TL;DR. XGrammar-2 is a major upgrade of XGrammar built for agent applications. It introduces Structural Tag, a composable JSON protocol that uniformly expresses OpenAI harmony format, tool calling, reasoning channels, and any custom output structure, exposed directly through serving engines’ API. Multiple efficiency optimizations, such as cross-grammar caching, repetition-state compression, and batching and speculative decoding support, ensure fast processing and minimal overhead even for huge structures. XGrammar-2 has been adopted by leading frontier AI labs and leading AI companies in their products. SGLang, vLLM, TensorRT-LLM, and MLC-LLM integrate it for strict tool calling and expose customization through API.
Over the past year, agent applications, from Claude Code to OpenClaw, have grown rapidly in complexity. These systems define sophisticated harnesses that LLMs must interact with by producing specific output structures, such as tool calls and structured JSON. As these structures grow more complex, they pose greater challenges for LLMs to follow reliably.
More than a year ago, we released XGrammar, which uses constrained decoding to guarantee 100% structural correctness with near-zero overhead. Since then, many organizations and open-source projects have adopted XGrammar, with active community discussion and contributions. While XGrammar already handles JSON and other common structures efficiently, emerging agent applications demand far more complex structures, raising new challenges in both flexibility and efficiency.
To address these challenges, we are excited to introduce XGrammar-2: a major upgrade purpose-built for agent applications. It lets you easily express complex structures for agents, delivers high performance even for very large grammars, offers native cross-platform APIs, and remains fully backward compatible. In this post, we first recap XGrammar and then walk through the key features of XGrammar-2.
A Recap of XGrammar
XGrammar uses constrained decoding to ensure LLM outputs conform 100% to a given structure. At each decoding step, constrained decoding produces a mask that blocks invalid tokens according to the structure. During sampling, invalid tokens are assigned zero probability, so only valid tokens will be generated. XGrammar’s key insight is precomputing an efficient token mask cache at compilation time, which substantially reduces mask generation time and achieves near-zero overhead during generation.
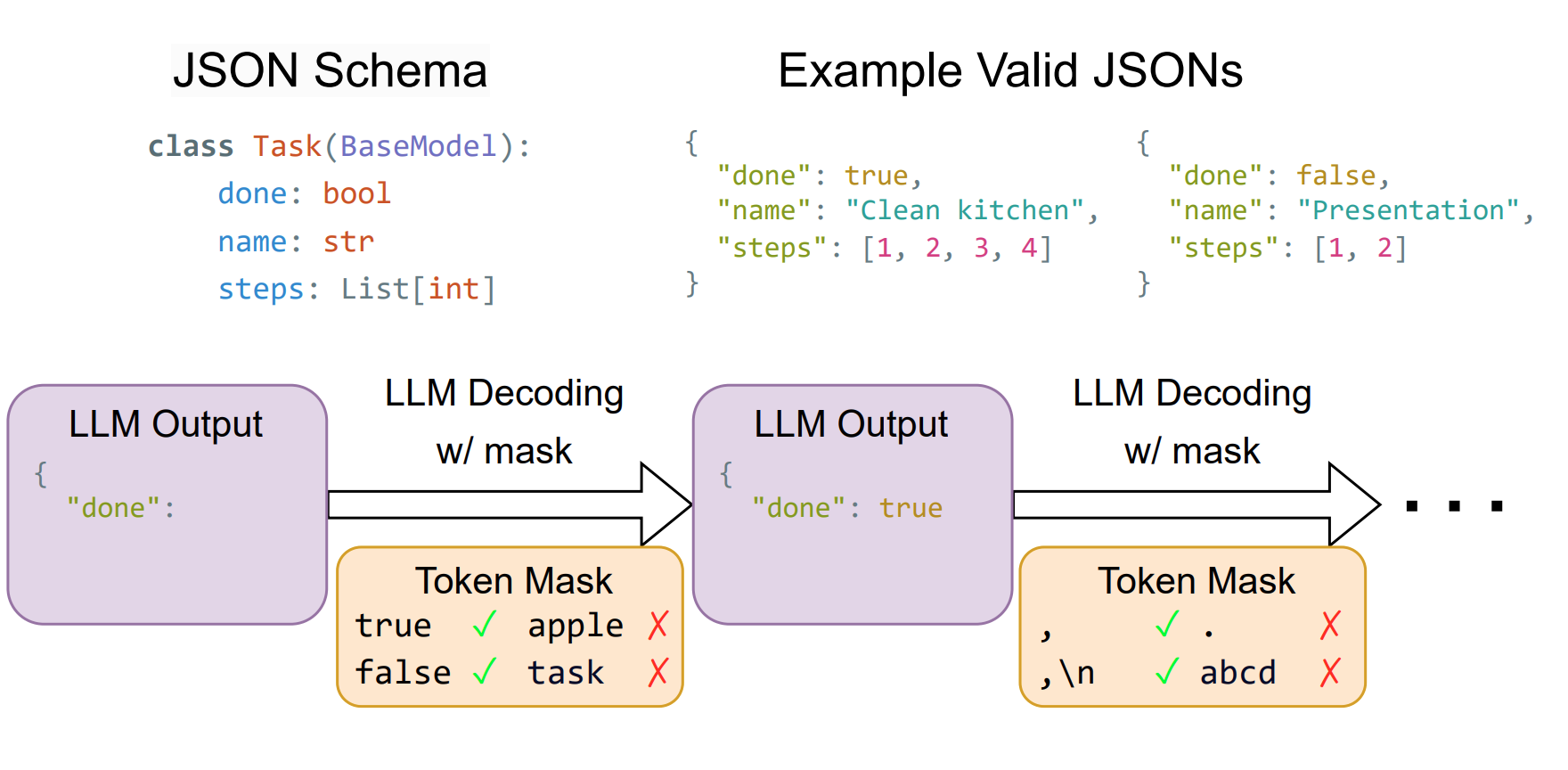
XGrammar is best used to enforce format constraints, not to change the semantics of an LLM’s response. It helps downstream programs avoid fatal failures from malformed outputs, while keeping the impact on the model’s accuracy minimal. In our experiments, XGrammar ensured 100% valid tool-calling formats and, in many cases, improved tool-calling accuracy by eliminating format-related failures.
Structural Tag: Abstraction for All Tool Calling and Complex Structures
Agent applications are pushing LLMs to follow increasingly complex formats. One representative example is the OpenAI Harmony Format, which splits output into multiple channels, including reasoning, tool calling, and final response, each with its own format. Each open-source model also define their own tool calling formats. Supporting all of these requires significant effort from serving engines and downstream applications, and may still fail to match the official specification.
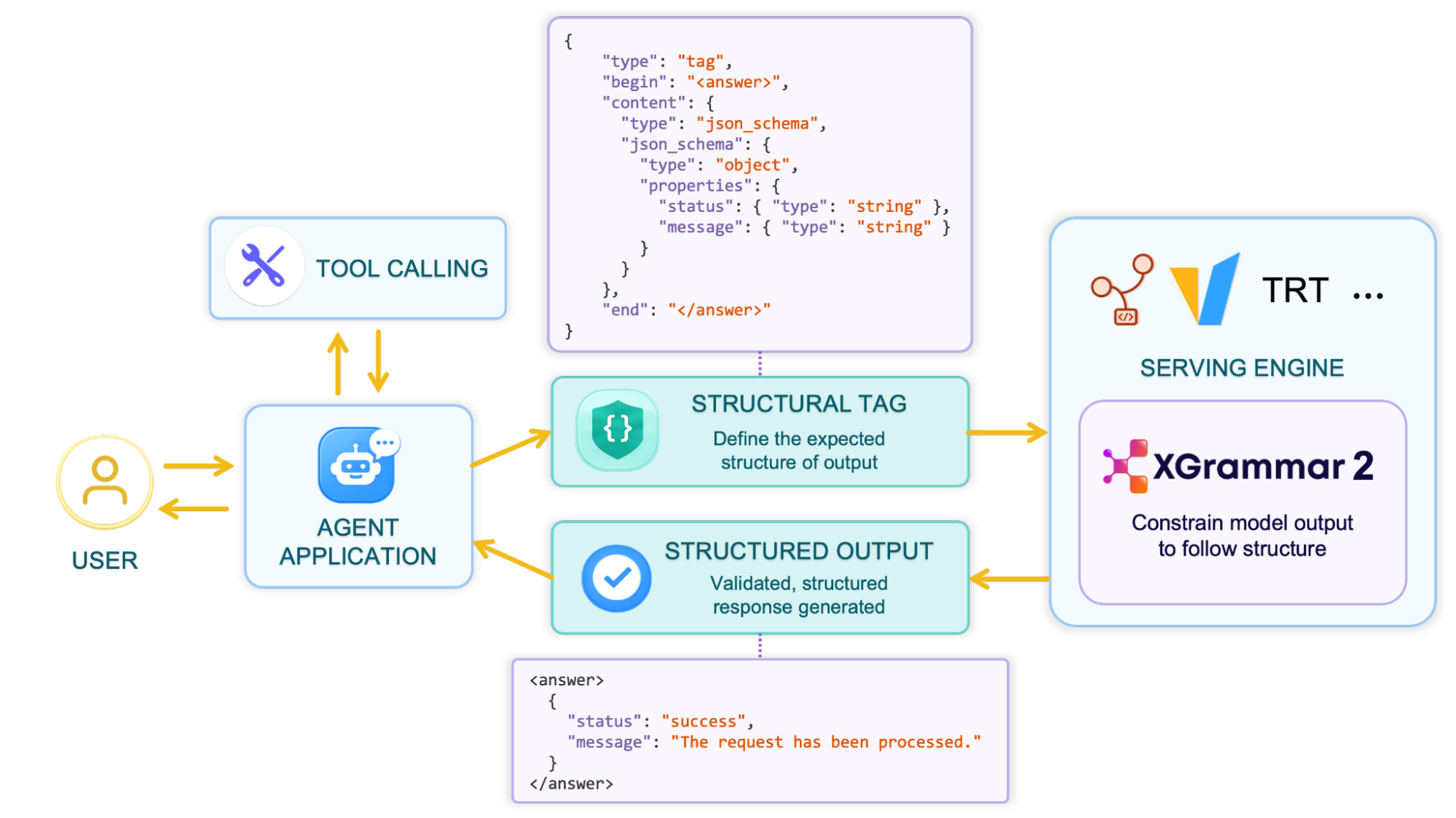
XGrammar-2 introduces Structural Tag, a JSON-based DSL that provides a unified, lightweight, and extensible way to describe the diverse structures agents need, from OpenAI Harmony format to open-source model tool calling protocols and many other custom formats.
For example, a DeepSeek V4 output with reasoning and a tool call looks like this:
Let me check the weather in Beijing.</think>
I'll look that up for you.
<|DSML|tool_calls>
<|DSML|invoke name="get_weather">
<|DSML|parameter name="city" string="true">Beijing</|DSML|parameter>
</|DSML|invoke>
</|DSML|tool_calls>
There are two distinct parts here. The first part is free-form reasoning that continues until the </think> token. The second part is either more free text or a structured tool call, triggered when the model emits the <|DSML|tool_calls> marker. The corresponding Structural Tag captures this two-part structure directly:
{
"type": "structural_tag",
"format": {
"type": "sequence",
"elements": [
/* Reasoning Part */
{ "type": "tag", "begin": "", "content": { "type": "any_text" }, "end": "</think>" },
/* Output & Tool Calling Part */
{
"type": "triggered_tags",
"triggers": ["<|DSML|tool_calls>"],
"tags": [
{
/* DeepSeek Tool Calling Format */
"type": "tag",
"begin": "<|DSML|tool_calls>\n",
"content": {
"type": "tag",
"begin": "<|DSML|invoke name=\"get_weather\">\n",
"content": {
"type": "json_schema", "json_schema": {...}, "style": "deepseek_xml"
},
"end": "</|DSML|invoke>\n"
},
"end": "</|DSML|tool_calls>\n"
}
],
"excludes": ["<think>", "</think>"]
}
]
}
}
This example comprises five Structural Tag types, each with a clear role:
- Sequence chains two parts together: the reasoning section followed by the tool-call section.
- Tag matches a
beginmarker, some constrained content, and anendmarker. Here the reasoning tag has an emptybeginbecause the chat template already appends to the prompt. - AnyText matches arbitrary text until the enclosing tag’s
endmarker, which is exactly what we need for free-form reasoning content. - TriggeredTags lets the model produce free text by default, but once it emits a trigger string, the output must follow the corresponding structured tag. The
excludesfield prevents<think>and</think>from appearing in the final output section. - JSONSchema constrains the tool’s arguments to a given schema. The
style="deepseek_xml"option tells XGrammar to expect arguments in DeepSeek’s XML parameter format rather than raw JSON.
The key idea behind Structural Tag is that these types are composable. JSON Schema, regex, literal strings, and token IDs are all first-class atomic types within the language. By nesting and combining them, you can describe arbitrarily complex output structures, from a simple JSON response to a multi-part reasoning-plus-tool-call format like the one above.
XGrammar ships with built-in Structural Tags for common models such as DeepSeek V4, Qwen 3.6, GPT-OSS, and more. The structural tag is already integrated into SGLang, vLLM, TensorRT-LLM, and other serving engines, providing strict tool calling and reasoning support out of the box.
Structural Tag is also exposed as an OpenAI-compatible response format by serving engines, so you can customize your own output structure for your agent application:
# Assume the client is connected to a hosted SGLang, vLLM, or TensorRT-LLM server.
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-V4",
messages=[...],
extra_body={
"response_format": {
"type": "structural_tag",
"format": {
"type": "tag",
"begin": "<answer>",
"content": {
"type": "json_schema",
"json_schema": {
"type": "object",
"properties": {
"status": { "type": "string" },
"message": { "type": "string" }
}
}
},
"end": "</answer>",
}
}
}
)
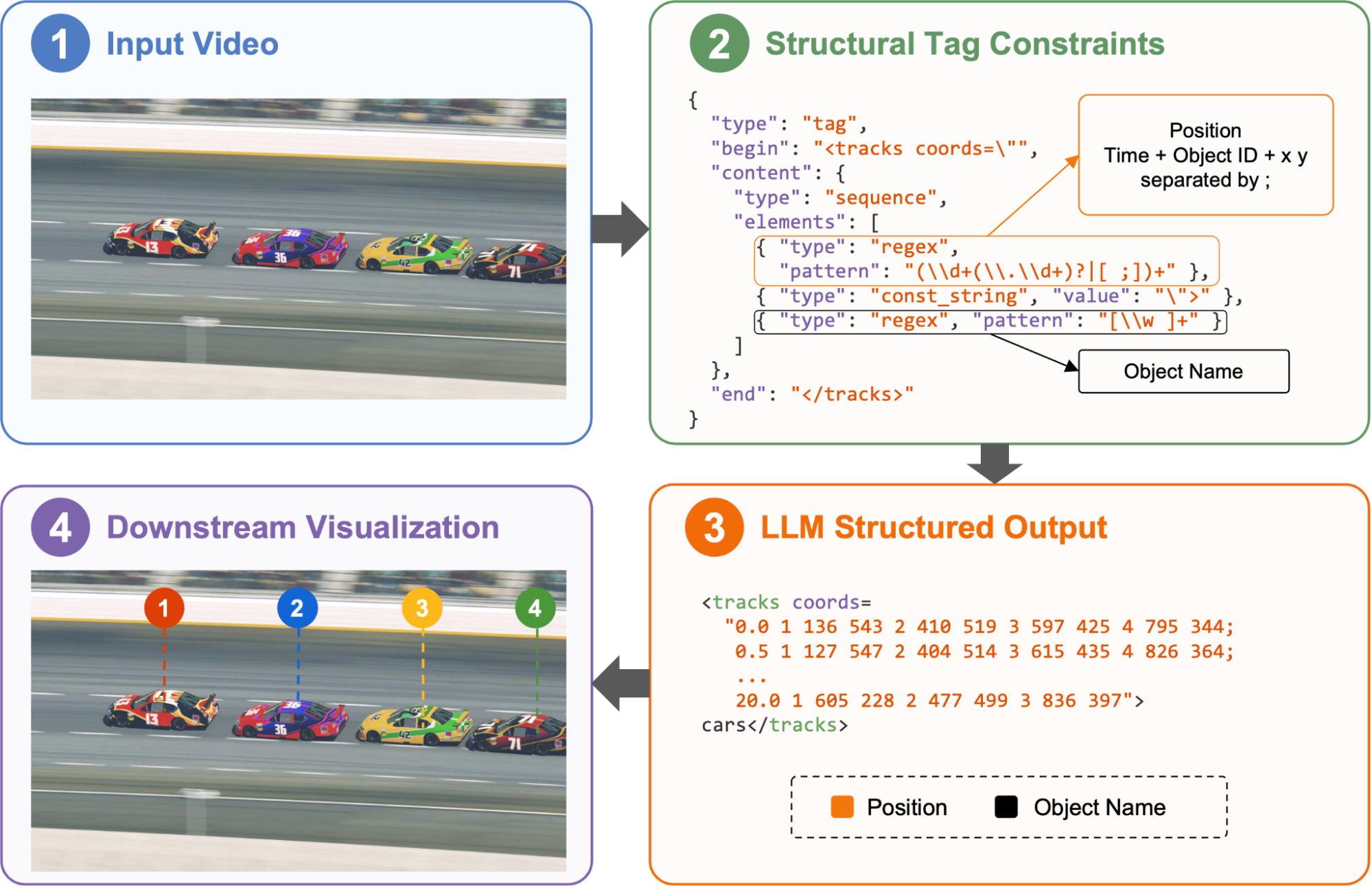
For example, we built a multimodal video agent with Molmo-2 model that detects objects in videos and renders annotated outputs. By specifying the desired format with structural tags, including each object’s time range, location, and name, we obtain precise model outputs that can be mapped directly onto the video in downstream processing.
Scaling to Complex Structures with Minimal Overhead
The structures agents rely on are also growing larger. Tool calling in particular can involve dozens or even hundreds of tools per session. This puts enormous pressure on structured generation: both grammar preprocessing and mask generation incur substantial overhead, slowing down the entire request. XGrammar-2 introduces a series of optimizations to tackle complex structures and ensure that even very large grammars incur only minimal overhead.
Cross-grammar Cache
Different grammar structures and different parts of the same grammar often share many common sub-structures. For example, different JSON schemas all share the same string field described by {"type": "string"}. These repeated structures can be fully reused during preprocessing. XGrammar-2 implements an automaton-based hierarchical hashing algorithm that automatically finds shared parts within and across grammars, maximizing reuse of grammar preprocessing. In JSON Schema compilation for 50 tools, our experiments show that nearly 50% of structures end up reused.
Repetition State Compression
Repetition is common in many structures. For example, an array of up to 1M items described by {"type": "array", "maxItems": 1000000} contains a large repeated component. If handled naively, preprocessing such a grammar requires O(repetition_count) time. XGrammar-2 compresses this to O(1) by introducing a new grammar primitive, repetition, whose size stays constant regardless of how many repetitions are allowed. We also designed specialized parsing and token mask cache algorithms so that this new primitive is just as easy to handle as any other grammar construct. For complex JSON schema structures, our experiment shows repetition compression reduces the compression from 534 ms to 5.37 ms, a 100x time reduction.
Serving and Speculative Decoding Support
XGrammar-2 also supports batching and speculative decoding, both key features in modern serving systems. For batching, it provides batch APIs that flexibly combine and process multiple grammar states in one pass on the C++ side, avoiding Python-side loops and reducing batching overhead.
For speculative decoding, XGrammar-2 provides traverse_draft_tree to traverse a draft tree once and generate masks for all nodes. For finer-grained control, grammar states can also be forked and rolled back to walk through the tree manually.
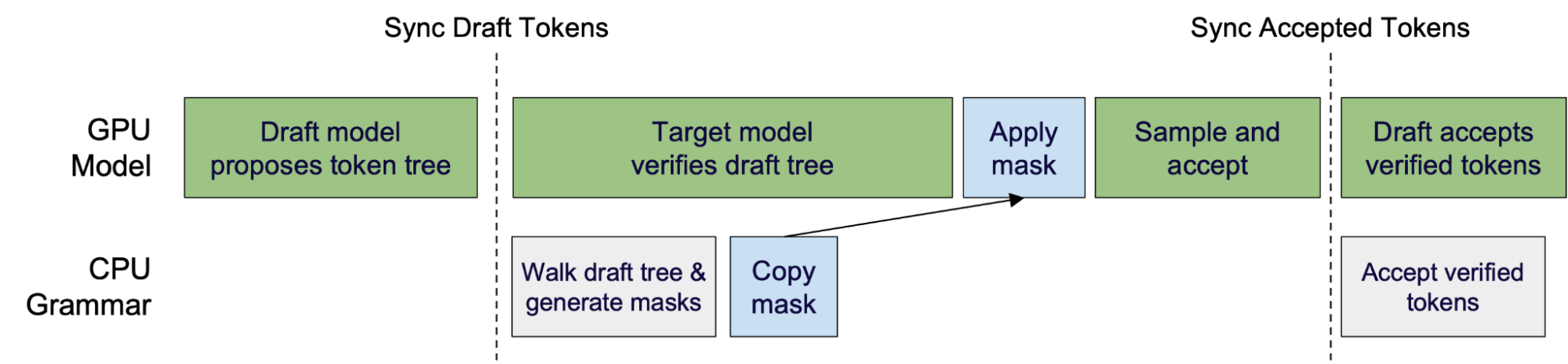
This also enables constrained decoding to overlap with speculative decoding. While the target model verifies the draft tree on the GPU, XGrammar walks the same tree on the CPU and generates masks in parallel, reducing overhead further. We collaborated with serving engine teams to integrate this pattern into speculative decoding pipelines.
Combined with other system-level optimizations, XGrammar-2’s performance remains scalable even with very large structures.
Deploy Structured Generation Everywhere
Agents are not only deployed on high-performance servers; they also run on edge devices, personal devices, and a wide variety of systems. We therefore want XGrammar-2 to support a broad range of AI systems, for example:
- On-device scenarios typically use small models, which benefit from constrained decoding even more than large ones, yet they often lack a Python environment.
- Production serving engines written in C++ or Rust for high performance.
- AI systems built on JAX or other frameworks rather than PyTorch.
XGrammar-2 leverages TVM-FFI, an open ABI and FFI library for ML systems, to provide unified support across these platforms and expose a consistent cross-language interface. XGrammar-2 now offers:
- APIs in Python, C++, Rust, and JS
- Support for PyTorch, JAX, and MLX
- Support for Windows, macOS, and Linux
- Support for heterogeneous hardware
Evaluation
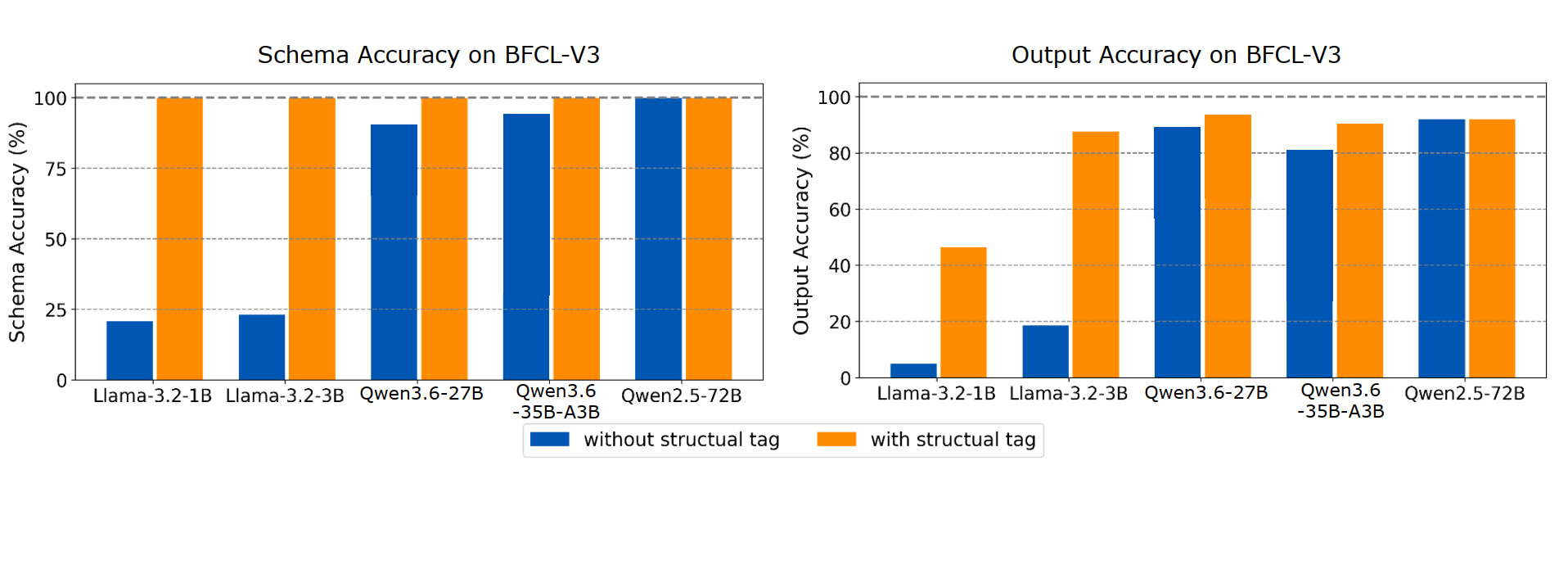
We evaluate XGrammar-2 on both accuracy and efficiency. For accuracy, we use the BFCL-V3 simple and parallel subsets across four representative models of different scales, measuring both schema accuracy and output accuracy in multi-tool settings. The Structural Tag improves schema accuracy to 100%, ensuring all tool calls conform to the target JSON schema. It also leads to substantial gains in output accuracy, especially for smaller models, as shown in Figure 1.
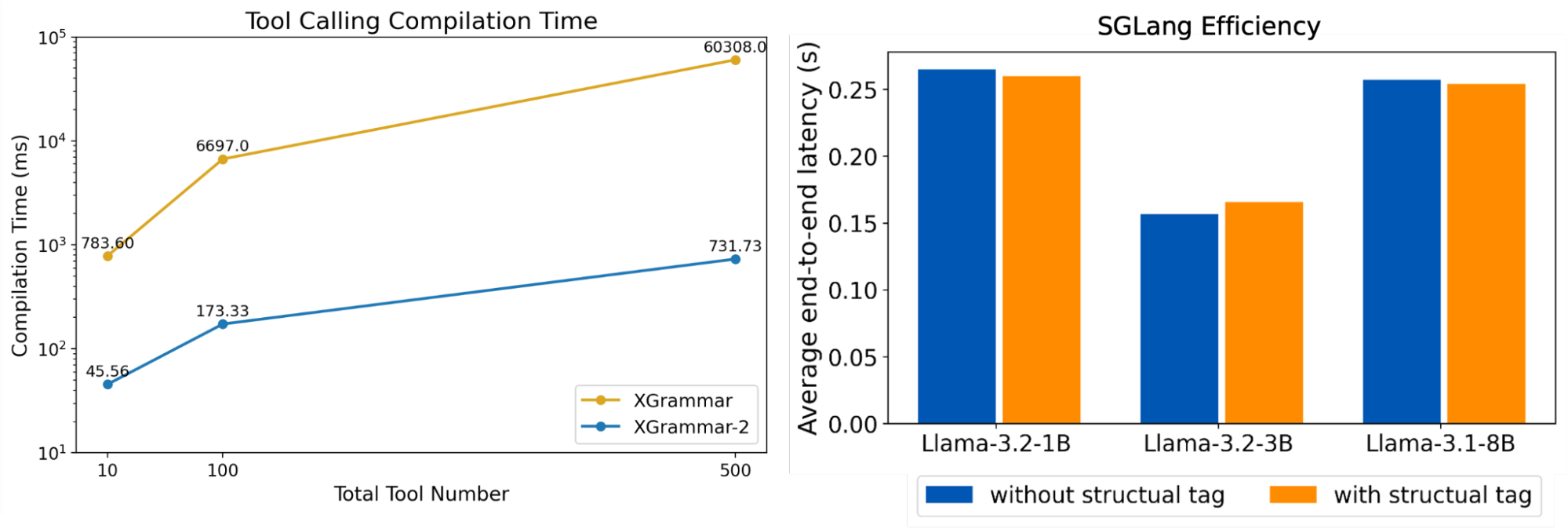
For efficiency, we measure grammar compilation time as the number of tools scales from 10 to 500. XGrammar-2 achieves up to an 80× compilation speedup over XGrammar. We also integrate XGrammar-2 into SGLang and measure end-to-end request latency on the same datasets and models. In a single-batch setting with warm-up and comparable output lengths, the Structural Tag adds minimal latency overhead, as shown in Figure 2.
Overall, XGrammar-2 improves both schema reliability and tool-calling accuracy while keeping overhead minimal, making it well-suited for agent applications that rely on reliable tool use. The evaluation script can be found at the end of the blog.
Adoption, Integration, and Future Work
We have introduced XGrammar-2, a release that brings a series of new abstractions and optimizations designed to provide comprehensive support for agent applications.
XGrammar-2 has been adopted by leading frontier AI labs in their latest models and by leading AI companies in their products. For a list of collaborators, please check out the collaborator list.
XGrammar-2 has been integrated into mainstream LLM serving engines, including SGLang, vLLM, TensorRT-LLM, and MLC-LLM. XGrammar enables these engines to support strict mode tool calling for popular models such as DeepSeek V4 and Qwen 3.6, which can be used directly through API calls. These models also support requests that use the Structural Tag in the response_format field of the request to generate outputs in custom formats.
Going forward, we plan to collaborate with partners to bring XGrammar to even more environments. We are committed to providing a solid foundation for agent harnesses and laying the groundwork for a diverse ecosystem of agent applications. To get started or learn more, please check out the following resources:
Acknowledgments
We are grateful to xAI, Bosch, Databricks, DeepSeek Infra, Google Vertex AI, RadixArk, SGLang, TensorRT-LLM, and vLLM teams, as well as other collaborators, for their support and collaboration. We also thank, alphabetically, Ke Bao, Ben Browning, Russell Bryant, Bingqing Chen, Jeffrey Chen, Lequn Chen, Cade Daniel, Flora Feng, Michael Goin, Hanchen Li, Jialin Ouyang, Aaron Pham, Xinyuan Tong, Alex Trotta, Lion Ushiromiya, Qingyuan Wang, Xingbo Wang, Yi Wang, Ying Wang, Kan Wu, Liangsheng Yin, Chenyang Yu, Lianmin Zheng, Qi Zheng, Enwei Zhu, and Ligeng Zhu, for their engineering support, integration work, discussions, review, and feedback.
The traverse draft tree idea was first proposed by the SGLang team and has been integrated into SGLang. We additionally thank the TensorRT-LLM team for the CUDA graph integration and their blog post on combining guided decoding and speculative decoding.