We are witnessing an exciting era for large language models (LLMs). As LLM applications evolve, we are increasingly moving toward LLM agents that not only respond in raw text but can also generate code, call environment functions, and even control robots. To enable these richer LLM agent applications, LLM engines need to produce structured outputs that can be consumed by downstream agent systems. Examples of these structures include JSON, SQL, Python, and more. This paradigm is known as the structured generation in LLM inference. Fundamentally, an ideal LLM structured generation system should satisfy the following requirements:
- First, efficiency should be the top priority of LLM inference engines, and the structured generation support should not slow down the LLM service.
- Equally important, the structure specification needs to support a diverse range of structures relevant to current and future applications.
- On top of the above two goals, the solution should be portable to enable structured generation applications everywhere.
It is challenging to address all these goals simultaneously. Some libraries introduce efficiency optimizations but at the cost of restricting to a small set of structures (e.g., those representable by finite-state machines). Conversely, supporting more general structures through expressive representations like context-free grammar (CFG) introduces challenges in efficiency, as it has infinitely many possible intermediate states, so it is impossible to preprocess every possible state to speed up. Furthermore, these challenges will only get harder with the latest GPUs getting faster. Modern LLM inference on the latest GPUs can generate tens of thousands of tokens per second in large batch scenarios. All existing open-source structured generation solutions will introduce large CPU overhead, resulting in a significant slowdown in LLM inference.
In this post, we introduce XGrammar, an open-source library for efficient, flexible, and portable structured generation. We achieve these three goals without compromise and are committed to a focused mission: bringing flexible, zero-overhead structured generation everywhere.
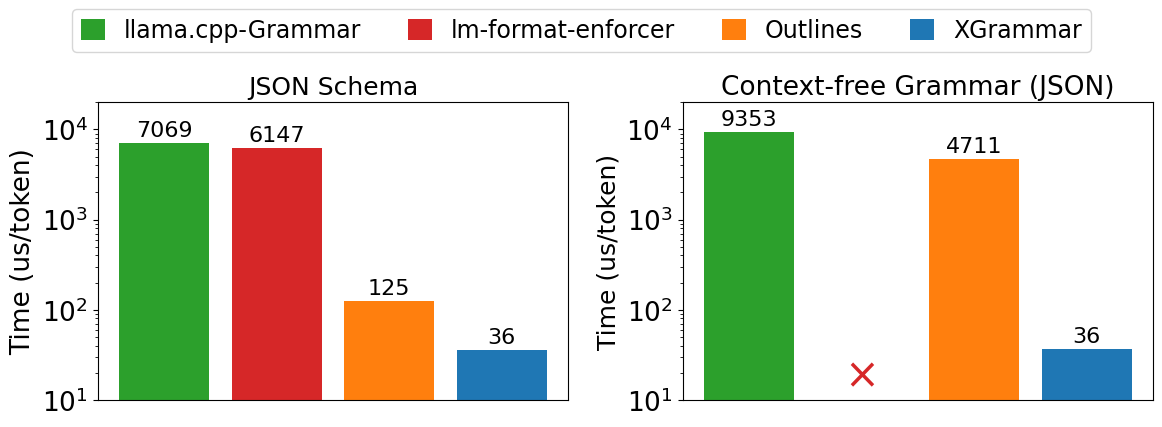
We benchmark XGrammar on both JSON schema generation and unconstrained CFG-guided JSON grammar generation tasks. Figure 1 shows that XGrammar outperforms existing structured generation solutions by up to 3.5x on JSON schema workloads and up to 10x on CFG-guided generation tasks.
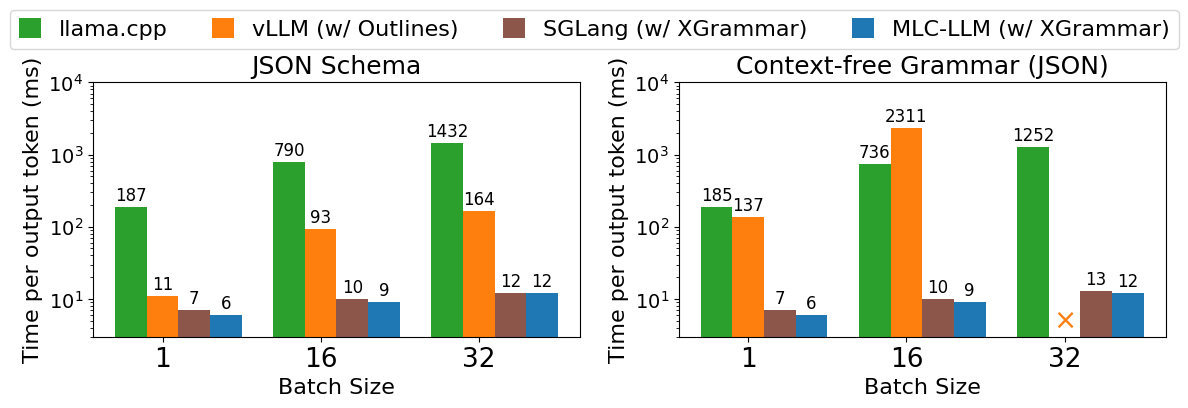
Additionally, we benchmark end-to-end structured generation engines powered by XGrammar with the Llama-3 model on NVIDIA H100 GPUs. Figure 2 shows that our solution outperforms existing LLM engines up to 14x in JSON-schema generation and up to 80x in CFG-guided generation. We have released our code and a tech report. In the remainder of this post, we will introduce the background and key techniques of XGrammar.
Background: Constrained Decoding and Context-free Grammar
Structured generation allows us to specify an output format and enforce this format during LLM inference. One commonly used example of structured generation is the JSON format. In many applications, we may further constrain the structure using a JSON schema, which specifies the type of every field in a JSON object and is adopted as a possible output format for GPT-4 in the OpenAI API. The figure below illustrates an example of an LLM structured generation process using a JSON Schema described with the Pydantic library.
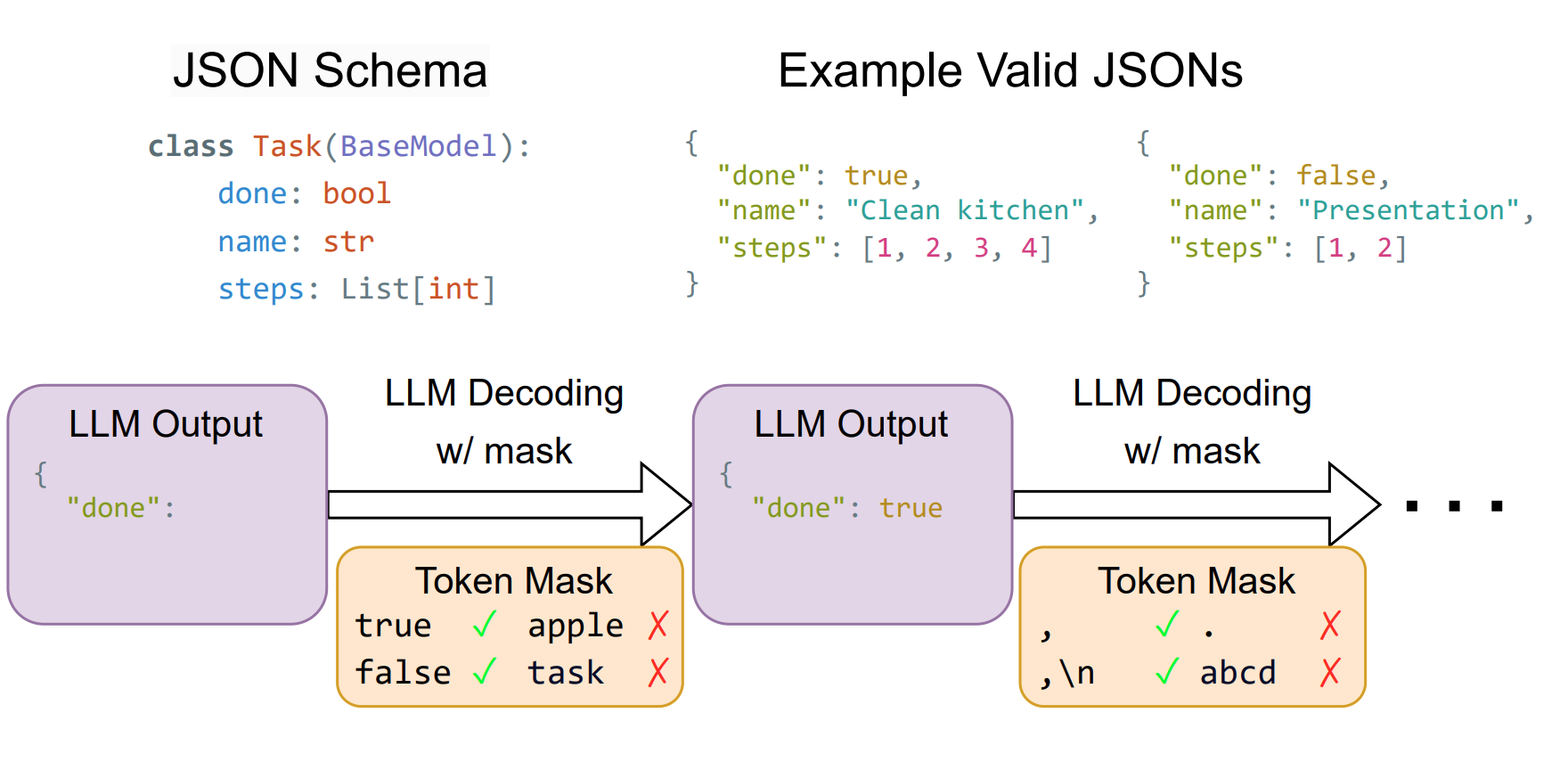
Constrained decoding is a common technique to enforce the output format of an LLM.
As shown in the figure above, an LLM engine maintains an internal state of the desired structure and the history of generated tokens.
When generating a new token, the engine identifies tokens that may violate the required structure and masks them off in the logits.
The masking causes the sampling process to avoid invalid tokens and only generate valid ones.
In this example, only tokens “true” and “false” are allowed in the first decoding step, and only “,” and “,\n” are allowed in the second decoding step.
There are many ways to specify a structure. Although JSON schema is a popular method for structure specification, it cannot define code syntax or recursive structures (such as nested brackets of any depth). Context-free grammars (CFGs) provide a more powerful and general representation that can describe many complex structures. The figure below shows an example of a CFG for nested recursive string arrays. A CFG contains multiple rules, each of which can include a concrete set of characters or references to other rules.
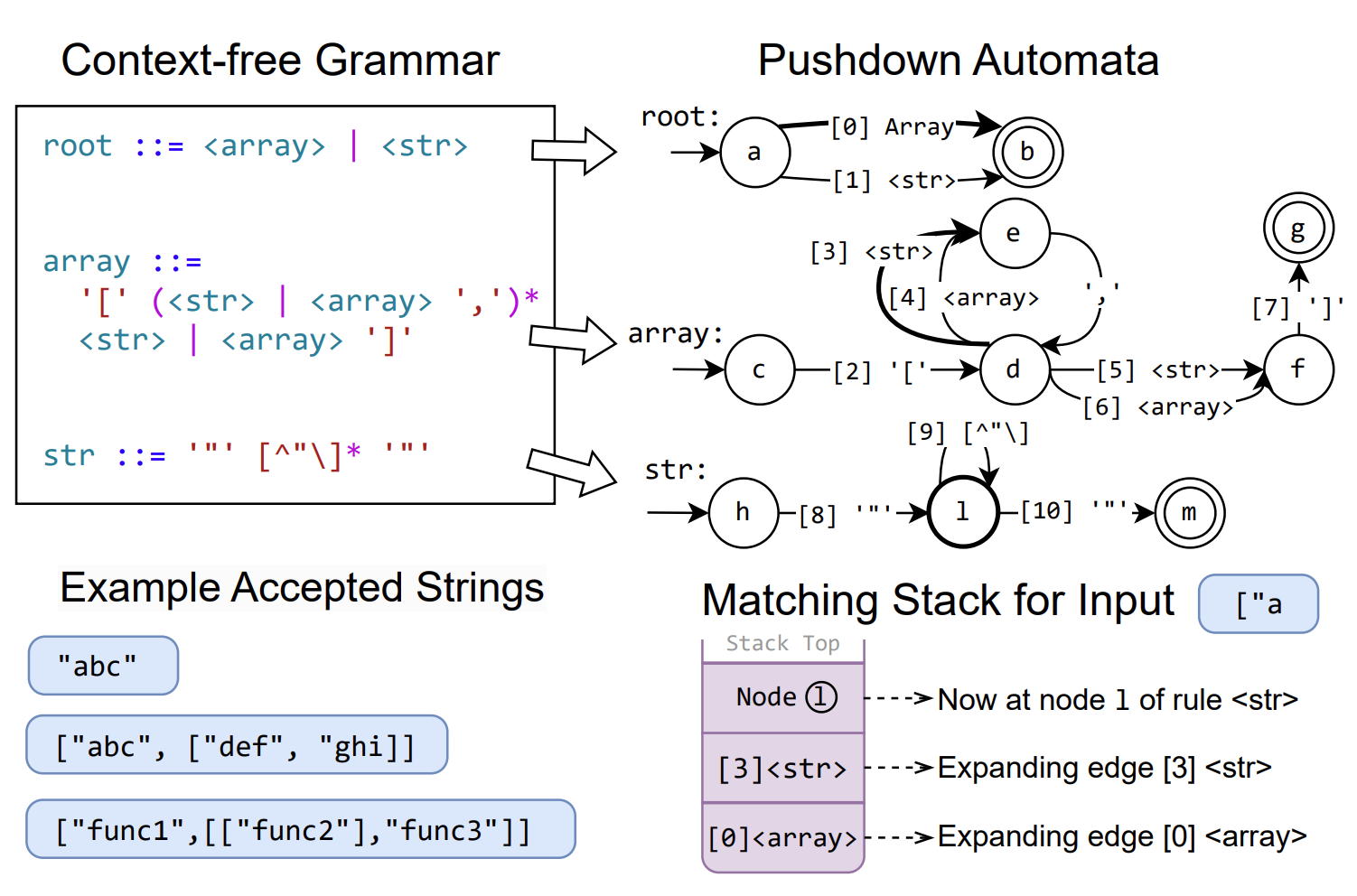
We choose CFGs as the structure specification method for XGrammar due to their expressive nature. Many common programming languages, such as JSON, XML, and SQL, can be described using CFGs. They are also superior to alternative formats such as JSON Schema and regular expressions because they can support recursive nested structures.
A pushdown automaton (PDA) is a common approach to execute a CFG. Each PDA contains multiple finite state machines (FSM), each representing a rule in the CFG. Transitions in the PDA can either consume an input character or recurse into another rule. The PDA begins processing the input string by executing state transitions in the FSM associated with the root rule. When it encounters a transition referencing another rule, it recurses into that rule to continue matching. The PDA leverages a stack to store the historical rules, enabling us to traverse among rules recursively. Once a rule is fully matched, the PDA pops the stack to return to the previous context and continues processing. Notably, when multiple transitions are possible, it becomes necessary to maintain multiple stacks. The ability to recurse into other rules makes PDAs much more powerful than single FSMs (or regular expressions convertible into FSMs), providing extra ability to handle recursion and nested structures.
Why is it hard to accelerate general CFGs? The flexible nature of CFGs and PDAs makes them more challenging to accelerate. To generate token masks in constrained decoding, we need to check the validity of every token in the vocabulary—which can be as many as 128,000 tokens in models like Llama 3! The execution of PDA depends on internal stacks, which have infinitely many possible states, making it impractical to precompute the mask for every possible state. Moreover, we need to maintain multiple stacks during the execution of the PDA, whose number can be up to dozens. We need to check the validity of tokens for every stack, which increases the computation of token checking severalfold.
XGrammar Overview
XGrammar solves the above challenges and provides full and efficient support for context-free grammar in LLM structured generation through a series of optimizations. Our primary insight is that although we cannot precompute complete masks for infinitely many states of the pushdown automaton, a significant portion (usually more than 99%) of the tokens in the mask can be precomputed in advance. Thus we categorize the tokens into two sets:
- Context-independent tokens: tokens whose validity can be determined by only looking at the current position in the PDA and not the stack.
- Context-dependent tokens: tokens whose validity must be determined with the entire stack.
Figure 5 shows an example of context-dependent and context-independent tokens for a string rule in a PDA. In most cases, context-independent tokens make up the majority. We can precompute the validity of context-independent tokens for each position in the PDA and store them in the adaptive token mask cache. This process is known as grammar compilation.
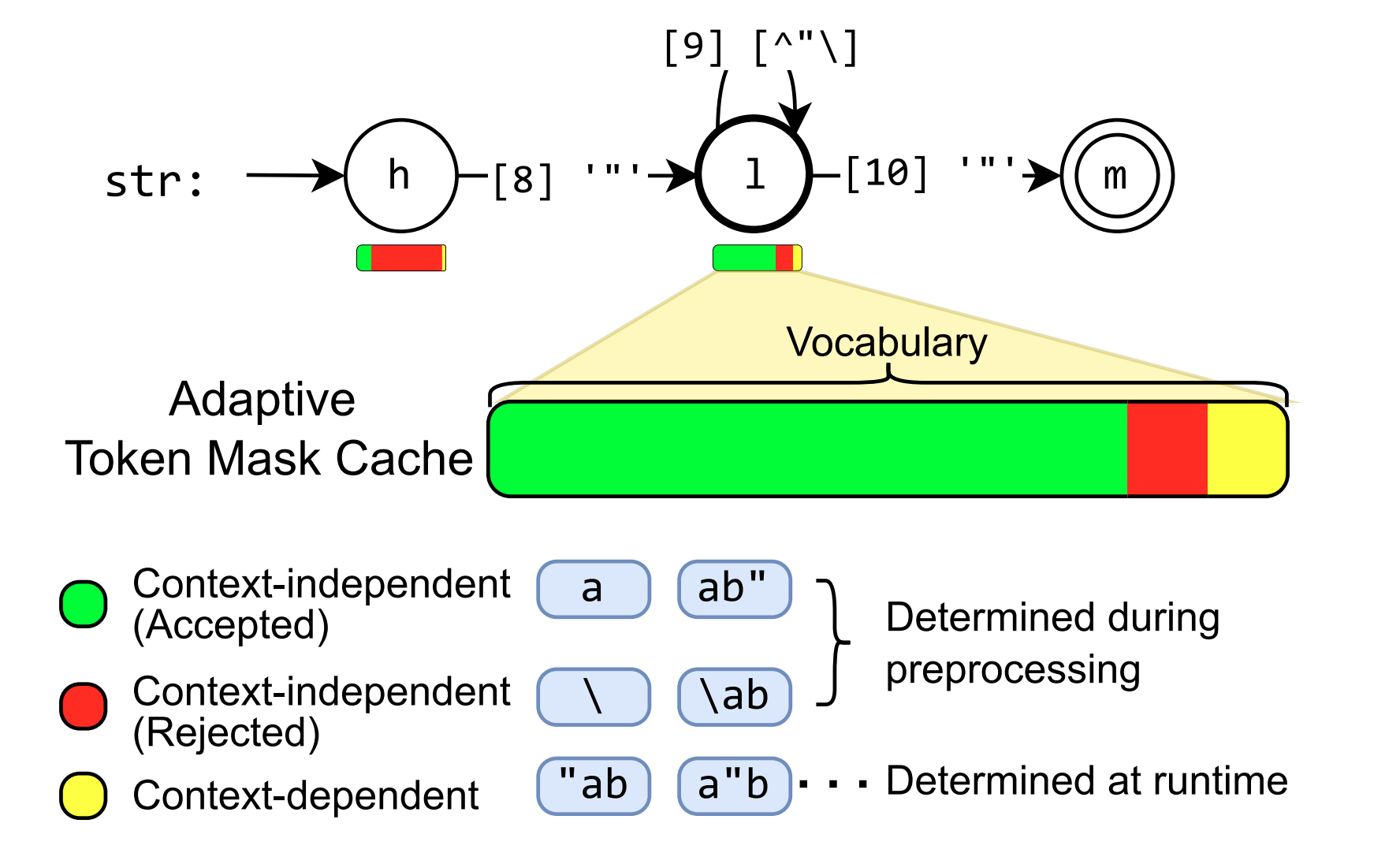
At runtime, we retrieve the validity of context-independent tokens from the cache. We then efficiently execute the PDA to check the rest context-dependent tokens. By skipping checking the majority of tokens at runtime, we can significantly speed up mask generation. The figure below shows the overall workflow in XGrammar execution.
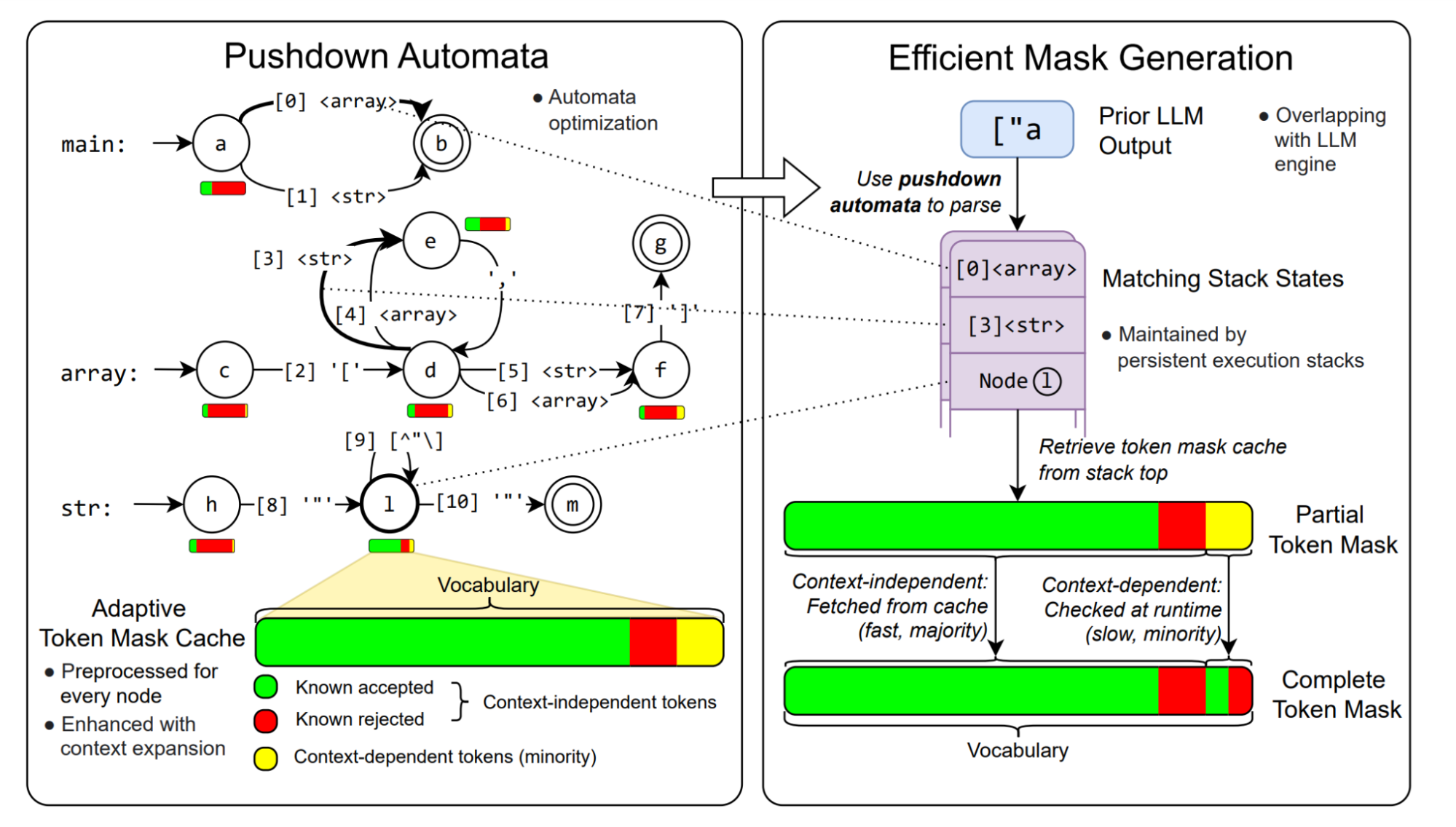
We designed an additional set of algorithms and system optimizations to further enhance the mask generation speed and reduce preprocessing time, summarized below:
- Context expansion. We detect additional context information for each rule in the grammar and use it to decrease the number of context-dependent tokens and further speed up the runtime check.
- Persistent execution stack. To speed up the maintenance of multiple parallel stacks during splitting and merging due to multiple possible expansion paths, we design a tree-based data structure that efficiently manages multiple stacks together. It can also store state from previous times and enable efficient state rollback, which speeds up the runtime checking of context-dependent tokens.
- Pushdown automata structure optimizations. We leverage a series of optimizations adopted from compiler techniques, particularly inlining and equivalent state merging to reduce the number of nodes in the pushdown automata, speeding up both the preprocessing phase and the runtime mask generation phase.
- Parallel grammar compilation. We parallelize the compilation of grammar using multiple CPU cores to further reduce the overall preprocessing time.
The above optimizations help us reduce the general overhead of grammar execution. Building on top of these optimizations, we further co-design the LLM inference engine with grammar execution by overlapping grammar processing with GPU computations in LLM inference.
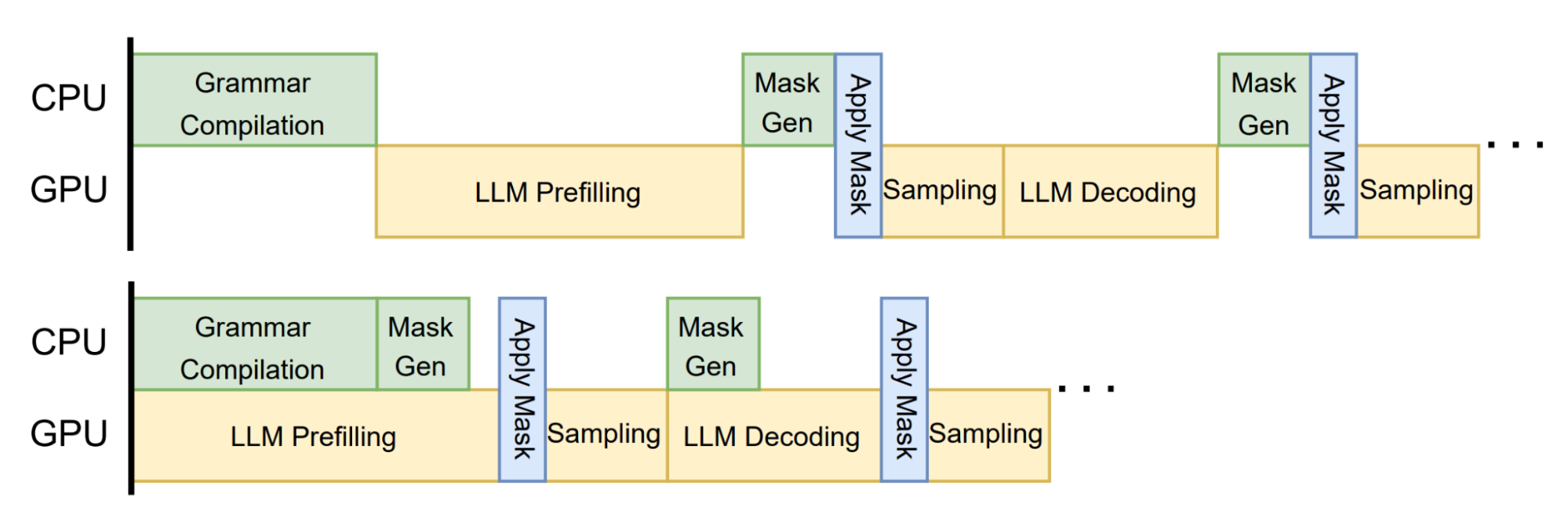
Figure 7 shows an example workflow that overlaps general grammar processing with LLM inference. We also provide additional co-design APIs, to enable rollback (needed for speculative decoding) and jump-forward decoding, which further speeds up the speed of structured generation. Through these optimizations, we achieve both accuracy and efficiency without compromise, fulfilling our goal of flexible and efficient structured generation.
Benchmark Setup
We evaluate our system with the Llama-3.1-8B-Instruct model on two workloads:
- JSON schema: this setting leverages JSON schema as the structure specification, helping to evaluate the effectiveness of the system on schema-guided generation.
- JSON context-free grammar: this setting takes a CFG that specifies standard JSON grammar adopted from ECMA-404. Notably, this is a more challenging task because the input is a general CFG. It helps to evaluate how well a system performs in general grammar-guided generation.
We utilize the JSON-mode-eval dataset.
We first evaluate the speed of masking logits. We take the ground truth response and measure the time of mask generation and logit process. We benchmark both Outlines’ latest rust backend (v0.1.3) and Python backend (v0.0.45) and report the best among the two. We also benchmarked llama-cpp’s built-in grammar engine (b3998) and lm-format-enforcer (v0.10.9, lm-format-enforcer has no CFG support). As shown in Figure 1, XGrammar outperforms existing structured generation solutions by up to 3.5x on the JSON schema workload and more than 10x on the CFG workload. Notably, the gap in CFG-guided generation is larger. This is because many JSON schema specifications can be expressed as regular expressions, bringing more optimizations that are not directly applicable to CFGs.
For end-to-end evaluation, we benchmarked the LLM inference engine efficiency in serving scenarios with different batch sizes. We ensure that the number of output tokens is almost the same by limiting the output length. Figure 2 shows end-to-end inference performance on LLM serving tasks. We can find the trend again that the gap on CFG-guided settings is larger, and the gap grows on larger batch sizes. This is because the GPU throughput is higher on larger batch sizes, putting greater pressure on the grammar engine running on CPUs. Note that the main slowdown of vLLM comes from its structured generation engine, which can be potentially eliminated by integrating with XGrammar. In all cases, XGrammar enables high-performance generation in both settings without compromising flexibility and efficiency.
Integration
XGrammar contains a lightweight C++ core that can be integrated into many platforms. We also provide ready-to-use Python and TypeScript libraries. It already powers many LLM frameworks:
- MLC-LLM leveraged the C++ backend to build cross-platform support for high-performance structured generation, enabling support on a diverse set of server, laptop, and edge platforms.
- SGLang integrated the Python library and showed a significant reduction of JSON Schema generation overhead compared to its previous backend. To use it:
- Add
--grammar-backend xgrammarwhen you launch the server - Query it with OpenAI-compatible API https://sgl-project.github.io/backend/openai_api_completions.html#JSON
- Add
- WebLLM integrated the typescript library and enabled in-browser local structured generation. You can check out a demo in WebLLM Structured Generation Playground.
- We are working with the TensorRT-LLM team to bring first-class XGrammar support, which will soon be integrated into the preview main branch.
- We are working with the vLLM team to enable first-class XGrammar integration in vLLM.
- We are working with the Hugging Face team to bring XGrammar into the HF ecosystem, including transformers, Text Generation Inference, transformers.js, and more. Please stay tuned!
- We are working with the VILA team to enable XGrammar in the inference pipeline of the vision model VILA. The integration of vision models and structured generation can provide support for a broader range of agent applications.
We are also actively collaborating with more teams to bring first-class integration and welcome wider adoption and contributions from the community. Please check out our GitHub and documentation for guides to integrate into LLM serving frameworks.
Summary
In this post, we introduce XGrammar, an efficient, flexible, and portable engine for structured generation. This project is made possible by many contributions from the open-source community. We are committed to our mission of bringing zero-overhead flexible structured generation to everyone and warmly welcome feedback and contributions from the community. To try out, or learn more about it, please check out the following resources:
Acknowledgments
We thank (alphabetically) the DeepSeek team, Hugging Face team, SGLang team, TensorRT-LLM team, vLLM team, and WebLLM team for their helpful feedback and discussions. We also thank Weihua Du (CMU), Haoran Peng (UW), Xinyu Yang (CMU), Zihao Ye (UW), Yilong Zhao (UC Berkeley), Zhihao Zhang (CMU), and Ligeng Zhu (MIT) for their insightful discussion and feedback.