TL;DR. PithTrain is a compact, agent-native Mixture-of-Experts (MoE) training framework, in about 11K lines of Python. It trains as fast as mature production frameworks, and it is substantially cheaper for an AI coding agent to work with: on a suite of real training-system tasks, the same agent gets the job done with up to 62% fewer turns and 64% less GPU time than on production frameworks. We call this second axis agent-task efficiency, and as coding agents take on more of building and maintaining these systems, we think it deserves to sit alongside throughput as a metric worth optimizing.
- GitHub: github.com/mlc-ai/pith-train
- Paper: arxiv.org/abs/2605.31463

Why we built it
In just a couple of years, AI coding agents have gone from autocomplete to genuine collaborators. They fix bugs, ship features, review code, and operate infrastructure, and they are increasingly trusted with serious systems work that once demanded deep, specialized expertise. The shift is real, and it is accelerating. Some of that work is building and evolving the systems that train large models. Mixture-of-Experts (MoE) is now the dominant architecture for frontier models, and the frameworks that train them are remarkable pieces of engineering, refined over years to deliver broad model coverage, peak throughput, and support across many hardware platforms. But they were built for a specific audience: expert human engineers. At the time that work was done, an AI agent reading and modifying the code simply wasn’t part of the picture.
In particular, an agent reads a codebase differently than a person does. The very patterns that serve a human expert can work against an agent that operates turn by turn through a fixed set of tools. One layer skeleton reused across many models means more files to trace before the agent can tell what actually runs at a given call site. Peak-performance kernels written in compiled extensions introduce a language boundary, where an error surfaces with no Python line to anchor on and any change forces a rebuild. None of this is a flaw in those frameworks. Designing for an agent simply was not a goal anyone had yet, and what such a design should look like is still an open question.
People hit the same wall. Learning how MoE training works under the hood, or extending one of these systems, means navigating the same scale and indirection that slow an agent down. A codebase small enough to read end to end is easier for a person to learn from and build on, and that was part of our motivation from the start. There is also a gap in how we measure progress. When we evaluate a training framework, we report training throughput, such as tokens per second and MFU, and stop there. The cost of understanding, operating, and extending the system stays invisible, even as agents take on more and more of that work.

So we asked a simple question: can an MoE training system be cheap for an agent to work on without giving up production-grade speed? PithTrain is our attempt at a yes. It is built for dual efficiency: strong training throughput together with high agent-task efficiency, the cost of using a coding agent to understand, operate, and extend the system. We make that cost concrete and measure it directly: how long a session runs, how much GPU time it consumes, how many back-and-forth turns it takes, how much the agent reads each turn, and how much it writes.
What PithTrain is
PithTrain is an end-to-end MoE training system: give it a tokenized corpus and it handles the rest, from distributed setup through to HuggingFace-compatible checkpoints. It trains models like Qwen3-MoE and GPT-OSS on NVIDIA Hopper and Blackwell GPUs, in BF16 or FP8, and scales across four kinds of parallelism: pipeline, data (FSDP), context, and expert. For pipeline parallelism it uses DualPipeV, an overlapped schedule that hides expert-parallel communication behind compute.
The whole thing is organized in three layers: an application layer (the training loop), an engine (the DualPipeV scheduler, optimizer, and checkpointing), and an operator layer (a few custom Triton kernels). It is about 11K lines in total.

What makes it agent-native
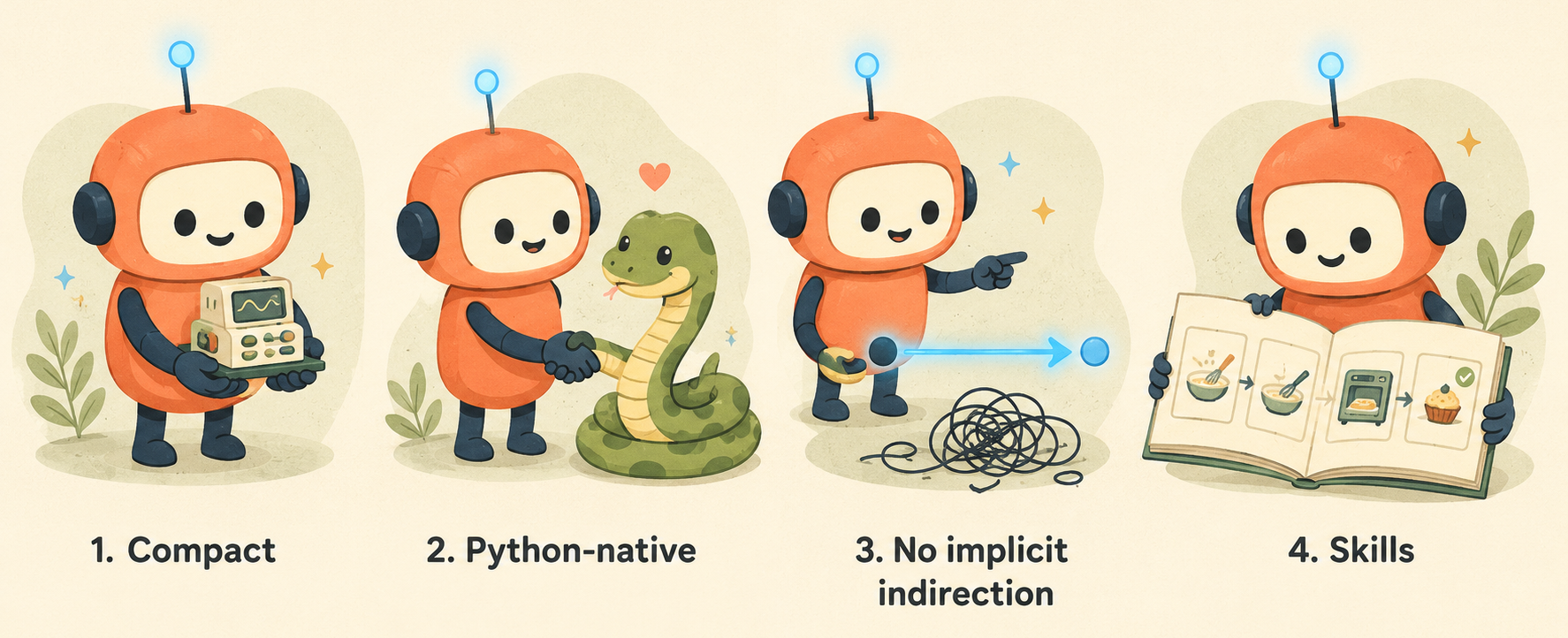
PithTrain is built on four design principles. None of them is novel on its own; what’s new is treating them as primary constraints for a training system and measuring what they buy you.
1. Keep it compact. PithTrain covers exactly what a distributed MoE training system needs (about 11K lines) versus well north of 150K for production cores. Less code means less to search, fewer cross-file dependencies to track, and less to read before you’re sure a change is complete. It also means that with today’s 200K–1M-token context windows, an agent can hold the entire framework in one pass instead of repeatedly grepping its way around. We treat compactness as a constraint on growth: PithTrain may grow, but every addition has to earn its place against these four principles.
2. Stay in Python. The whole stack is pure Python (orchestration, scheduling, parallelism, all of it), so an agent navigates one language, gets readable Python tracebacks instead of opaque native errors, and never waits on a compiled-extension rebuild. The handful of custom kernels we do write live in Triton, a Python-embedded DSL that JIT-compiles at runtime.
3. No implicit indirection. Production frameworks assemble many model variants from a shared layer skeleton through indirection: a stored callable, a registry, a string-keyed lookup resolved at runtime. That’s great for reuse, but it means what runs at a call site often can’t be worked out by reading that call site alone. PithTrain uses direct calls, and each model lives in its own self-contained file under models/. We trade cross-model reuse for the ability to read a model top to bottom in one place.
4. Ship the agent skills. Some knowledge you can’t get from reading code: how to launch a multi-GPU run, what a healthy loss curve looks like, how to capture a clean profile. So we package it. An agent skill is a short, on-demand playbook the agent loads when a task calls for it. PithTrain ships skills for the recurring chores (porting a model, profiling memory, capturing an Nsight Systems trace, checking correctness), and each one ends in a script that returns a hard PASS/FAIL, not the agent’s own optimistic read of its work.
That’s the design. The rest of this post is about whether it actually pays off: first on throughput, then on the axis we built it for.
It still trains fast
Compactness is worthless if the thing is slow, so this was the first bar to clear. Across a range of MoE models (single-node and multi-node, H100 and B200, BF16 and FP8), PithTrain reaches throughput parity with mature production frameworks, with the gap never exceeding ~1.4% on any configuration we tested. It gets there with standard, well-understood optimizations rather than anything exotic: DualPipeV’s five-stage compute–communication overlap, full-graph torch.compile, weight-gradient delay, fused SwiGLU kernels, expert-dispatch deduplication, and an FP8 weight cache across micro-batches. The full per-configuration table is in the paper.
Training correctness holds up too. Under matched configuration, PithTrain’s pretraining loss curve tracks a production framework’s step for step over billions of tokens, and downstream accuracy across six standard benchmarks stays within statistical noise (the paper has the full curves and per-benchmark numbers). Checkpoints export to HuggingFace format and run directly in vLLM, SGLang, and lm-evaluation-harness, so what you train here is something you can actually use elsewhere.
Parity established. Now the fun part.
What it’s like to point an agent at it
Throughput we can compare with a stopwatch. Agent-task efficiency is fuzzier, so we measured it directly, and the setup is worth a sentence because it’s a little backwards. The usual benchmarks for coding agents (SWE-bench and others) hold the codebase fixed and swap in different agents, to score how good the agent is. We flipped that: same agent, same task, every time: only the framework underneath changes. Whatever difference shows up in the agent’s effort is the framework’s doing, not the model’s.
We used Claude Code (Opus 4.7) as the fixed agent and gave it the kinds of things researchers actually do to a training framework, in three flavors:
- Understand. Answer questions like “how is the device mesh built?” without touching anything.
- Operate. Set it up, run it, instrument it: get training going, collect a routing trace, capture a profile and name the three hottest kernels.
- Extend. Port a brand-new architecture end-to-end (Differential Transformer, DynMoE, MoBA, MoE++), checked against the paper.
Crucially, the agent finished every task on every framework: nothing failed outright. So the question isn’t whether the work gets done (it always did) but how much effort it takes to get there. We ran each task three times and report medians; lower is better throughout.
Understand. Answering a question about the code is really just finding where the behavior lives. A small codebase with no implicit indirection makes that search short: across twelve questions, the agent reached the correct answer in up to 67% fewer turns on PithTrain than on Megatron-LM, reading less each turn to get there, and every answer graded correct, on every framework.
Operate. Here the agent has to stand the system up and produce an artifact. On PithTrain it also reaches for the relevant in-repo skill on its own: the “report the heaviest kernels” task, for instance, fires off capture-nsys-profile without being told.
| Task | Framework | GPU Time (min) | Agent Turns | Output Tokens |
|---|---|---|---|---|
| Getting Started | Megatron-LM | 5.4 | 88 | 26.9K |
| TorchTitan | 5.2 | 54 | 15.8K | |
| PithTrain | 3.1 | 26 | 5.8K | |
| Train & Evaluate | Megatron-LM | 36.0 | 163 | 52.9K |
| TorchTitan | 36.3 | 212 | 97.8K | |
| PithTrain | 22.7 | 92 | 34.2K | |
| Collect Routing Trace | Megatron-LM | 5.5 | 112 | 102.1K |
| TorchTitan | 10.4 | 103 | 84.7K | |
| PithTrain | 2.8 | 58 | 56.2K | |
| Report Heavy Kernels | Megatron-LM | 12.1 | 60 | 23.9K |
| TorchTitan | 6.7 | 40 | 22.5K | |
| PithTrain | 3.6 | 42 | 16.0K |
Just-get-started goes from 88 turns to 26. Across these tasks the agent uses up to 70% fewer turns and writes up to 78% fewer tokens than on Megatron-LM: partly the compact codebase, partly those self-invoked skills.
Extend. This is where framework design has its biggest say, because porting a new architecture is a loop: edit, run training, read the crash, edit again. Every rerun costs GPU time and every confusing failure costs turns.
| Task | Framework | GPU Time (min) | Agent Turns | Output Tokens |
|---|---|---|---|---|
| Differential Transformer | Megatron-LM | 33.7 | 125 | 57.1K |
| TorchTitan | 40.3 | 58 | 36.0K | |
| PithTrain | 27.6 | 47 | 25.4K | |
| DynMoE | Megatron-LM | 49.1 | 199 | 115.2K |
| TorchTitan | 94.4 | 197 | 161.3K | |
| PithTrain | 41.9 | 76 | 76.4K | |
| MoBA | Megatron-LM | 49.5 | 134 | 53.8K |
| TorchTitan | 77.9 | 91 | 111.8K | |
| PithTrain | 27.7 | 57 | 32.4K | |
| MoE++ | Megatron-LM | 58.7 | 145 | 117.0K |
| TorchTitan | 51.9 | 87 | 85.3K | |
| PithTrain | 39.9 | 90 | 107.7K |
PithTrain uses the least GPU time on all four (up to 44% less than Megatron-LM and 64% less than TorchTitan), and on the hardest one, DynMoE, it takes 62% fewer turns than Megatron-LM. Most of the difference comes down to where a failure surfaces. On PithTrain, a crash tends to land in the file the agent just edited, as a Python traceback that points at the line, so the fix stays local. On the larger frameworks, failures more often surface away from the edit: a CLI flag the agent adds collides with one derived elsewhere in the system, or an error originates inside a compiled kernel and arrives without a Python line to anchor on. Each of those costs the agent extra turns to localize before it can fix anything, and across a debug loop that accounts for most of the gap.
We watched this play out turn by turn on the MoBA port. Editing dominates the token budget everywhere, but PithTrain’s edits are far smaller (4.7K tokens, vs. 13.1K and 22.2K), and it spends a fraction as much just exploring (2.2K vs. Megatron-LM’s 10.2K): there’s simply less code to read to find the right edit and to make sense of a traceback. And with less to read each turn, PithTrain’s per-turn context stays low across the whole session while the larger frameworks climb.

Across the three categories, the same agent gets the work done with less effort on PithTrain: fewer turns, less GPU time, fewer output tokens, with the occasional metric going the other way. Full per-task numbers and an on/off skills ablation (turns drop ~70% on the tasks they target) are in the paper.
Try it
Production frameworks earned their peak throughput and broad coverage over years, and they aren’t going anywhere. But as coding agents take on more of the work of evolving these systems, a second axis starts to matter as much as throughput: how cheaply an agent can understand, operate, and extend them. PithTrain is a demonstration that you don’t have to pick. In ~11K lines of Python, built on four agent-native principles, it matches production-grade training throughput while substantially lowering what an agent spends to work with it.
And it isn’t only for agents: because you can read the whole system end-to-end, PithTrain is a good way to learn how MoE training works, or to try out an idea without fighting the framework. It’s open source, and we’d love your feedback, issues, and contributions.
git clone https://github.com/mlc-ai/pith-train && cd pith-train && uv sync
bash examples/tokenize_corpus/launch.sh dclm-qwen3
bash examples/pretrain_lm/launch.sh qwen3-30b-a3b
- GitHub: github.com/mlc-ai/pith-train
- Paper: arxiv.org/abs/2605.31463
Acknowledgements
PithTrain is developed by contributors from CMU. It is built on top of DeepSeek’s DualPipe, which provides the original pipeline parallelism schedule and examples. We thank the CMU Foundation and Language Model (FLAME) Center for providing the compute resources to develop PithTrain. We also acknowledge the support of DGX B200 from NVIDIA.
Citation
@misc{pithtrain2026,
title={PithTrain: A Compact and Agent-Native MoE Training System},
author={Ruihang Lai and Hao Kang and Haozhan Tang and Akaash R. Parthasarathy and Zichun Yu and Junru Shao and Todd C. Mowry and Chenyan Xiong and Tianqi Chen},
year={2026},
eprint={2605.31463},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2605.31463},
}