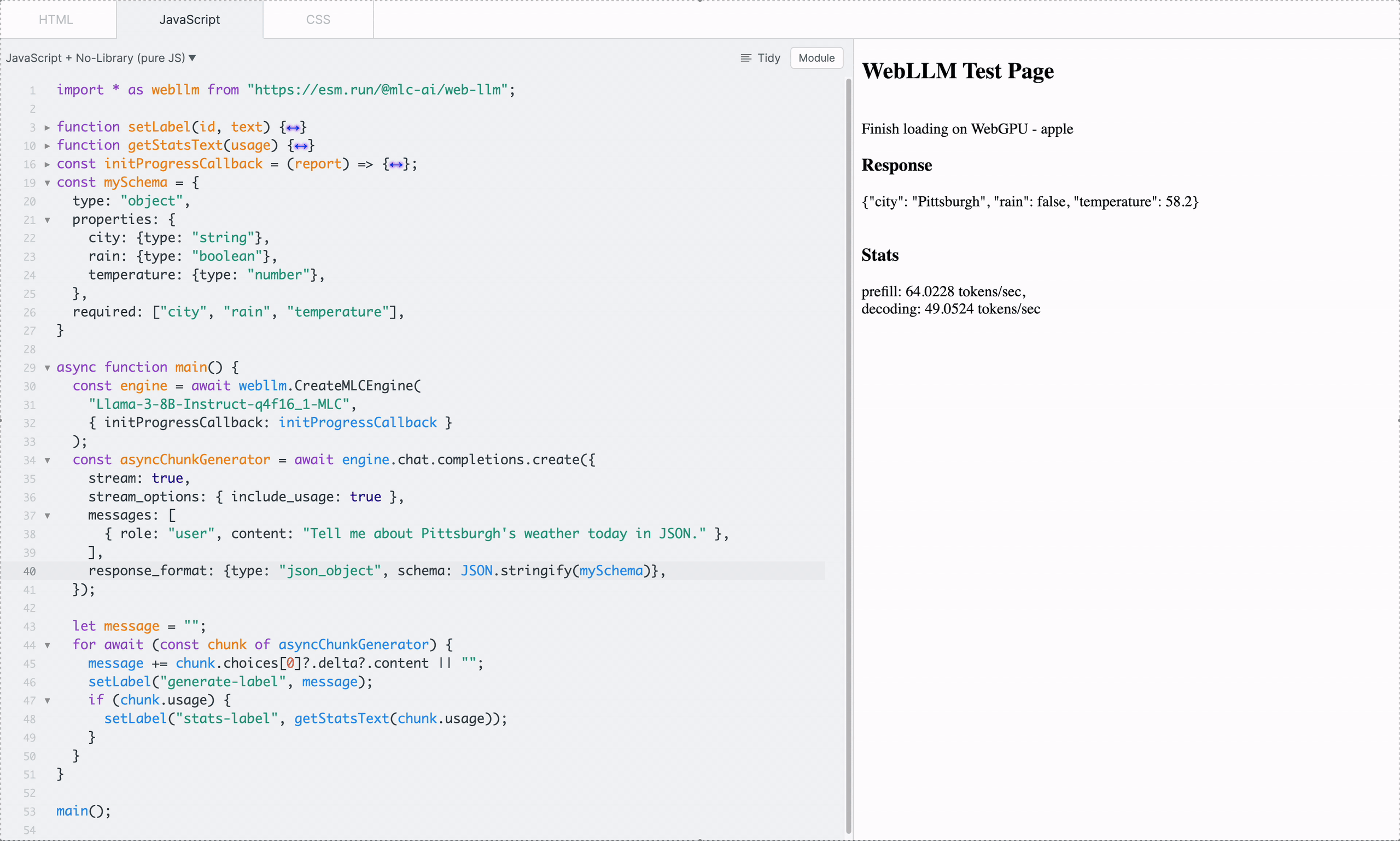
To familiarize with the functionality of WebLLM, one can start playing with the low-level MLCEngine in a sandbox like JSFiddle with the CDN-delivered WebLLM package, as shown in Figure 4.
Building Web Application with WebLLM
As we position WebLLM as the backend for AI-powered web applications, we spent significant effort in the past to streamline the experience of developing web applications with WebLLM. We hide all the heavy computation in the worker thread so developers can only interact with ServiceWorkerMLCEngine, treating it as an endpoint exposed to the front end.
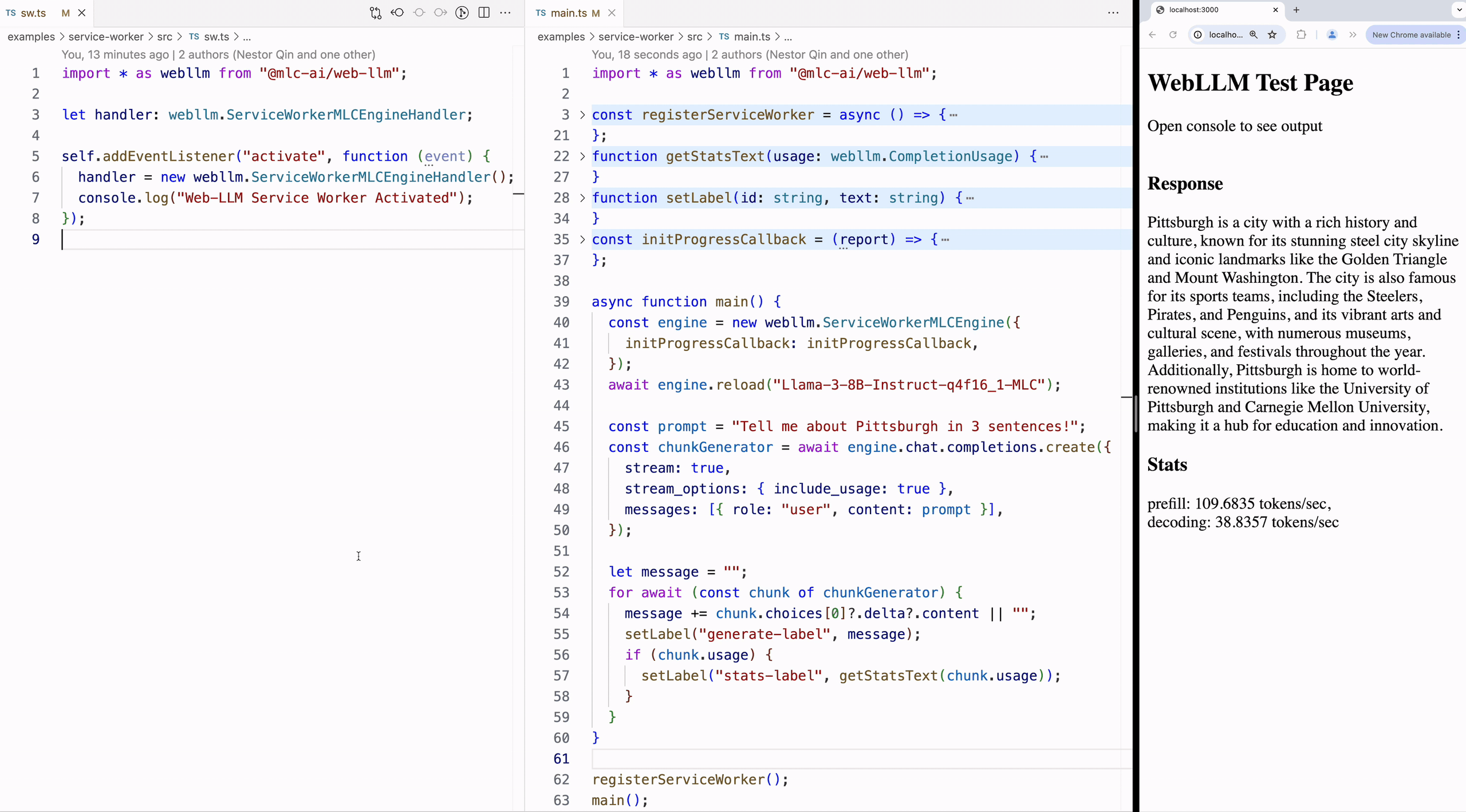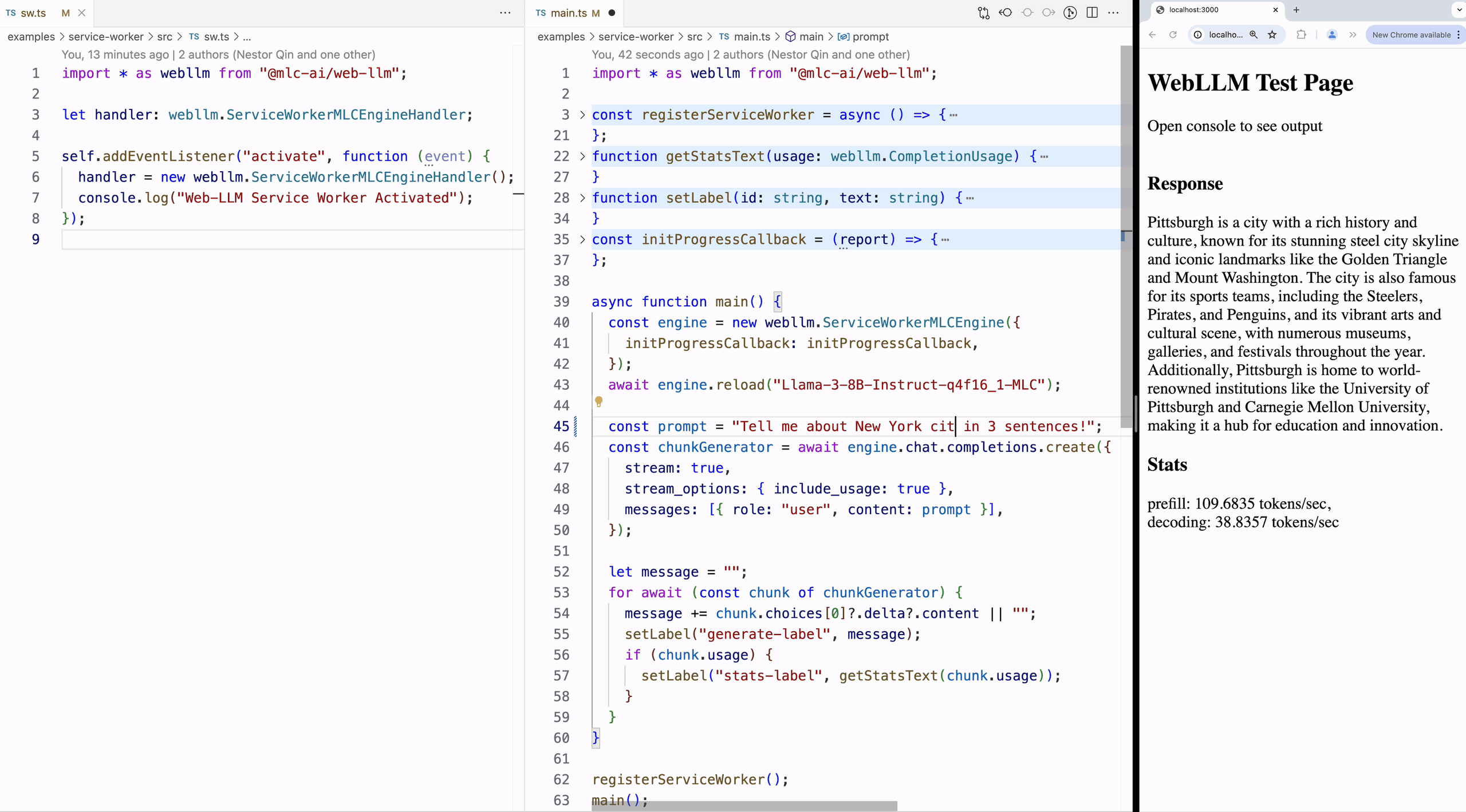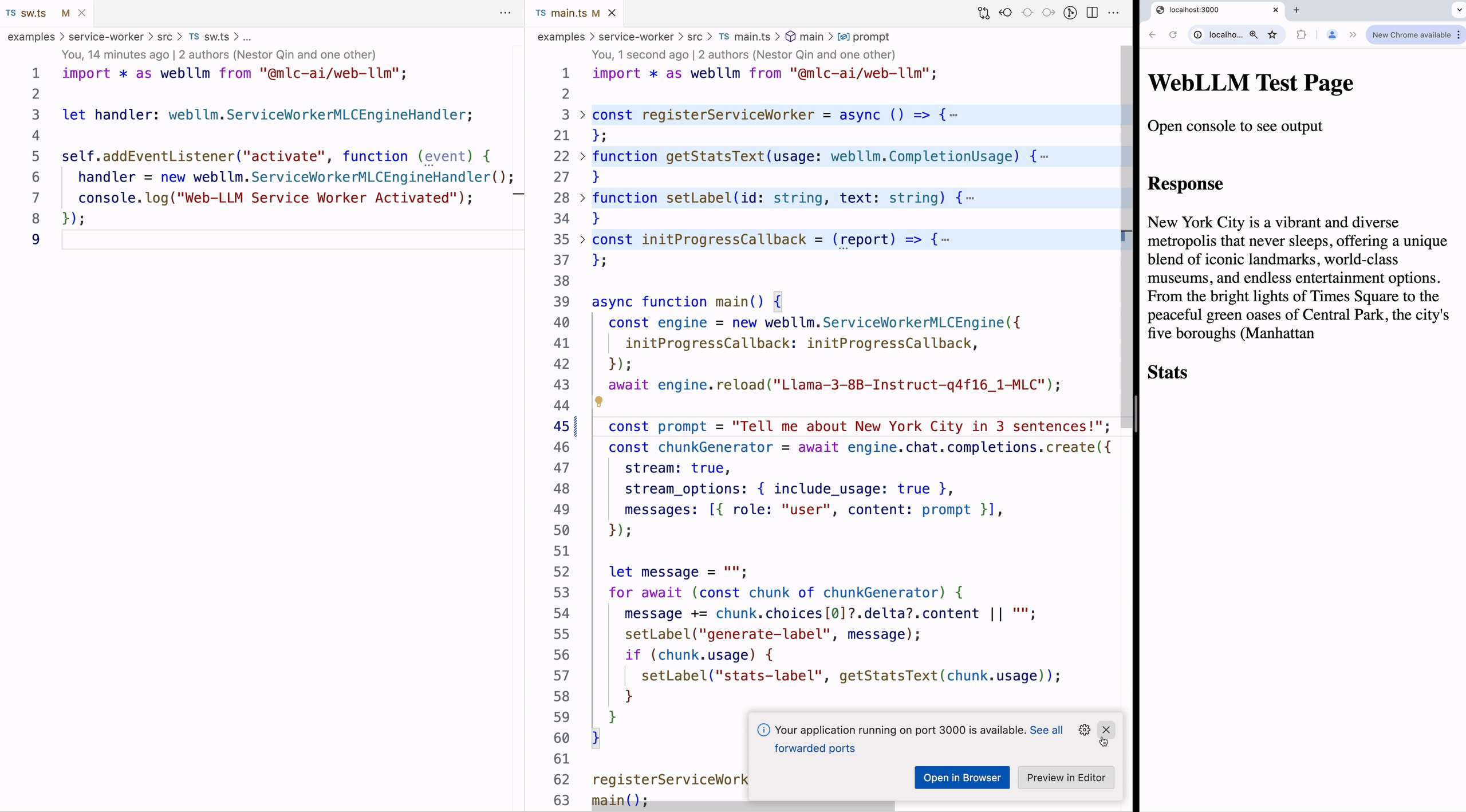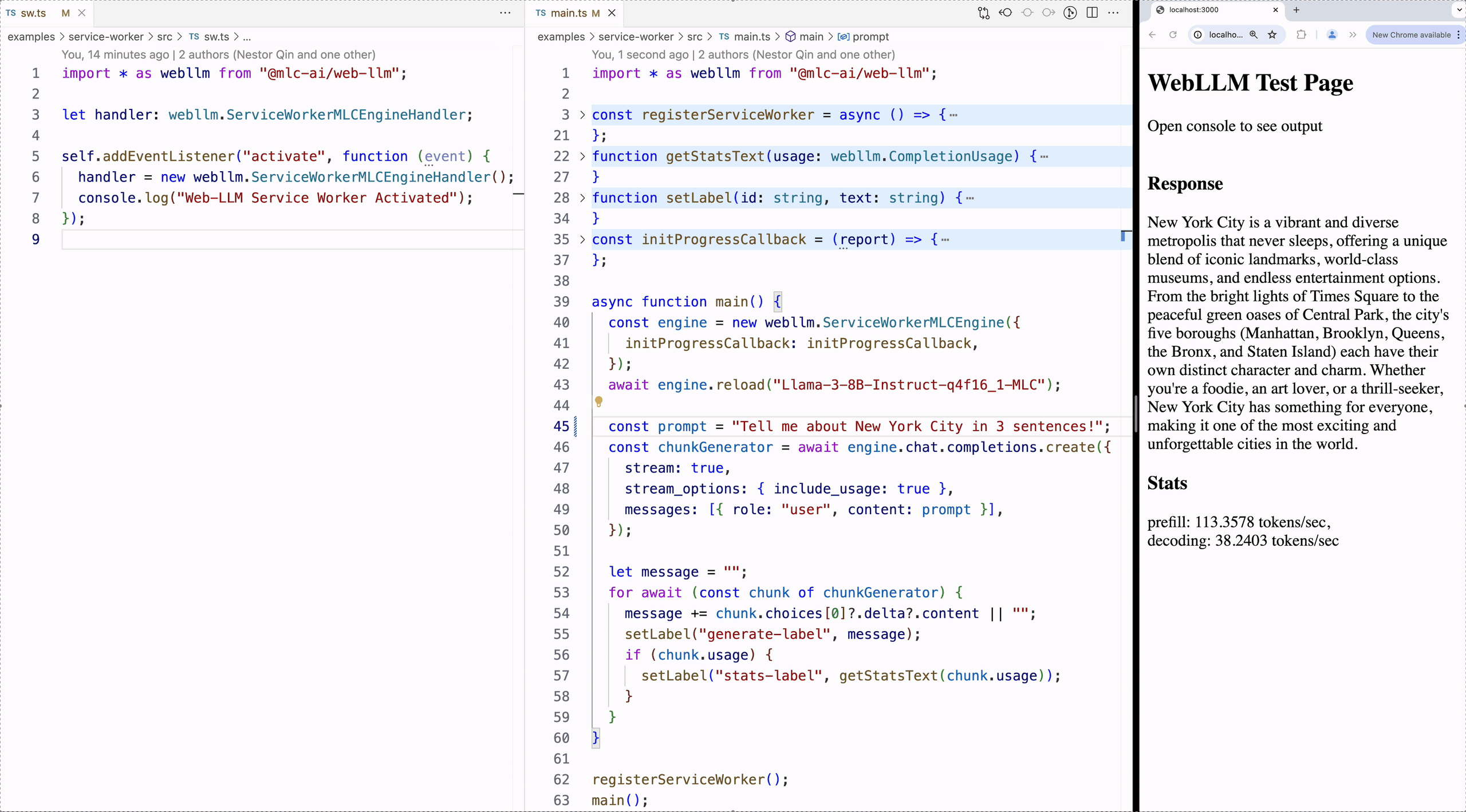
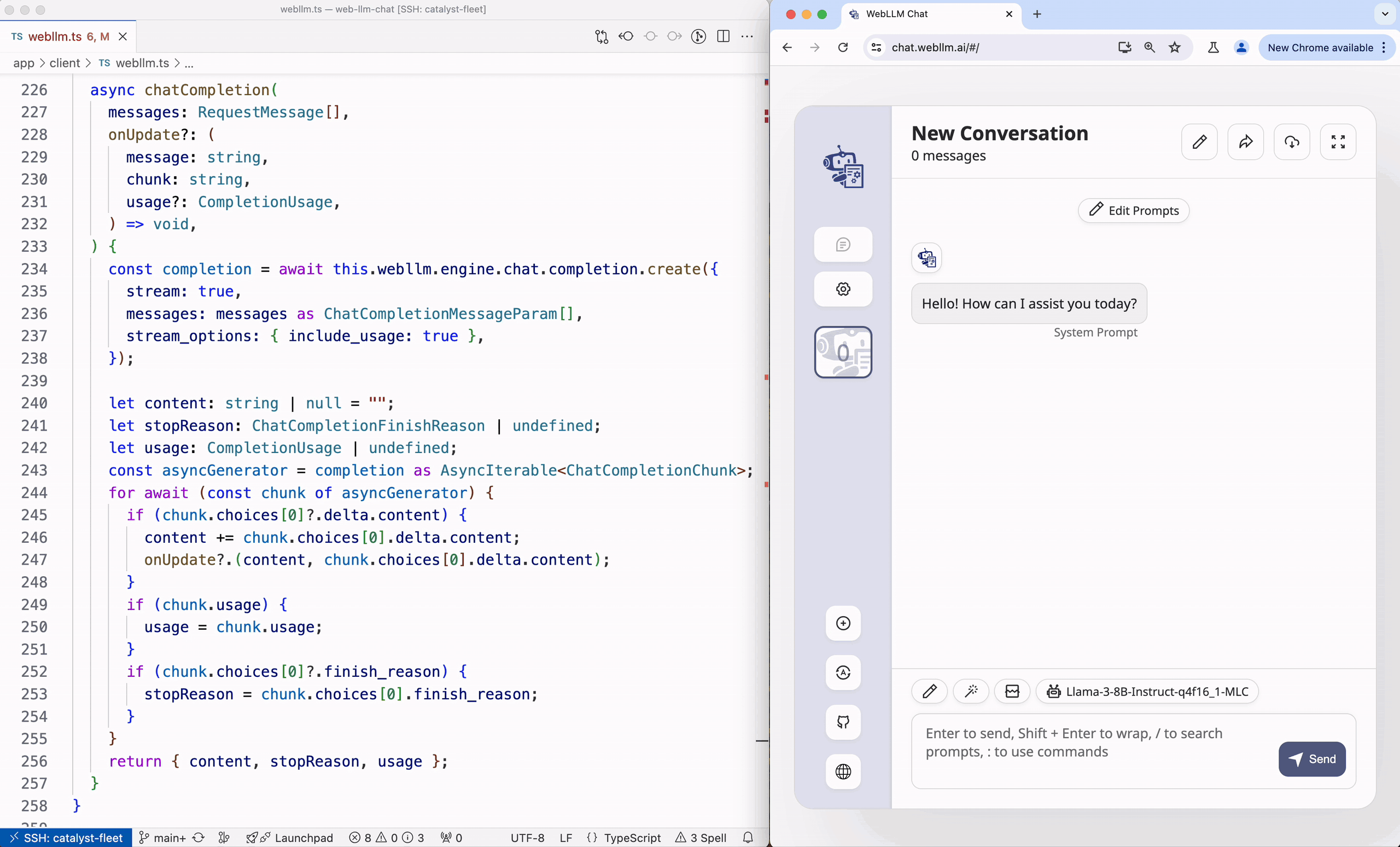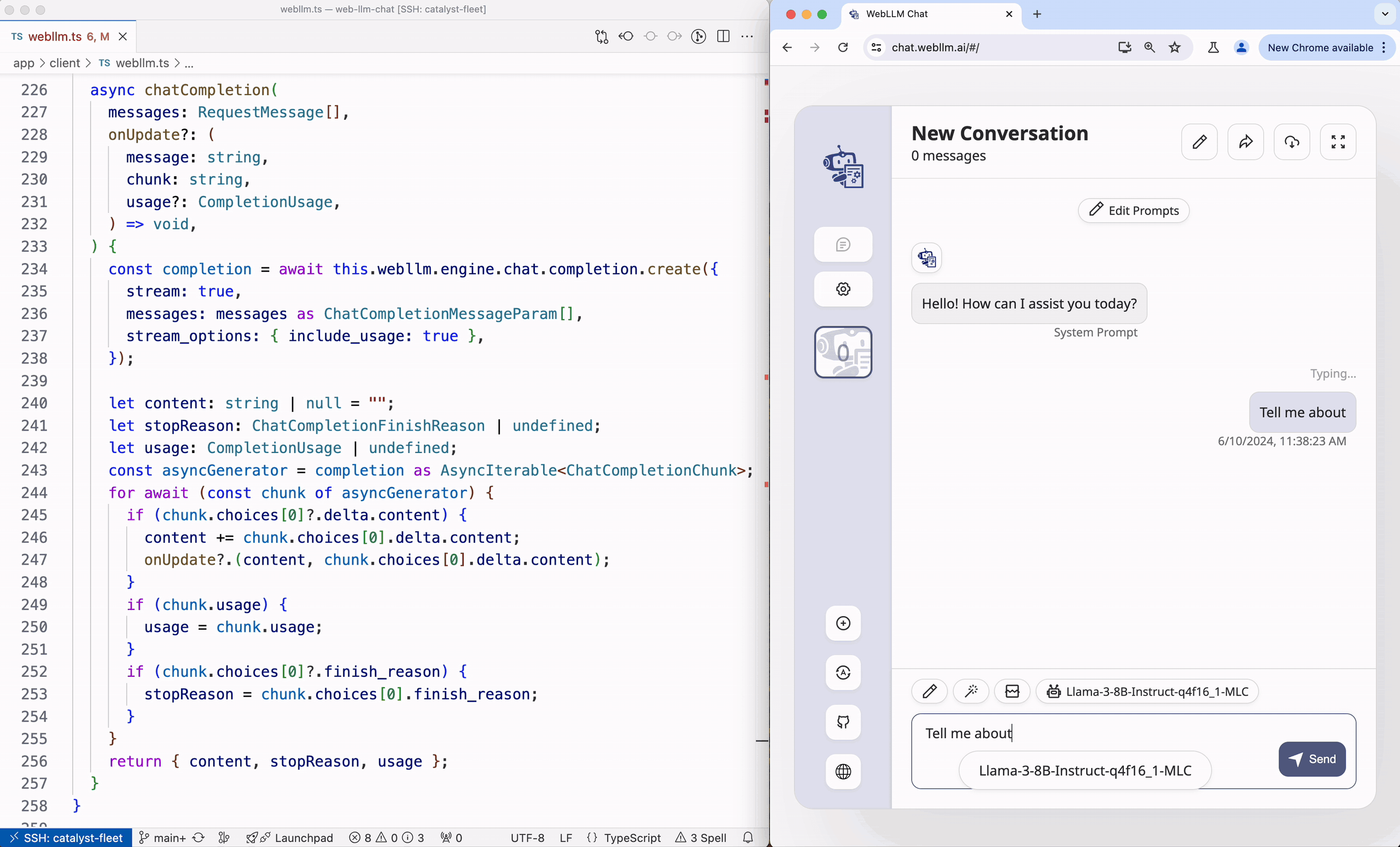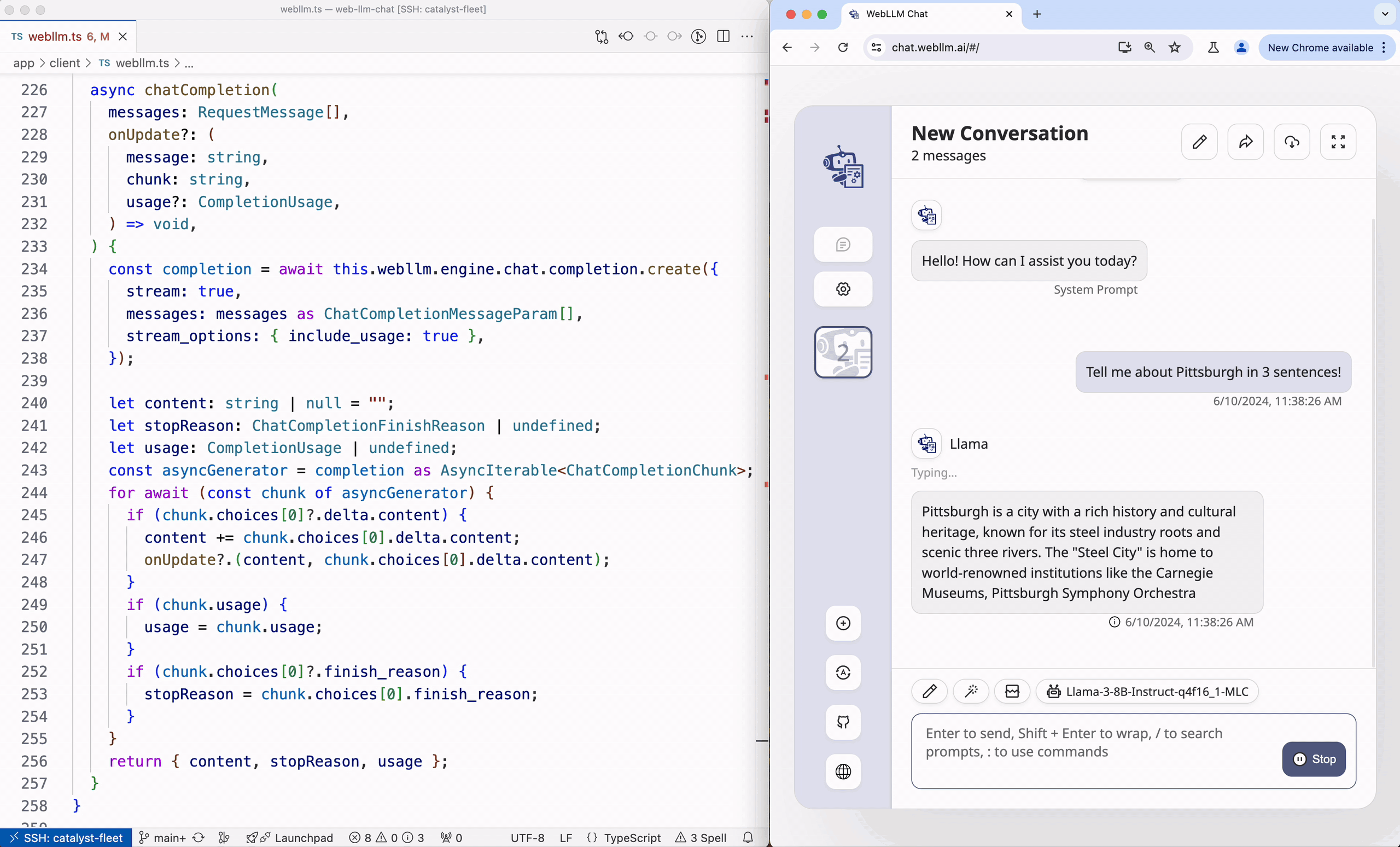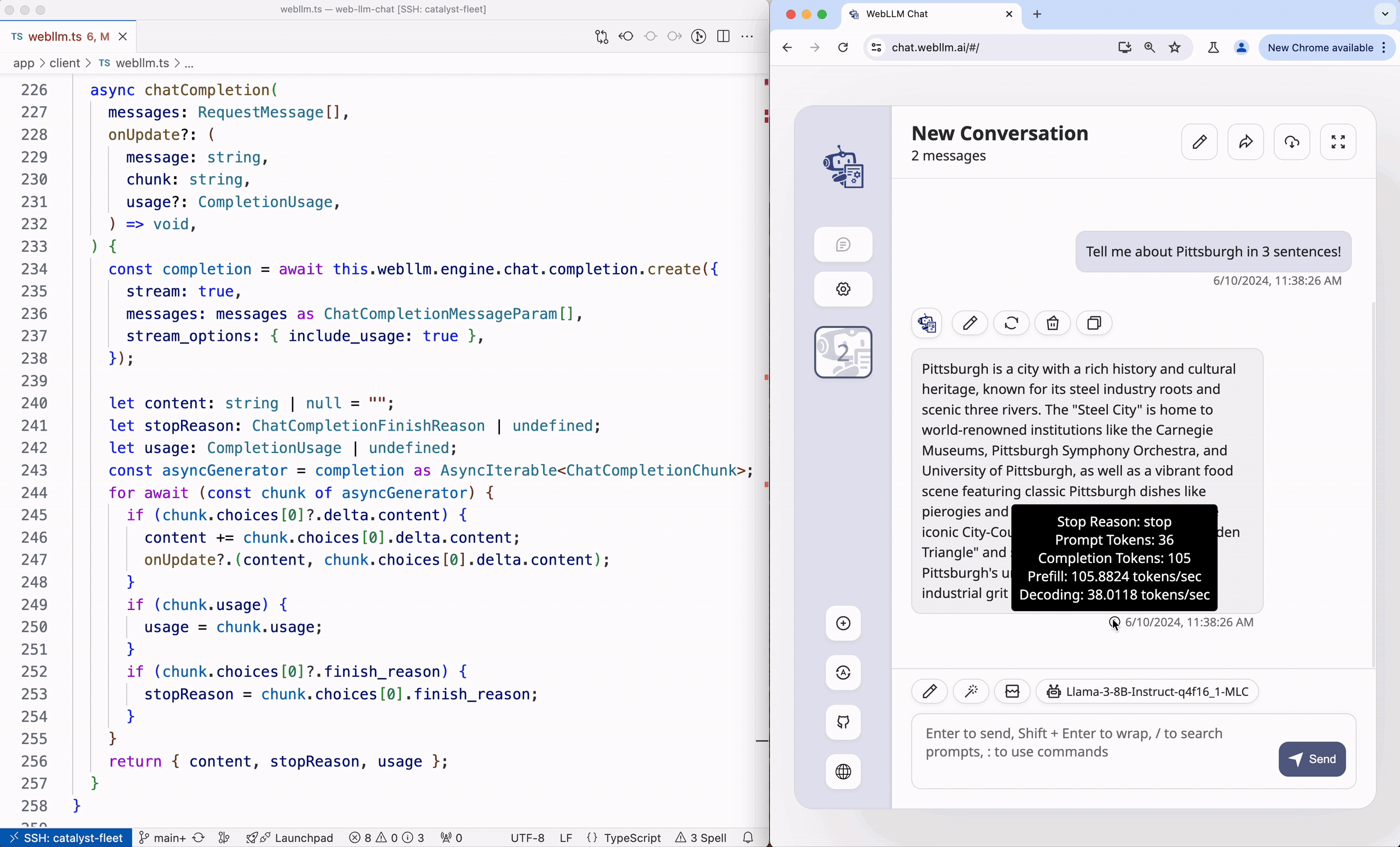
As shown in Figure 5, sw.ts on the left is the background worker thread, which contains a ServiceWorkerMLCEngineHandler that keeps an internal MLCEngine and passes messages between the frontend and the worker thread. In the middle, main.ts is where the web application’s frontend logics lie in, using the streamed back output to populate the webpage.
The ServiceWorkerMLCEngine is designed to be persistent across webpages and page reloads, minimizing the overhead of loading a model onto the GPU. In addition, we provide ExtensionServiceWorkerMLCEngine which can be used to build Chrome extensions with a similar concept.
WebLLM Chat is a great example of integrating WebLLM into a full web application, as shown in Figure 6.
Efficient Structured JSON Generation
We would also like to enable applications beyond chat. Structured generation is the key functionality to enable beyond-chatbot agents, ensuring the LLM to consistently generate valid JSON-format output. This allows LLMs to be used as standardized tools integrated into other applications in production.
WebLLM supports state-of-the-art JSON mode structured generation, implemented in the WebAssembly portion of the model library for optimal performance. WebLLM offers two levels of JSON mode: general JSON mode and customized JSON mode via schema.
To use the general JSON mode, simply specify response_format: { type: “json_object”} in the chat completion request:

In addition, WebLLM allows customizing the format with a JSON schema which the output would strictly adhere to. Simply specify response_format: { type: “json_object”, schema: mySchema} in the request:
JSON schema can also enable reliable function calling, crucial for building in-browser agents. WebLLM currently offers preliminary support for function calling and will follow up with full support.
Extensive Model Support
WebLLM offers an extensive list of prebuilt models, including Llama3, Phi3, Gemma, Mistral… Moreover, it is easy to integrate your own fine-tuned model.
As shown in Figure 2, two components are needed to run a model in WebLLM: model weights (converted to MLC format) and a WASM (i.e. model library). Say you finetuned a Llama3 model for a domain-specific task, you can simply convert your finetuned weights via MLC-LLM and reuse the Llama3 WASM we provide. You can also compile your own model in case the model family is not yet supported by WebLLM.
Performance
As discussed in the Introduction, WebGPU can be viewed as an abstraction of different backends (CUDA, Metal, etc.) so that different backends can execute the exact same kernels, allowing developers to serve a wide range of users. Therefore, such a convenient abstraction comes at a cost: instead of directly using native kernels, the GPU needs to conform to whatever WGSL supports.
However, we demonstrate that WebLLM’s performance is close to native performance, thanks to optimizations done via machine learning compilation techniques in MLC-LLM and TVM. Here we compare the inference of WebGPU against the inference with native Metal, both compiled by MLC-LLM and run on an M3 Max Macbook Pro.
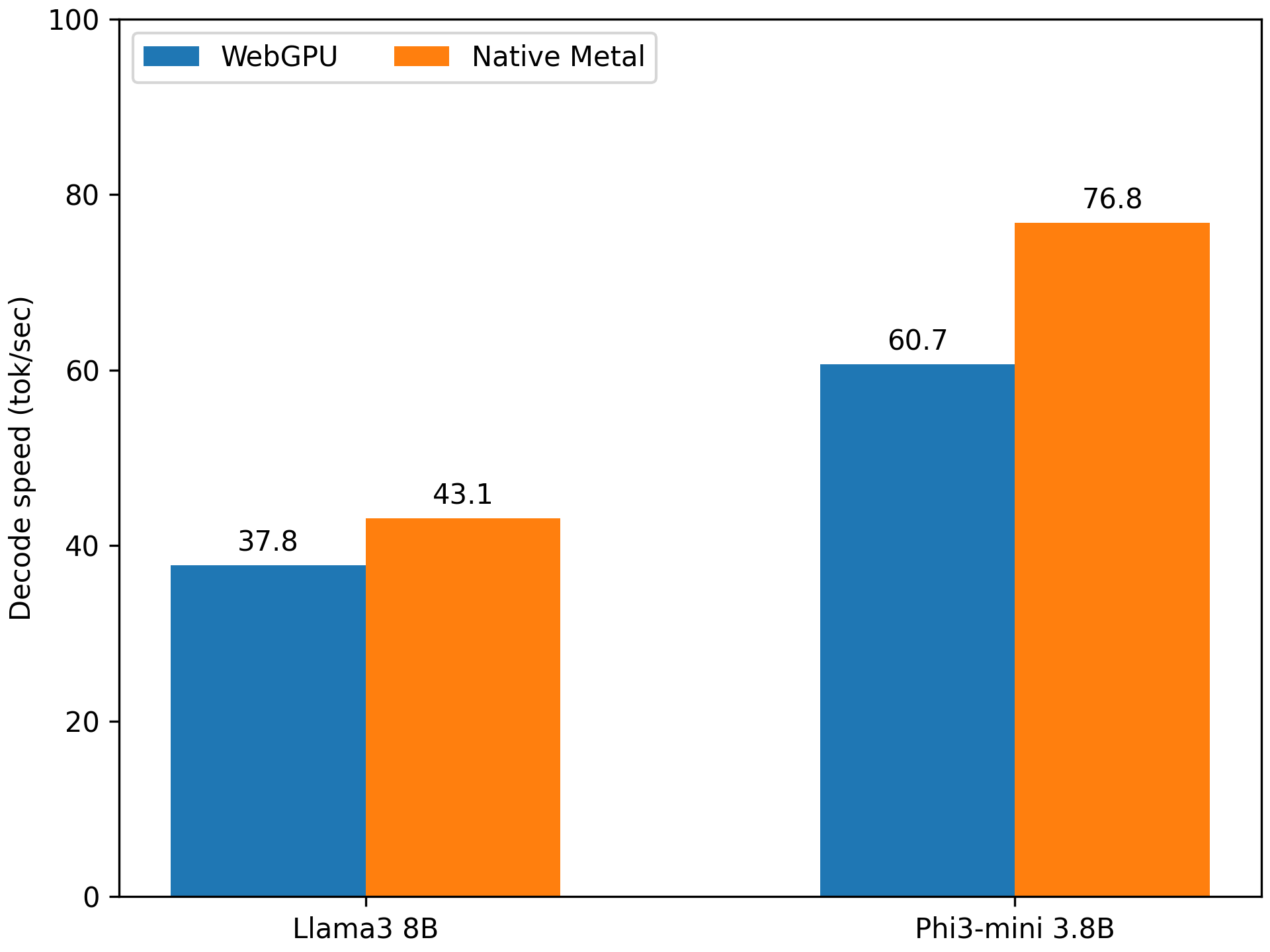
Our result shows that WebGPU can preserve up to 85% of the native performance. This is still an early stage of WebGPU support as most browsers just shipped it this year. We anticipate that the gap can continue to improve, as the WebGPU to native shader translation improves.
Future Opportunities
The vision of WebLLM is to become the backend for in-browser AI agents. We believe in a future where in-browser AI agents can help you perform tasks like booking calendars, drafting emails, buying tickets, and much more—and all these tasks can be viewed as requests to the WebLLM engine.
WebLLM will soon integrate function calling API (preliminary support as of now), embedding models, and multimodal models such as Phi-3 Vision and LLaVA, enabling the engine to perform an even more diverse range of tasks.
Call for Community Participation
We encourage the community to try out WebLLM Chat to experience the convenience and performance that WebGPU brings, experiment with the WebLLM npm package with a quick start example without setups, build WebLLM-enabled web applications by referring to existing examples, and give us feedback in our Github repo!
This project is made possible by many contributors from the open-source community, including contributions from CMU Catalyst, OctoAI, UW SAMPL, SJTU, and the broader MLC community. We would also like to thank the Google Chrome team and WebAI community for the great collaborations and discussions. We plan to continue working with the open-source community to bring open foundational models for everyone!