Large language models (LLMs) have made a profound impact in AI, excelling in tasks ranging from text generation to code synthesis. As LLM serving scales towards multiple GPUs and even multiple compute instances, many orchestration patterns arise, including prefill-decode disaggregation, context cache migration, and traffic-adaptive request routing. However, most inference frameworks today expose a coarse-grained request-level API with a pre-configured orchestration strategy hidden within the framework’s LLM engine. This limits framework users’ ability to customize and explore different coordination strategies and dynamically reconfigure them based on the incoming traffic. How can we design LLM serving API that makes cross-engine serving programmable?
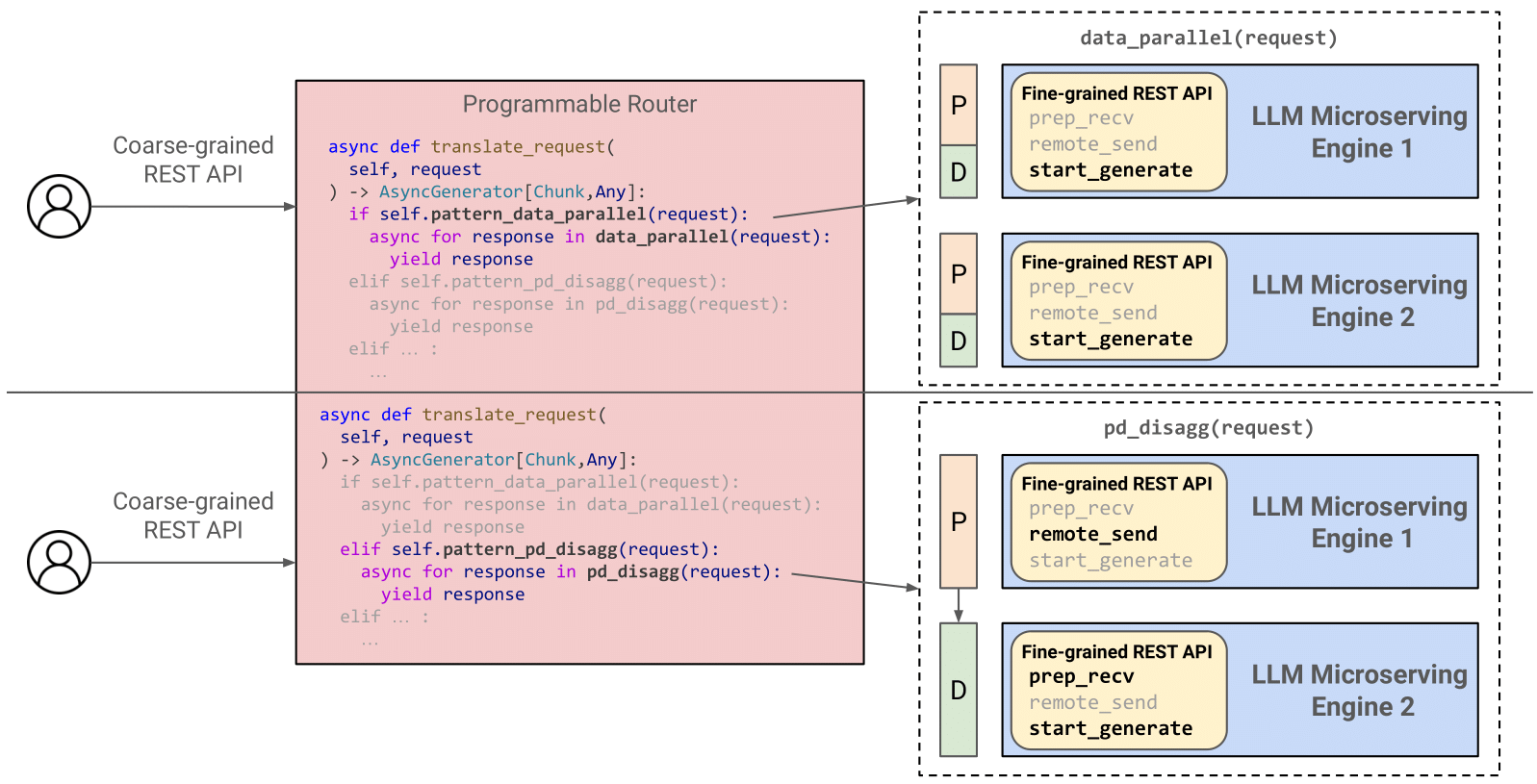
To address this gap, we introduce MicroServing, a multi-level architecture that provides simple yet effective fine-grained APIs for orchestrating LLM engines. MicroServing introduces simple yet effective APIs to support fine-grained sub-request level actions. The overall design philosophy draws close inspiration from “RISC-style” in computer architectures – we can view the coarse-grained request-level APIs as CISC instruction set, and Microserving brings “RISC-style” APIs for LLM serving. A programmable router transforms user requests into sub-request calls, lifting fine-grained scheduling to the API level, thus enabling the dynamic reconfiguration of different orchestration patterns.
With a simple asynchronous Python programming model, MicroServing easily reproduces existing static scheduling patterns, such as data parallel and prefill-decode disaggregation in a few lines of code. Dynamic scheduling patterns such as prefill-decode work balancing and distributed context cache management can also be supported by programming with the MicroServing APIs.
In this blog post, we will discuss:
- Common LLM serving orchestration patterns and the problem of existing LLM serving orchestration approaches
- The semantics of MicroServing APIs and how to compose orchestration patterns with them
- Dynamic reconfiguration with MicroServing APIs
- Whether using multiple orchestration patterns via MicroServing APIs improves performance
Background: LLM Serving Orchestration
As LLMs scale, serving systems commonly employ multiple LLM engines and orchestrate their usage through specific scheduling patterns. Two frequently used approaches are:
- Data Parallel: A straightforward pattern where incoming requests are distributed across engines in a round-robin fashion.
- Prefill-Decode Disaggregation: A more advanced strategy that assigns prefill and decode operations to separate engines. To support this division, a KV transfer step sends prefilled KVs from the prefill engine to the decode engine before the decode phase begins.
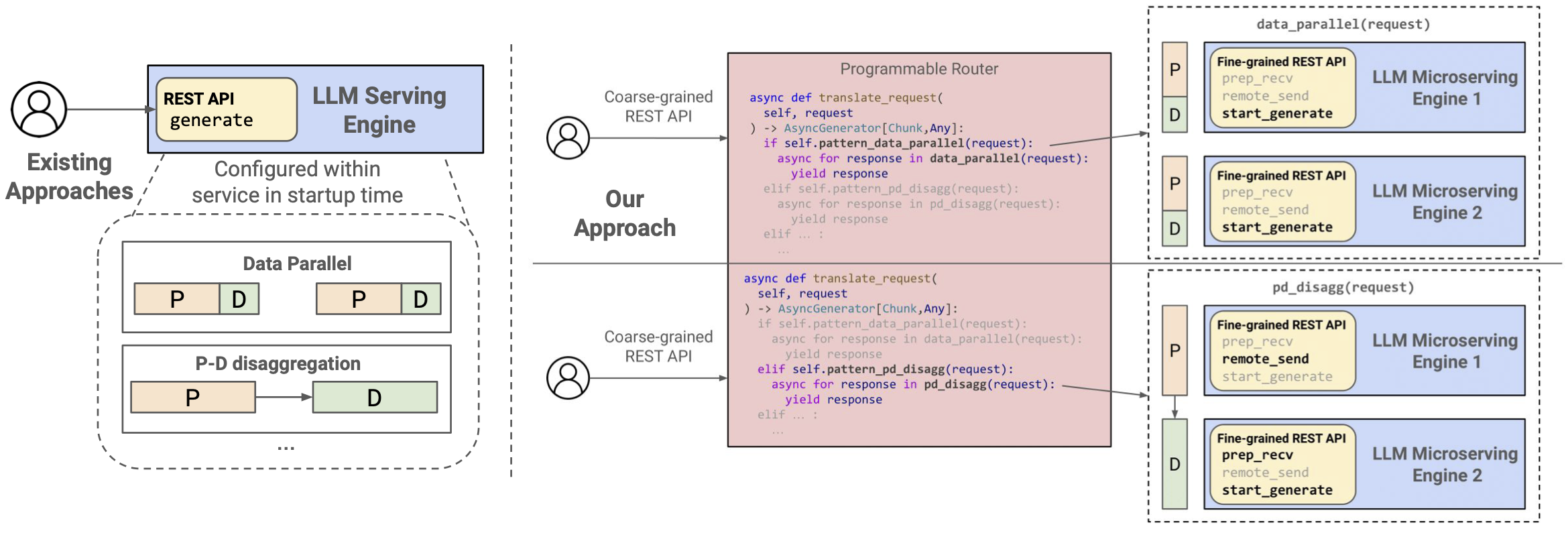
Each orchestration pattern favors different workload characteristics. For example, prefill-decode disaggregation performs better with moderate input lengths but can underperform for very short or very long inputs. With very short or very long inputs, one of the engines has heavy load, while the other has light load, causing computation power and memory bandwidth to be wasted. Ideally, one might switch between different orchestration patterns dynamically as workloads change. However, existing LLM serving systems typically treat token generation for a request as an atomic operation, causing two problems:
- Development: Since engine coordination patterns are usually baked in the background, developers/services built on top of these systems cannot easily customize or experiment with different orchestration patterns without modifying the underlying code.
- Production: Adjusting orchestration strategies at runtime typically involves restarting the system, which leads to service interruptions and complicates production deployments.
Can we introduce programmable APIs to LLM microservices to easily explore different strategies?
MicroServing APIs: Flexible and Fine-Grained Control
MicroServing addresses this limitation by exposing three simple fine-grained APIs that allow precise control over system operations, such as transferring key-value (KV) data between engines and initiating token generation with existing context KV. In addition, the APIs are fully context-cache aware. With these fine-grained APIs, dynamic orchestration patterns can be implemented easily in just a few lines of code.
Core MicroServing APIs
class LLMEngine:
def prep_recv(prompt, end, seq_id) -> Tuple[KVAddr, int]:
"""
One-line summary: Prepare KV entry allocation for receiving from remote.
Detailed explanation: Match prompt[:end] in the context cache of this engine to get the matched prefix length matched_len.
Allocate KV entry for prompt[:end] to prepare receiving the KV data of prompt[matched_len:end] from another engine
Return KV address and matched_len.
"""
pass
def remote_send(prompt, kv_addr_info, recv_rank, begin, end, seq_id):
"""
One-line summary: Send KV to remote
Detailed explanation: Generate KV of prompt[begin:end] on this engine by matching in context cache and prefilling.
Transfer the KV of prompt[begin:end] to the address encoded in kv_addr_info on engine recv_rank.
Return when all KV transfers are finished.
"""
pass
def start_generate(prompt, begin, seq_id) -> AsyncGenerator[TokenId]:
"""
One-line summary: Start token generation
Detailed explanation: Prefill prompt[begin:] on this engine and start decode on this engine.
Return generated tokens.
"""
pass
Note that the APIs are independent of the underlying engine implementation. For example, an engine may decide to pipeline the LLM inference and KV cache transfer layer-by-layer.
Also, the microserving endpoints can be used to run on all RPC style APIs, including REST.
How to compose orchestration patterns with MicroServing APIs?
With MicroServing APIs, users can implement different orchestration patterns on a programmable router. Here is how patterns can be implemented:
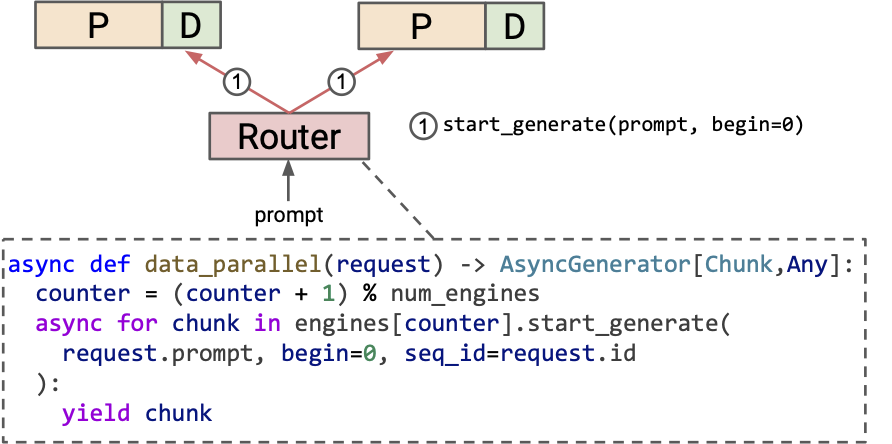
Data parallel (round-robin)
Since no KV transfer is required, we only need to call the start_generate API.
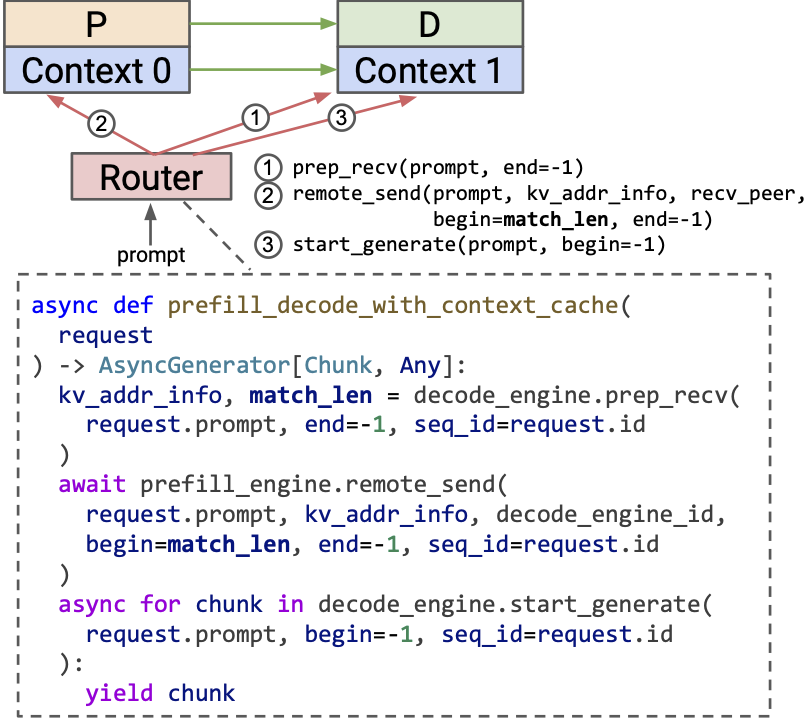
Prefill-decode disaggregation
The sequence of API calls is as follows:
prep_recv(decode engine): Prepares the decode engine to receive KV entries.remote_send(prefill engine): Sends KV entries from the prefill engine.start_generate(decode engine): Initiates token generation on the decode engine.
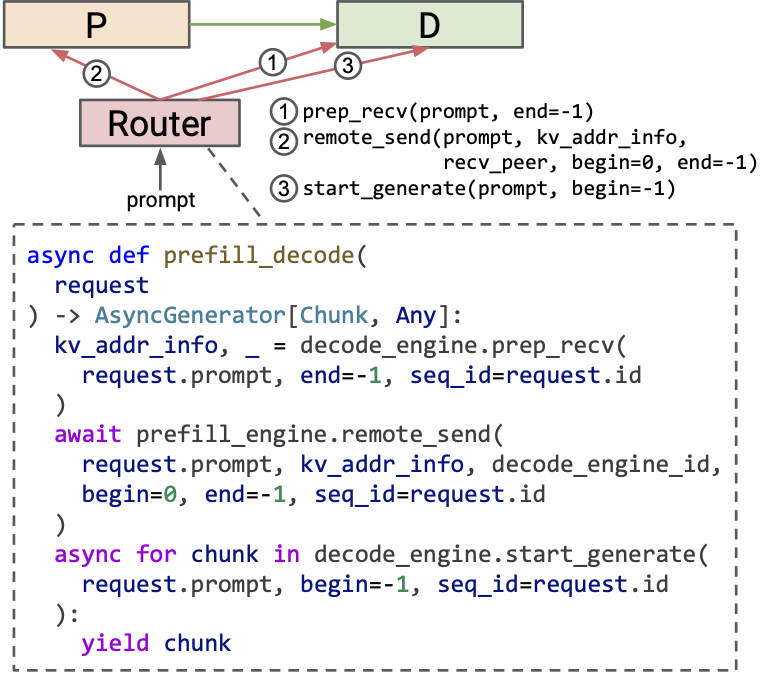
With MicroServing’s context-cache-aware design, this pattern can further utilize context cache. For example, prep_recv returns the matched prefix length on the decode engine. The matched prefix length is then passed to the prefill engine to avoid redundant KV transfer and computation.
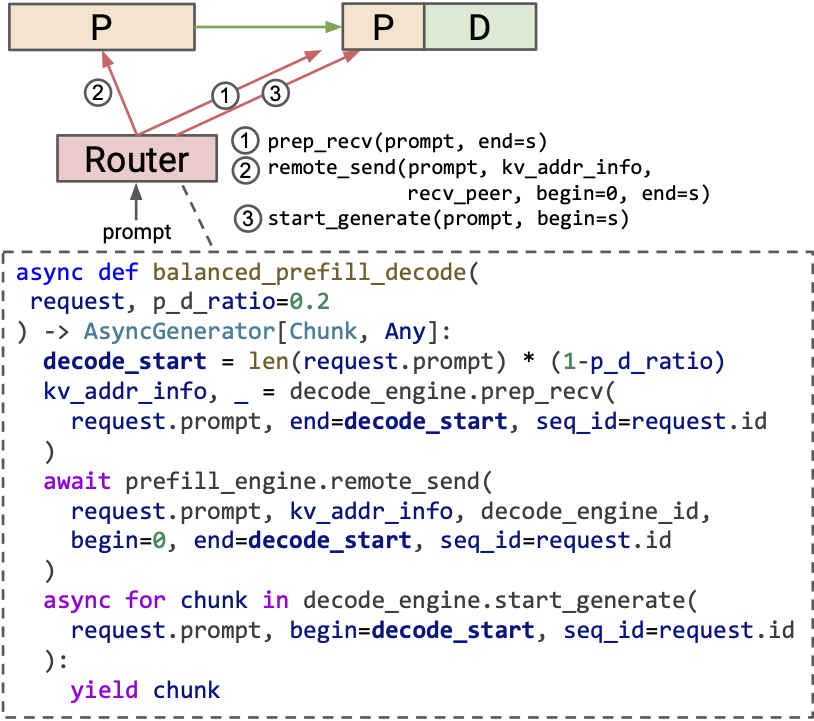
Balanced prefill-decode disaggregation
One issue of prefill-decode disaggregation is that the prefill and decode workloads can get unbalanced. When processing long prompts, the prefill engine can get over-utilized while the decode engine runs with low utilization or even stays idle.
Thanks to the fine-grained MicroServing API, we can explore a different strategy that dynamically offloads a part of the prefill computation into the decode engine. To achieve this, the router needs to decide `decode_start` (the position that the decode engine starts to prefill) and pass it into all the APIs like below.
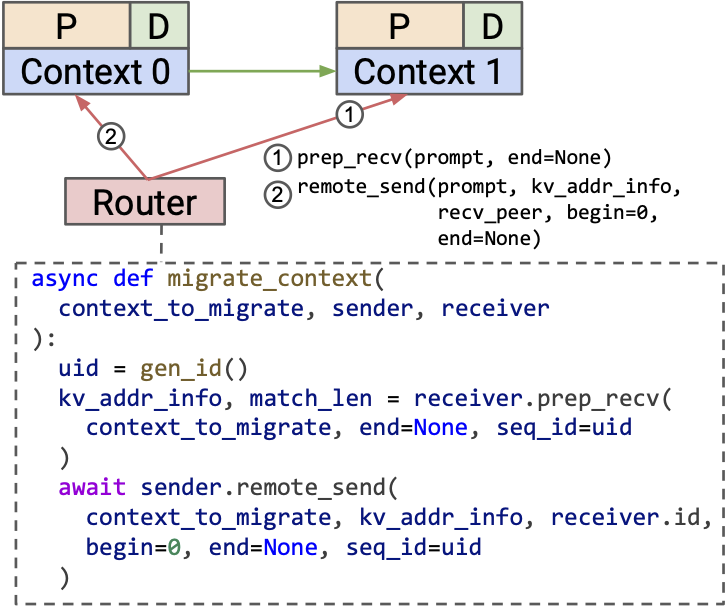
Context Cache Migration
When serving QA workloads, developers tend to place the context cache of different categories into different engines and dispatch incoming traffic based on which context category it matches. Consider there are several engines, with some specialized for the history context and others for the science context. If there are more science requests than history requests, we may want to switch some history engines to science engines through context migration, and vice versa.
MicroServing supports this via prep_recv and remote_send, enabling efficient KV transfers between engines without interrupting service.
Dynamic Reconfiguration: Adapting to Workload Changes
Another advantage of MicroServing’s flexible fine-grained API is its ability to dynamically reconfigure orchestration patterns based on workload characteristics, without changes to the underlying engines. The programmable router allows seamless switching between different orchestration strategies. For example:
- When the Prefill:Decode ratio (time to prefill the input tokens / total time to decode all the output tokens) increases, more prefill computation can be shifted to the decode engine by balanced prefill-decode disaggregation.
- If most of the prompt data is found in the decode engine’s context cache, the system can bypass the prefill engine entirely, directly calling
start_generateto process the non-cached part of the prompt.
This adaptability ensures that MicroServing can optimize performance for different traffic patterns.
The router-side code to reconfigure orchestration pattern can be like below:

In comparison, other systems often implement different orchestration patterns in separate codepaths, which makes it hard to customize new orchestration patterns, and often requires system restart to reconfigure patterns.
Evaluation
We evaluate MicroServe’s programmability for various LLM engine orchestration patterns and the performance of each pattern. The benchmarks are performed with Llama-3.1-70B-Instruct FP8 with 8 H100 SXM GPUs. For each model, we start 2 LLM engines, each of which has tensor parallel degree 4. The engine orchestration patterns evaluated are:
- Data parallel (TP4 in the figure below)
- Prefill-decode disaggregation (1P1D-tp4 in the figure below)
- Balanced prefill-decode disaggregation by moving 10% prefill to the decode engine (1P1D-tp4-balance-0.1 in the figure below)
Although MicroServing cannot dynamically reconfigure tensor parallel degree because of weight resharding issue, we benchmark one LLM engine with tensor parallel degree 8 (TP8 in the figure below) to serve as a strong baseline in low request rate cases.
We use LLMPerf’s synthetic sonnet dataset to construct requests with an average input length of 3000 and an average output length of 100. We fix the request rate ranging from 1.6 to 5.6. The figures will be shown with the x-axis representing the request rate and the y-axis representing TTFT(time to first token)/TPOT(time per output token, the average number of tokens received per second after the first token is received)/JCT(job completion time).
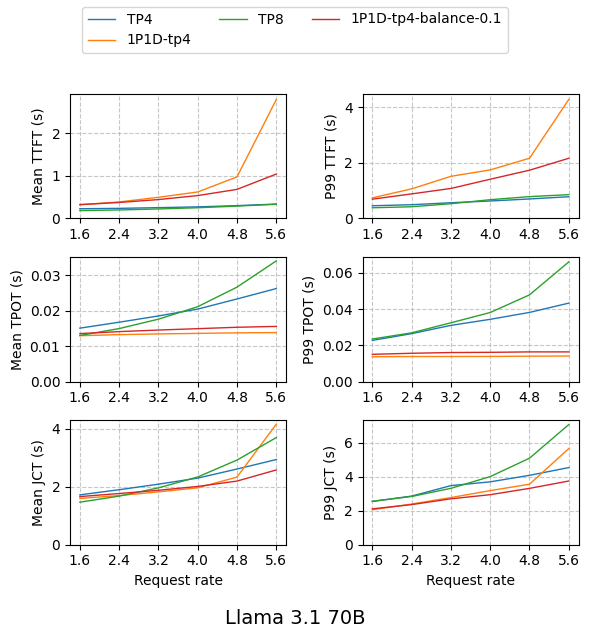
In both figures above, we find that the optimal orchestration pattern under different disaggregation patterns shifts. Using one engine with a larger tensor parallel degree achieves up to 8% lower mean JCT than other strategies when the request rate is 1.6, but it scales poorly as the request rate increases. Prefill-decode disaggregation achieves up to 16% lower mean JCT and 28% P99 JCT than data parallel. This significant speedup attributes to the substantial reduction of TPOT in disaggregation, achieved by eliminating the decode interference caused by long prefill in data parallelism. As the request rate increases, heavier traffic puts more pressure on the prefill engine, so moving part of the prefill computation to decode the engine makes the system balanced and reduces latency.
The evaluation shows that different orchestration patterns have different preferences on the traffic. Some have lower TTFT, which performs better on prefill-dominated workloads. Others have lower TPOT, more suitable on decode-dominated workloads. MicroServing provides microserving APIs and programmability, supporting the representation of various orchestration patterns and the dynamic reconfiguration among these patterns.
Conclusion: Unlocking New Possibilities with MicroServing
MicroServing provides an efficient and flexible framework for orchestrating LLM engines, enabling dynamic adaptation to varying workloads. Its fine-grained APIs allow easy composition of orchestration patterns, from simple round-robin dispatch to complex prefill-decode disaggregation, in only a few lines of router code. MicroServing’s flexibility ensures that developers can optimize their systems without needing to reconfigure engines or disrupt production environments.
By integrating MicroServing with MLC-LLM, we are opening up exciting opportunities for the community to experiment with and improve LLM orchestration patterns. We look forward to collaborating with others to refine dynamic adaptive reconfiguration algorithms and expand the library of orchestration patterns supported by MicroServing. To try out, or learn more about it, please check out the following resources:
Acknowledgments
We thank (alphabetically) SGLang team, TensorRT-LLM team, vLLM team, Zihao Ye (UW) and Kuntai Du (UChicago) for their helpful feedback and discussions. We also thank DistServe team, Memserve team, Mooncake team and Hao Zhang (UCSD) for their exploration of disaggregated LLM serving.
Appendix: Benchmark Instructions
# install nvshmem (https://developer.nvidia.com/nvshmem-downloads)
# if you install on ubuntu 22.04 with apt, /path/to/nvshmem should be /usr/lib/x86_64-linux-gnu/nvshmem/12. Otherwise, check which path includes nvshmem*.so files.
export LD_LIBRARY_PATH=/path/to/nvshmem:$LD_LIBRARY_PATH
# Install MLC-LLM
python3 -m pip install --pre -U --no-index -f https://mlc.ai/wheels "mlc-llm-cu123==0.18.1" "mlc-ai-cu123==0.18.1"
# Llama3 70B
## Compile model for MLC
git clone https://huggingface.co/mlc-ai/Llama-3.1-70B-Instruct-fp8-MLC
### Each command may take about 10 min.
# PD disaggregation
python3 -m mlc_llm compile ./Llama-3.1-70B-Instruct-fp8-MLC --device nvidia/nvidia-h100 --opt O3 --overrides "tensor_parallel_shards=4;disaggregation=1" -o ./Llama-3.1-70B-Instruct-fp8-MLC/lib_disagg.so
# plain TP4
python3 -m mlc_llm compile ./Llama-3.1-70B-Instruct-fp8-MLC --device nvidia/nvidia-h100 --opt O3 --overrides "tensor_parallel_shards=4;disaggregation=0" -o ./Llama-3.1-70B-Instruct-fp8-MLC/lib_no_disagg_tp4.so
# plain TP8
python3 -m mlc_llm compile ./Llama-3.1-70B-Instruct-fp8-MLC --device nvidia/nvidia-h100 --opt O3 --overrides "tensor_parallel_shards=8;disaggregation=0" -o ./Llama-3.1-70B-Instruct-fp8-MLC/lib_no_disagg_tp8.so
## Launch 2 engines with PD disaggregation
python -m mlc_llm router ./Llama-3.1-70B-Instruct-fp8-MLC --model-lib ./Llama-3.1-70B-Instruct-fp8-MLC/lib_disagg.so --router-mode disagg --pd-balance-factor 0.0 --router-port 9123 --endpoint-hosts 127.0.0.1,127.0.0.1 --endpoint-ports 9124 9125 --endpoint-num-gpus 4 4
## Launch 2 engines with balanced PD disaggregation
python -m mlc_llm router ./Llama-3.1-70B-Instruct-fp8-MLC --model-lib ./Llama-3.1-70B-Instruct-fp8-MLC/lib_disagg.so --router-mode disagg --pd-balance-factor 0.1 --router-port 9123 --endpoint-hosts 127.0.0.1,127.0.0.1 --endpoint-ports 9124 9125 --endpoint-num-gpus 4 4
## Launch 2 engines with data parallel
python -m mlc_llm router ./Llama-3.1-70B-Instruct-fp8-MLC --model-lib ./Llama-3.1-70B-Instruct-fp8-MLC/lib_no_disagg_tp4.so --router-mode round-robin --router-port 9123 --endpoint-hosts 127.0.0.1,127.0.0.1 --endpoint-ports 9124 9125 --endpoint-num-gpus 4 4
## Launch 1 engine with TP 8
python3 -m mlc_llm serve ./Llama-3.1-70B-Instruct-fp8-MLC --model-lib ./Llama-3.1-70B-Instruct-fp8-MLC/lib_no_disagg_tp8.so --mode server --host 127.0.0.1 --port 9123 --device cuda --prefix-cache-mode disable --enable-debug
## Run benchmark
wget https://raw.githubusercontent.com/ray-project/llmperf/refs/heads/main/src/llmperf/sonnet.txt
python -m mlc_llm.bench --dataset llmperf --dataset-path sonnet.txt --tokenizer ./Llama-3.1-70B-Instruct-fp8-MLC/ --per-gpu-workload --num-request 100 --num-warmup-request 40 --num-gpus 8 --request-rate 0.2,0.3,0.4,0.5,0.6,0.7 --input-len 3000 --input-len-std 5 --output-len 100 --output-len-std 5 --temperature 0.6 --top-p 0.9 --ignore-eos --host 127.0.0.1 --port 9123